4.使用框架的各种代码示例
框架极其简单并且自由,只有一个boost装饰器的参数学习, 实际上这个章节所有的例子都是调整了一下boost的参数而已。
有一点要说明的是框架的消息中间件的ip 端口 密码 等配置是在你第一次随意运行代码时候,在你当前项目的根目录下生成的 funboost_config.py 按需设置。
所有例子的发布和消费都没必须写在同一个py文件,(除了使用python 自带语言queue),因为是使用中间件解耦的消息,好多人误以为发布和消费必须在同一个python文件。
4.0 框架最重要的@boost装饰器的入参格式说明
4.0.1 老的 @booost 直接传入多个参数方式
以下是老的入参方式: @boost(queue_test_f01', qps=0.2,broker_kind=BrokerEnum.REDIS_ACK_ABLE,)
40.0版本之前是老的入参方式,直接在@booost传很多个参数,40.0版本之后你仍然可以这么传参,但是不太推荐,因为不能代码补全函数入参了.
4.0.2 新的@ boost 只传入一个 pydantic Model BoostParams 类型或子类 的入参
新的@ boost 只传入一个 BoostParams 类型或子类 的入参 ,入参类型是 非常流行的 pydantic包的 model类型.
@boost(BoosterParams(queue_name='queue_test_f01', qps=0.2,broker_kind=BrokerEnum.REDIS_ACK_ABLE,))
因为采用pydantic,可以在框架开发时候,减少很多一大推重复入参声明,因为作者很注重代码补全, 作者不想直接 *args **kwargs暴露给用户,这种会导致用户不知道应该传参什么,pycharm也无法补全,所以需要大量重复的声明,每次加入参,都需要很多地方去修改, 所以改为使用流行的 pydantic 包来实现入参,fastapi的入参声明就是使用pydantic,非常棒.
4.0.3 pydantic model 的 BoosterParams 的入参pycharm下自动补全
因为BoosterParams这个pydantic model 类没有 __init__(self,一堆参数) ,而是把类变量,转化成实例变量,
所以直接对BoostParams传参是无法代码补全的,需要用户在pycharm的Plugins安装一个pydantic的插件,这样就能敲击入参自动补全入参名字了.
pydatinc pycharm编程代码补全,请安装 pydantic插件, 在pycharm的 file -> settings -> Plugins -> 输入 pydantic 搜索,
点击安装 pydantic 插件.
4.0.4 关于很多funboost 例子的@boost 使用直接入参,没有使用 pydantic Model类型的BoostParams
因为是兼容老的写法的,老的直接入参仍然可以正常运行,所以例子中没有修改成 @boost(BoosterParams(...)) 入参方式, 用户知道就行.
4.0.5 自定义子类继承 BoosterParams,使得每次少传参
import logging
import time
from funboost import boost, BrokerEnum, BoosterParams
class BoosterParamsMy(BoosterParams): # 传这个类就可以少每次都亲自指定使用rabbitmq作为消息队列,和重试改为4次,和消费发布日志写入自定义.log文件。
broker_kind : str = BrokerEnum.RABBITMQ
max_retry_times : int =4
log_level :int = logging.DEBUG
log_filename : str ='自定义.log'
@boost(boost_params=BoosterParamsMy(queue_name='task_queue_name1d', qps=3,))
def task_fun(x, y):
print(f'{x} + {y} = {x + y}')
time.sleep(3) # 框架会自动并发绕开这个阻塞,无论函数内部随机耗时多久都能自动调节并发达到每秒运行 3 次 这个 task_fun 函数的目的。
@boost(boost_params=BoosterParamsMy(queue_name='task_queue_name1d', qps=10,))
def task_fun2(x, y):
print(f'{x} - {y} = {x - y}')
time.sleep(3) # 框架会自动并发绕开这个阻塞,无论函数内部随机耗时多久都能自动调节并发达到每秒运行 10 次 这个 task_fun 函数的目的。
if __name__ == "__main__":
task_fun.consume() # 消费者启动循环调度并发消费任务
task_fun2.consume()
for i in range(10):
task_fun.push(i, y=i * 2) # 发布者发布任务
task_fun2.push(i,i*10)
4.1 装饰器方式调度函数
from funboost import boost, BrokerEnum,BoosterParams
# qps可以指定每秒运行多少次,可以设置0.001到10000随意。
# broker_kind 指定使用什么中间件,如果用redis,就需要在 funboost_config.py 设置redis相关的配置。
@boost(BoosterParams(queue_name='queue_test_f01', qps=0.2,
broker_kind=BrokerEnum.REDIS_ACK_ABLE,)) # qps 0.2表示每5秒运行一次函数,broker_kind=2表示使用redis作中间件。
def add(a, b):
print(a + b)
if __name__ == '__main__':
for i in range(10, 20):
add.pub(dict(a=i, b=i * 2)) # 使用add.pub 发布任务
add.push(i, b=i * 2) # 使用add.push 发布任务
add.consume() # 使用add.consume 消费任务
# add.multi_process_consume(4) # 这是开启4进程 叠加 细粒度(协程/线程)并发,速度更强。
4.2a 非装饰器调度函数,方式一,(非常不推荐直接用get_consumer写代码,这样跳过了一些步骤,应该推荐用4.2c方式)
有的人动态生成消费者,queue_name或者其他装饰器入参是动态的,无法在代码里面提前写死。可以这样。
最开始框架就没有装饰器,一开始是这么使用的get_consumer,利用工厂模式生成不同中间件类型的消费者。这个更接近本质使用。
boost装饰器使用方式是在后来时候才设计加上的。
from funboost import get_consumer, BrokerEnum,BoosterParams
def add(a, b):
print(a + b)
# 非装饰器方式,多了一个入参,需要手动指定consuming_function入参的值。
consumer = get_consumer(BoosterParams(queue_name='queue_test_f01', consuming_function=add, qps=0.2, broker_kind=BrokerEnum.REDIS_ACK_ABLE))
if __name__ == '__main__':
for i in range(10, 20):
consumer.publisher_of_same_queue.publish(dict(a=i, b=i * 2)) # consumer.publisher_of_same_queue.publish 发布任务
consumer.start_consuming_message() # 使用consumer.start_consuming_message 消费任务
4.2b 非装饰器调度函数,方式二,(非装饰器使用,这是装饰器的本质用法)
只要python装饰器基础知识本质 掌握得好,这种就能想得出来。
这种不是框架实现的方式,是装饰器本质就是这样的。
建议这样做写,这样和装饰器方式的文档演示的 使用方式更加的一致。
from funboost import boost,Booster,ConcurrentModeEnum,BoosterParams
def add(a, b):
print(a + b)
# deco(a=100)(f)(x=1,y=2)的结果 和f被deco(100)装饰 然后f(x=1,y=2)效果是一样的,这是装饰器基本本质,这里不展开啰嗦了。
add_boost = boost(BoosterParams(queue_name='queue_test_f01b', qps=0.2,concurrent_mode= ConcurrentModeEnum.THREADING))(add) # type: Booster
if __name__ == '__main__':
for i in range(10, 20):
add_boost.push(a=i, b=i * 2) # consumer.publisher_of_same_queue.publish 发布任务
add_boost.consume() # 当前进程内启动消费,多线程消费
add_boost.multi_process_consume(2) # 启动单独的2个进程叠加多线程并发
4.2c 在函数内部无限次按照队列名动态生成booster(消费者、生产者) (非装饰器)
BoostersManager.build_booster 方法。
用法: booster = BoostersManager.build_booster(BoosterParams(queue_name=queue_name, qps=0.2, consuming_function=add))
1)如果是在函数内部按照不同的queue_name无限次动态生成booster,不能按照以下写代码
from funboost import boost,Booster,ConcurrentModeEnum,BoosterParams
def add(a, b):
print(a + b)
def my_push(quue_name,a,b):
booster = boost(BoosterParams(queue_name=quue_name, qps=0.2,concurrent_mode= ConcurrentModeEnum.THREADING))(add) # type: Booster
# 上面这行代码太惨了,在push函数里面无数次创建生产者、消费者和消息队列连接,造成cpu 内存和消息队列服务端压力巨大。
booster.push(a,b)
for i in range(1000000):
queue_namx = f'queue_{i%10}'
my_push(queue_namx,i,i*2)
看到有的人这样写代码,这样太惨了,会使python内存和cpu高,会对消息队列服务器产生巨大压力。调用100万次push函数,生成100万次消费者 生产者,对消息队列中间件创建100万次连接。
这样写代码太惨了,会发生悲剧。
4.2b的代码例子是在全局变量里面只生成了一次booster,性能没问题。而上面这个代码是在push函数里面实例化100万次 Consumer和Publisher,太悲催了。
如果你需要动态按照队列名生成生产者消费者,根据入参发布到不同的队列名中,可以自己写个字典判断队列名对应的booster有没有创建过,也可以使用框架提供的 build_booster 函数。
2)如果是在函数内部无限次动态生成booster,应该使用 BoostersManager.build_booster
build_booster 是创建或者直接从全局变量字典中获取booster对象。
如果当前进程没有这个queue_name对应的booster对象就创建,有则直接使用已创建的booster对象。
下面假设动态生成10个队列名的booster对象,发布100万次消息不需要对消息队列中间件创建100万次连接。
from funboost import Booster, BoostersManager,BoosterParams
def add(a, b):
print(a + b)
def my_push(queue_name, a, b):
booster = BoostersManager.build_booster(BoosterParams(queue_name=queue_name, qps=0.2, consuming_function=add)) # type: Booster
# build_booster 这种就不会无数次去创建 消息队列连接了。有则直接使用,没有则创建。
booster.push(a, b)
if __name__ == '__main__':
for i in range(1000000):
queue_namex = f'queue_{i % 10}' # 动态的发布消息到 queue_0 queue_1 queue_2 queue_3 .... queue_9 队列中。
my_push(queue_namex, i, i * 2)
for j in range(10): # 启动 queue_0 queue_1 queue_2 queue_3 .... queue_9 队列的消费者进行消费。
booster = BoostersManager.build_booster(BoosterParams(queue_name=f'queue_{j}', qps=0.2,
consuming_function=add)) # type: Booster
booster.consume()
4.2d 框架的 BoostersManager boosters管理介绍
所有@boost的或者 BoostersManager.build_booster 创建的booster都会登记到 BoostersManager.pid_queue_name__booster_map这里来
用户可以看到声明了哪些队列名
BoosterDiscovery.auto_discovery() 可以扫描python文件夹自动导入模块,找到@boost函数
BoostersManager.get_or_create_booster_by_queue_name 可以根据队列名创建或者获得booster
4.2d.2 使用 BoostersManager 一次性启动所有队列消费,
(无需亲自 fun1.consume() fun2.consume() fun100.consume())
假设:
代码文件夹结构如下:
具体完整代码可见: https://github.com/ydf0509/funboost/tree/master/test_frame/test_boosters_manager
mod1.py和mod2.py 文件一共有3个消费函数,如果用户不想亲自使用如下方式按需一个个函数的亲自启动消费,而是想粗暴的启动所有消费函数.那么可以使用 BoostersManager的 consume_all 或者 BoostersManager.m_consume_all(3) 这样启动.
mod1.fun1.consume()
mod2.fun2a.consume()
mod2.fun2b.consume()
from pathlib import Path
import queue_names
from funboost import BoostersManager, BoosterDiscovery
# import mod1, mod2 # 这个是必须导入的,可以不用,但必须导入,这样BoostersManager才能知道相关模块中的@boost装饰器,或者用下面的 BoosterDiscovery.auto_discovery()来自动导入m1和m2模块.
if __name__ == '__main__':
""" 有的人不想这样写代码,一个个的函数亲自 .consume() 来启动消费,可以使用BoostersManager相关的方法来启动某些队列或者启动所有队列.
mod1.fun1.consume()
mod2.fun2a.consume()
mod2.fun2b.consume()
"""
BoosterDiscovery(project_root_path=Path(__file__).parent.parent.parent, booster_dirs=[Path(__file__).parent]).auto_discovery() # 这个放在main里面运行,防止无限懵逼死循环
# 选择启动哪些队列名消费
# BoostersManager.consume(queue_names.q_test_queue_manager1,queue_names.q_test_queue_manager2a)
# 选择启动哪些队列名消费,每个队列设置不同的消费进程数量
# BoostersManager.m_consume(**{queue_names.q_test_queue_manager1: 2, queue_names.q_test_queue_manager2a: 3})
# 启动所有队列名消费,在同一个进程内消费
BoostersManager.consume_all()
# 启动所有队列名消费,每个队列启动单独的n个进程消费
# BoostersManager.m_consume_all(2)
4.3a 演示如何解决多个步骤的消费函数
看这个例子,step1函数中不仅可以给step2发布任务,也可以给step1自身发布任务。
qps规定了step1每2秒执行一次,step2每秒执行3次。
import time
from funboost import boost, BrokerEnum,BoosterParams
@boost(BoosterParams(queue_name='queue_test_step1', qps=0.5, broker_kind=BrokerEnum.LOCAL_PYTHON_QUEUE))
def step1(x):
print(f'x 的值是 {x}')
if x == 0:
for i in range(1, 300):
step1.pub(dict(x=x + i))
for j in range(10):
step2.push(x * 100 + j) # push是直接发送多个参数,pub是发布一个字典
time.sleep(10)
@boost(BoosterParams(queue_name='queue_test_step2', qps=3, broker_kind=BrokerEnum.LOCAL_PYTHON_QUEUE))
def step2(y):
print(f'y 的值是 {y}')
time.sleep(10)
if __name__ == '__main__':
# step1.clear()
step1.push(0) # 给step1的队列推送任务。
step1.consume() # 可以连续启动两个消费者,因为conusme是启动独立线程里面while 1调度的,不会阻塞主线程,所以可以连续运行多个启动消费。
step2.consume()
4.3.b 演示多个函数消费者使用同一个线程池
from funboost import boost
from funboost.concurrent_pool.custom_threadpool_executor import ThreadPoolExecutorShrinkAble
from funboost.concurrent_pool.custom_gevent_pool_executor import GeventPoolExecutor
"""
这个是演示多个不同的函数消费者,使用同一个全局的并发池。
如果一次性启动的函数过多,使用这种方式避免每个消费者创建各自的并发池,减少线程/协程资源浪费。
"""
# 总共那个有5种并发池,用户随便选。
pool = ThreadPoolExecutorShrinkAble(300) # 指定多个消费者使用同一个线程池,
# pool = GeventPoolExecutor(200)
@boost('test_f1_queue', specify_concurrent_pool=pool, qps=3)
def f1(x):
print(f'x : {x}')
@boost('test_f2_queue', specify_concurrent_pool=pool, qps=2)
def f2(y):
print(f'y : {y}')
@boost('test_f3_queue', specify_concurrent_pool=pool, )
def f3(m, n):
print(f'm : {m} , n : {n}')
if __name__ == '__main__':
for i in range(1000):
f1.push(i)
f2.push(i)
f3.push(i, 1 * 2)
f1.consume()
f2.consume()
f3.consume()
4.3c 演示清空消息队列和获取消息队列中的消息数量
f2.clear() 清空消息队列
f2.get_message_count() 获取消息队中的消息数量,
不能使用 f2.get_message_count() =0 来判断消息队列没任务了以为该函数的所有消息被消费完成了,本地内存队列存储了
一部分消息和正在执行的也有一部分消息,如果要判断消费完成了,应该使用4.17章节的 判断函数运行完所有任务,再执行后续操作。
@boost('test_queue77g', log_level=10, broker_kind=BrokerEnum.REDIS_ACK_ABLE, qps=5,
create_logger_file=False,is_show_message_get_from_broker=True,concurrent_mode=ConcurrentModeEnum.SINGLE_THREAD
# specify_concurrent_pool= pool2,
# concurrent_mode=ConcurrentModeEnum.SINGLE_THREAD, concurrent_num=3,is_send_consumer_hearbeat_to_redis=True,function_timeout=10,
# function_result_status_persistance_conf=FunctionResultStatusPersistanceConfig(True,True)
)
def f2(a, b):
time.sleep(10)
print(a, b)
return a - b
if __name__ == '__main__':
f2.clear()
for i in range(8):
f2.push(i, i * 5)
print(f2.get_message_count())
f2.clear()
for i in range(20):
f2.push(i, i * 2)
print(f2.get_message_count())
4.4 演示如何定时运行。
定时运行消费演示,定时方式入参用法可以百度 apscheduler 定时包。
定时的语法和入参与本框架无关系,不是本框架发明的定时语法,具体的需要学习 apscheduler包。
funboost中的定时任务原理是:
使用apscheduler包定时的执行消费函数的push方法,也就是实际上是定时的发布任务到消息队列,只要定时发布任务到消息队列,就能定时消费了(前提是消费能力强,队列消息没有堆积)。
这个设计方式,在我看了dramatiq的文档后,发现和dramatiq的定时方案是一样的思维,与其说是定时的执行消费函数,不如说是定时的发布消息到队列中。
启动消费任务的脚本:
from funboost import boost, BrokerEnum
@boost('queue_test_666', broker_kind=BrokerEnum.REDIS)
def consume_func(x, y):
print(f'{x} + {y} = {x + y}')
if __name__ == '__main__':
consume_func.consume()
定时触发函数发布消息到消息队列的脚本(启动定时和启动消费也可以在同一个脚本中启动的,文档这里是分开启动了)
from funboost import funboost_aps_scheduler
from test_frame.test_timing.test_timming import consume_func
funboost_aps_scheduler.start()
funboost_aps_scheduler.add_push_job(consume_func, 'interval', id='3_second_job', seconds=3, kwargs={"x": 5, "y": 6}) # 每隔3秒发布一次任务,自然就能每隔3秒消费一次任务了。
python3.9及以上 定时任务报错 RuntimeError: cannot schedule new futures after interpreter shutdown 我们是需要使得主线程其他任务不结束, 看10.2章节文档,在你脚本的最后一行加个 while 1: time.sleep(100) , 阻止主线程退出就好了。
4.4.b 演示如何跨解释器、机器,动态添加、修改、删除、查看定时任务(修改定时配置,不用重启python定时器脚本)。
有人老是问funboost支不支持动态修改 添加定时任务(修改定时配置,不用重启python定时器脚本),这个和funboost毫无关系其实,是apscheduler包的功能。
apscheduler需要指定 job_stores 为redis /mysql(sqlachemy)/ mongo 作为持久化,才能动态增删改查定时任务配置,为什么要配置数据库这个很容易理解吧。
提前要说的是,以下这些用法都是apscheduler三方包的方法,与funboost毫无关系,funboost没有创造新的定时语法来增加学习负担。
以下两个脚本单独部署运行,一个执行脚本触发定时任务发送消息,一个脚本负责添加、修改、删除定时任务的配置,
1)test_frame/test_apschedual/test_aps_redis_store.py 文件中执行触发定时任务发送到消息队列。
注意此脚本是开启触发定时任务 apscheduler.start(paused=False)
import apscheduler.jobstores.base
import nb_log
from funboost import boost, BrokerEnum
from funboost.timing_job.apscheduler_use_redis_store import funboost_background_scheduler_redis_store
nb_log.get_logger('apscheduler')
'''
test_frame/test_apschedual/test_aps_redis_store.py
和 test_frame/test_apschedual/test_change_aps_conf.py 搭配测试,动态修改定时任务
test_change_aps_conf.py 中修改定时任务间隔和函数入参,test_aps_redis_store.py定时任务就会自动更新变化。
'''
@boost('queue_test_aps_redis', broker_kind=BrokerEnum.LOCAL_PYTHON_QUEUE)
def consume_func(x, y):
print(f'{x} + {y} = {x + y}')
if __name__ == '__main__':
# funboost_background_scheduler_redis_store.remove_all_jobs() # 删除数据库中所有已配置的定时任务
consume_func.clear()
#
funboost_background_scheduler_redis_store.start(paused=False) # 此脚本是演示不重启的脚本,动态读取新增或删除的定时任务配置,并执行。注意是 paused=False
#
try:
funboost_background_scheduler_redis_store.add_push_job(consume_func,
'interval', id='691', name='namexx', seconds=5,
kwargs={"x": 7, "y": 8},
replace_existing=False) # 如果 replace_existing=False 就需要捕获重复添加已存在的id错误
except apscheduler.jobstores.base.ConflictingIdError as e:
print('定时任务id已存在: {e}')
consume_func.consume()
2)test_frame/test_apschedual/test_add_aps_conf.py 脚本演示修改定时任务配置,从而影响到test_aps_redis_store脚本的定时任务变更(演示了定时间隔变化和入参变化)。
注意此脚本是关闭触发定时任务 apscheduler.start(paused=True),因为此脚本是只负责修改 添加定时任务。不然此脚本和上面的脚本都执行定时任务那就不是我们想要的目的了。
下面这个一般就是在web服务接口中调用增删改查定时任务。我这里就不演示web接口了。web中只负责修改添加定时任务,让执行定时发布消息的任务在上面的test_aps_redis_store.py 脚本中和funboost消费一起启动
from funboost.timing_job.apscheduler_use_redis_store import funboost_background_scheduler_redis_store
from test_frame.test_apschedual.test_aps_redis_store import consume_func
"""
此文件是测试修改定时任务配置,另一个脚本的一启动的定时任务配置,会自动发生变化。因为定时任务配置通过中间件存储和通知了。
"""
# 修改或添加定时任务必须执行.start,值修改配置但不想执行函数,就设置paused=True
funboost_background_scheduler_redis_store.start(paused=True) # 此脚本是演示远程动态修改的脚本,动态新增或删除定时任务配置,但不执行定时任务执行。注意是 paused=True
# 查看数据库中的所有定时任务配置
print(funboost_background_scheduler_redis_store.get_jobs())
# 删除数据库中所有已添加的定时任务配置
# funboost_background_scheduler_redis_store.remove_all_jobs()
# 删除数据库中已添加的id为691的定时任务配置
# funboost_background_scheduler_redis_store.remove_job(job_id='691')
# 增加或修改定时任务配置 replace_existing=True 就是如果id已存在就修改,不存在则添加。
funboost_background_scheduler_redis_store.add_push_job(consume_func,
'interval', id='15', name='namexx', seconds=4,
kwargs={"x": 19, "y": 33},
replace_existing=True)
4.4.c funboost_scheduler.add_push_job(consume_func) 和 funboost_scheduler.add_job(consume_func.push) 的区别?
文档说funboost的定时语法是apscheduler三方包的原生语法,为什么加了一个 add_push_job 方法?
因为考虑到有人需要使用动态删除 新增定时任务,那么scheduler的job_store 必须选择数据库类型,而不是使用默认的内存类型。
如果选择数据库来持久化定时任务配置,那么定时任务涉及的函数和入参必须是能够pickle序列化的,funboost的消费函数的 consumer和publisher都有threading.Lock()成员变量,
threading.Lock()无法pickle序列化,所以不能使用 funboost_scheduler.add_job(consume_func.push) 方式来添加定时任务配置到数据库中。
所以funboost的apscheduler增加了add_push_job 方法,该方法是调用原生add_job,函数是传递 _add_push_job,_add_push_job中通过队列名再获取消费者/发布者,
这样就使apscheduler的原生的add_job避开了传递不可pickle序列化的consume_func.push方法。
add_push_job 的其他入参和 原生的 add_job 的入参语法一摸一样,学习负担不大。
4.5 多进程并发 + 多线程/协程,代码例子。
ff.multi_process_start(2) 就是代表启动2个独立进程并发 + 叠加 asyncio、gevent、eventlet、threding 、single_thread 细粒度并发,
例如fun函数加上@boost(concurrent_num=200),fun.multi_process_start(16) ,这样16进程叠加每个进程内部开200线程/协程,运行性能炸裂。
多进程消费
import time
from funboost import boost, BrokerEnum, PriorityConsumingControlConfig
"""
演示多进程启动消费,多进程和 asyncio/threading/gevnt/evntlet是叠加关系,不是平行的关系。
"""
# qps=5,is_using_distributed_frequency_control=True 分布式控频每秒执行5次。
# 如果is_using_distributed_frequency_control不设置为True,默认每个进程都会每秒执行5次。
@boost('test_queue', broker_kind=BrokerEnum.REDIS, qps=5, is_using_distributed_frequency_control=True)
def ff(x, y):
import os
time.sleep(2)
print(os.getpid(), x, y)
if __name__ == '__main__':
ff.clear() # 清除
# ff.publish()
for i in range(1000):
ff.push(i, y=i * 2)
# 这个与push相比是复杂的发布,第一个参数是函数本身的入参字典,后面的参数为任务控制参数,例如可以设置task_id,设置延时任务,设置是否使用rpc模式等。
ff.publish({'x': i * 10, 'y': i * 2}, priority_control_config=PriorityConsumingControlConfig(countdown=1, misfire_grace_time=15))
ff(666, 888) # 直接运行函数
ff.start() # 和 conusme()等效
ff.consume() # 和 start()等效
ff.multi_process_start(2) # 启动两个进程,
4.6 演示rpc模式,即客户端调用远程函数并及时得到结果。
如果在发布端要获取消费端的执行结果,有两种方式
1、需要在@boost设置is_using_rpc_mode=True,默认是False不会得到结果。
2、如果@boost没有指定,也可以在发布任务的时候,用publish方法并写上
priority_control_config=PriorityConsumingControlConfig(is_using_rpc_mode=True)
用这个功能必须在funboost_config.py配置文件中配置好redis链接,
无论你使用 redis kafka rabbitmq 还是 sqlite 等 作为中间件,想用rpc功能就必须配置好redis连接。
4.6.1 rpc 消费端执行两数求
远程服务端脚本,执行求和逻辑。 test_frame\test_rpc\test_consume.py
import time
from funboost import boost, BrokerEnum
@boost('test_rpc_queue', is_using_rpc_mode=True, broker_kind=BrokerEnum.REDIS_ACK_ABLE, concurrent_num=200)
def add(a, b):
time.sleep(3)
return a + b
if __name__ == '__main__':
add.consume()
4.6.2 发布端获取求和的结果
客户端调用脚本,单线程发布阻塞获取两书之和的结果,执行求和过程是在服务端。 test_frame\test_rpc\test_publish.py
这种方式如果在主线程单线程for循环运行100次,因为为了获取结果,导致需要300秒才能完成100次求和。
客户端获取服务端执行结果脚本
from funboost import PriorityConsumingControlConfig
from test_frame.test_rpc.test_consume import add
for i in range(100):
async_result = add.push(i, i * 2)
print(async_result.result) # 执行 .result是获取函数的运行结果,会阻塞当前发布消息的线程直到函数运行完成。
# 如果add函数的@boost装饰器参数没有设置 is_using_rpc_mode=True,则在发布时候也可以指定使用rpc模式。
async_result = add.publish(dict(a=i * 10, b=i * 20), priority_control_config=
PriorityConsumingControlConfig(is_using_rpc_mode=True))
print(async_result.status_and_result)
4.6.2b 发布端获取求和的结果,在线程池中进一步处理结果
上面方式中是在单线程环境下阻塞的一个接一个打印结果。如果想快速并发处理结果,可以自己手动在多线程或线程池处理结果。 框架也提供一个设置回调函数,自动在线程池中处理回调结果,回调函数有且只有一个入参,表示函数运行结果及状态。
如下脚本则不需要300秒运行完成只需要3秒即可,会自动在并发池中处理结果。
from funboost import PriorityConsumingControlConfig
from test_frame.test_rpc.test_consume import add
def show_result(status_and_result: dict):
"""
:param status_and_result: 一个字典包括了函数入参、函数结果、函数是否运行成功、函数运行异常类型
"""
print(status_and_result)
for i in range(100):
async_result = add.push(i, i * 2)
# print(async_result.result) # 执行 .result是获取函数的运行结果,会阻塞当前发布消息的线程直到函数运行完成。
async_result.set_callback(show_result) # 使用回调函数在线程池中并发的运行函数结果
4.6.3 手动设置rpc结果最大等待时间
手动设置rpc结果最大等待时间,不使用默认的120秒等待时间。
上面的求和例子是耗时3秒,所以只要任务不在消息队列积压,120秒内可以获取到结果。如果上面的求和函数耗时600秒,120秒内就获取不到结果了。
可以手动设置异步结果最大的等待时间,.set_timeout(3600) 就是最大等待1小时了。
async_result = add.push(i, i * 2)
async_result.set_timeout(3600)
这样设置后,就是为了获得消费结果,最大等待3600秒。
默认是最大等待120秒返回结果,如果消费函数本身耗时就需要消耗很长的时间,可以适当扩大这个时间。
4.6.4 为什么获取不到执行结果?
首先要检查 有没有设置 is_using_rpc_mode=True ,默认是不使用这个模式的,没有设置为True就不可能得到执行结果。
默认为等待结果最大120秒,如果你的函数耗时本来就很大或者消息队列有大量积压,需要按4.6.3 调大最大等等时间
4.6.5 asyncio 语法生态下rpc获取执行结果。
因为 async_result= fun.push() ,默认返回的是 AsyncResult 类型对象,里面的方法都是同步语法。
async_result.result 是一个耗时的函数, 解释一下result, 是property装饰的所以不用 async_result.result()
有的人直接在async def 的异步函数里面 print (async_result.result),如果消费函数消费需要耗时5秒,
那么意味rpc获取结果至少需要5秒才能返回,你这样写代码会发生灭顶之灾,asyncio生态流程里面一旦异步需要处处异步。
所以新增了 AioAsyncResult 类,和用户本来的asyncio编程生态更好的搭配。
服务端求和脚本还是4.6.1 两数求和不变,这里演示asyncio生态下的获取rpc结果脚本
import asyncio
from funboost import AioAsyncResult
from test_frame.test_rpc.test_consume import add
async def process_result(status_and_result: dict):
"""
:param status_and_result: 一个字典包括了函数入参、函数结果、函数是否运行成功、函数运行异常类型
"""
await asyncio.sleep(1)
print(status_and_result)
async def test_get_result(i):
async_result = add.push(i, i * 2)
aio_async_result = AioAsyncResult(task_id=async_result.task_id) # 这里要使用asyncio语法的类,更方便的配合asyncio异步编程生态
print(await aio_async_result.result) # 注意这里有个await,如果不await就是打印一个协程对象,不会得到结果。这是asyncio的基本语法,需要用户精通asyncio。
print(await aio_async_result.status_and_result)
await aio_async_result.set_callback(process_result) # 你也可以编排任务到loop中
if __name__ == '__main__':
loop = asyncio.get_event_loop()
for j in range(100):
loop.create_task(test_get_result(j))
loop.run_forever()
async_result = add.push(i, i * 2)
async_result 的类型是AsyncResult,是同步场景下的类。这个Async不是指的asyncio语法异步,是生产者消费者模式整体大的概念上的异步,不是指的python asyncio语法异步。
aio_async_result = AioAsyncResult(task_id=async_result.task_id) ,这个是asyncio语法类AioAsyncResult,这个类里面的耗时io的方法全都是async def的,
这种更好的配合用户当前已经是 asyncio 编程生态。因为在asyncio编程生态中,在一个loop里面,要全部异步,只要一个是同步阻塞的方法,整个loop中其他协程任务完了个蛋,
也就是常说的一旦异步要处处异步,不要在一串流程中一会儿调用asyncio的耗时函数,一会调用同步耗时函数,这样是个悲剧,懂的都懂这句话。
4.6.7 从mongo中获取函数执行结果
首先 boost装饰器中设置函数状态结果持久化后,会保存函数的状态和结果到mongodb中。
function_result_status_persistance_conf=FunctionResultStatusPersistanceConfig(is_save_status=True,is_save_result=True,expire_seconds=500000)
使用 ResultFromMongo 类获取函数结果
# 以非等待方式获取mongo中函数的结果。
import time
from funboost import ResultFromMongo
async_result = add.push(10, 20)
task_id = async_result.task_id
time.sleep(2)
print(ResultFromMongo(task_id).get_status_and_result())
print(ResultFromMongo('test_queue77h6_result:764a1ba2-14eb-49e2-9209-ac83fc5db1e8').get_status_and_result())
print(ResultFromMongo('test_queue77h6_result:5cdb4386-44cc-452f-97f4-9e5d2882a7c1').get_result())
4.7 演示qps控频
演示框架的qps控频功能
此框架对函数耗时随机波动很大的控频精确度达到96%以上
此框架对耗时恒定的函数控频精确度达到99.9%
在指定rate_limit 超过 20/s 时候,celery对耗时恒定的函数控频精确度60%左右,下面的代码会演示这两个框架的控频精准度对比。
此框架针对不同指定不同qps频次大小的时候做了不同的三种处理方式。 框架的控频是直接基于代码计数,而非使用redis 的incr计数,因为python操作一次redis指令要消耗800行代码左右, 如果所有任务都高频率incr很消耗python脚本的cpu也对redis服务端产生灾难压力。 例如假设有50个不同的函数,分别都要做好几千qps的控频,如果采用incr计数,光是incr指令每秒就要操作10万次redis, 所以如果用redis的incr计数控频就是个灾难,redis incr的计数只适合 1到10大小的qps,不适合 0.01 qps 和 1000 qps这样的任务。 同时此框架也能很方便的达到 5万 qps的目的,装饰器设置qps=50000 和 is_using_distributed_frequency_control=True, 然后只需要部署很多个进程 + 多台机器,框架通过redis统计活跃消费者数量,来自动调节每台机器的qps,框架的分布式控频开销非常十分低, 因为分布式控频使用的仍然不是redis的incr计数,而是基于每个消费者的心跳来统计活跃消费者数量,然后给每个进程分配qps的,依然基于本地代码计数。 例如部署100个进程(如果机器是128核的,一台机器足以,或者20台8核机器也可以) 以20台8核机器为例子,如果把机器减少到15台或增加机器到30台,随便减少部署的机器数量或者随便增加机器的数量, 代码都不需要做任何改动和重新部署,框架能够自动调节来保持持续5万次每秒来执行函数,不用担心部署多了30台机器,实际运行qps就变成了10几万。 (前提是不要把机器减少到10台以下,因为这里假设这个函数是一个稍微耗cpu耗时的函数,要保证所有资源硬件加起来有实力支撑5万次每秒执行函数) 每台机器都运行 test_fun.multi_process_conusme(8),只要10台以上1000台以下随意随时随地增大减小运行机器数量, 代码不需要做任何修改变化,就能很方便的达到每秒运行5万次函数的目的。
4.7.1 演示qps控频和自适应扩大和减小并发数量。
通过不同的时间观察控制台,可以发现无论f2这个函数需要耗时多久(无论是函数耗时需要远小于1秒还是远大于1秒),框架都能精确控制每秒刚好运行2次。
当函数耗时很小的时候,只需要很少的线程就能自动控制函数每秒运行2次。
当函数突然需要耗时很大的时候,智能线程池会自动启动更多的线程来达到每秒运行2次的目的。
当函数耗时从需要耗时很大变成只需要耗时很小的时候,智能线程池会自动缩小线程数量。
总之是围绕qps恒定,会自动变幻线程数量,做到既不多开浪费cpu切换,也不少开造成执行速度慢。
import time
import threading
from funboost import boost, BrokerEnum, ConcurrentModeEnum
t_start = time.time()
@boost('queue_test2_qps', qps=2, broker_kind=BrokerEnum.PERSISTQUEUE, concurrent_mode=ConcurrentModeEnum.THREADING,
concurrent_num=600)
def f2(a, b):
"""
这个例子是测试函数耗时是动态变化的,这样就不可能通过提前设置参数预估函数固定耗时和搞鬼了。看看能不能实现qps稳定和线程池自动扩大自动缩小
要说明的是打印的线程数量也包含了框架启动时候几个其他的线程,所以数量不是刚好和所需的线程计算一样的。
"""
result = a + b
sleep_time = 0.01
if time.time() - t_start > 60: # 先测试函数耗时慢慢变大了,框架能不能按需自动增大线程数量
sleep_time = 7
if time.time() - t_start > 120:
sleep_time = 30
if time.time() - t_start > 240: # 最后把函数耗时又减小,看看框架能不能自动缩小线程数量。
sleep_time = 0.8
if time.time() - t_start > 300:
sleep_time = None
print(
f'{time.strftime("%H:%M:%S")} ,当前线程数量是 {threading.active_count()}, {a} + {b} 的结果是 {result}, sleep {sleep_time} 秒')
if sleep_time is not None:
time.sleep(sleep_time) # 模拟做某事需要阻塞n秒种,必须用并发绕过此阻塞。
return result
if __name__ == '__main__':
f2.clear()
for i in range(1000):
f2.push(i, i * 2)
f2.consume()
4.7.2 此框架对固定耗时的任务,持续控频精确度高于99.9%
4.7.2 此框架对固定耗时的任务,持续控频精确度高于99.9%,远超celery的rate_limit 60%控频的精确度。
对于耗时恒定的函数,此框架精确控频率精确度达到99.9%,celery控频相当不准确,最多到达60%左右,两框架同样是做简单的加法然后sleep0.7秒,都设置500并发100qps。
@boost('test_queue66', broker_kind=BrokerEnum.REDIS, qps=100)
def f(x, y):
print(f''' {int(time.time())} 计算 {x} + {y} = {x + y}''')
time.sleep(0.7)
return x + y
@celery_app.task(name='求和啊', rate_limit='100/s')
def add(a, b):
print(f'{int(time.time())} 计算 {a} + {b} 得到的结果是 {a + b}')
time.sleep(0.7)
return a + b
# 在pycahrm控制台搜索 某一秒的时间戳 + 计算 作为关键字查询,分布式函数调度框架启动5秒后,以后持续每一秒都是100次,未出现过99和101的现象。
在pycahrm控制台搜索 某一秒的时间戳 + 计算 作为关键字查询,celery框架,每一秒求和次数都是飘忽不定的,而且是六十几徘徊,
如果celery能控制到95至105次每秒徘徊波动还能接受,类似现象还有celery设置rate_limit=50/s,实际32次每秒徘徊,
设置rate_limit=30/s,实际18-22次每秒徘徊,可见celery的控频相当差。
设置rate_limit=10/s,实际7-10次每秒徘徊,大部分时候是9次,当rate_limit大于20时候就越来越相差大了,可见celery的控频相当差。
4.7.3 对函数耗时随机性大的控频功能证明
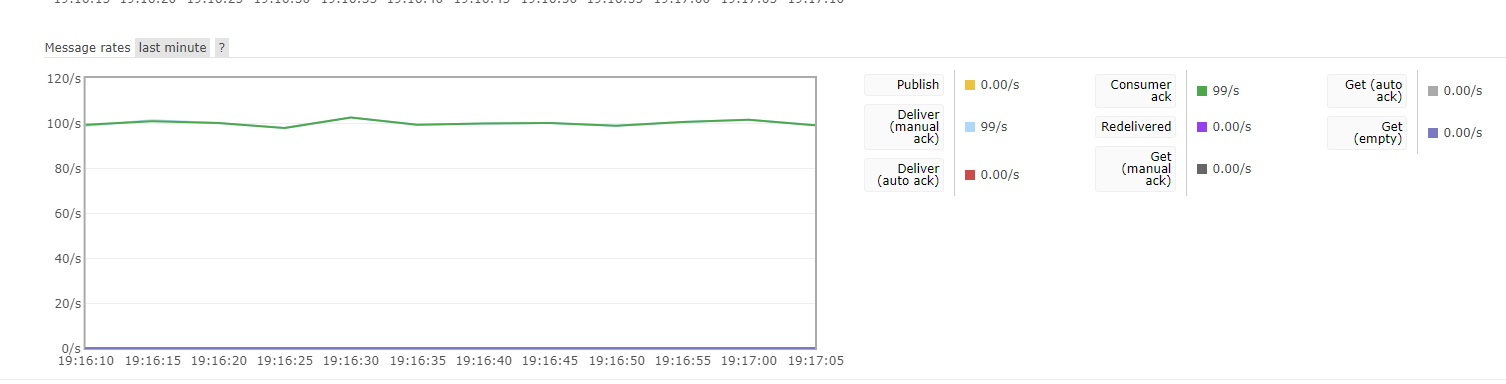
对函数耗时随机性大的控频功能证明,使用外网连接远程broker,持续qps控频。
设置函数的qps为100,来调度需要消耗任意随机时长的函数,能够做到持续精确控频,频率误差小。
如果设置每秒精确运行超过500000次以上的固定频率,前提是cpu够强机器数量多,
设置qps=50000,并指定is_using_distributed_frequency_control=True(只有这样才是分布式全局控频,默认是基于单个进程的控频),。
如果任务不是很重型很耗cpu,此框架单个消费进程可以控制每秒运行次数的qps 从0.01到1000很容易。
当设置qps为0.01时候,指定的是每100秒运行1次,qps为100指的是每一秒运行100次。
import time
import random
from funboost import boost, BrokerEnum
@boost('test_rabbit_queue7', broker_kind=BrokerEnum.RABBITMQ_AMQPSTORM, qps=100, log_level=20)
def test_fun(x):
# time.sleep(2.9)
# sleep时间随机从0.1毫秒到5秒任意徘徊。传统的恒定并发数量的线程池对未知的耗时任务,持续100次每秒的精确控频无能为力。
# 但此框架只要简单设置一个qps就自动达到了这个目的。
random_sleep = random.randrange(1, 50000) / 10000
time.sleep(random_sleep)
print(x, random_sleep)
if __name__ == '__main__':
test_fun.consume()
# test_fun.multi_process_consume(3)
分布式函数调度框架对耗时波动大的函数持续控频曲线
4.7.4 分布式全局控频和单个消费者控频区别
@boost中指定 is_using_distributed_frequency_control=True 则启用分布式全局控频,是跨进程跨python解释器跨服务器的全局控频。
否则是基于当前消费者的控频。
例如 你设置的qps是100,如果你不设置全局控频,run_consume.py 脚本中启动 fun.consume() ,如果你反复启动5次这个 run_consume.py,
如果不设置分布式控频,那么5个独立的脚本运行,频率总共会达到 500次每秒,因为你部署了5个脚本。
同理你如果用 fun.multi_process_consume(4)启动了4个进程消费,那么就是4个消费者,总qps也会达到400次每秒。
这个控频方式是看你需求了。
如果设置了 is_using_distributed_frequency_control=True,那就会使用每个消费者发送到redis的心跳来统计总消费者个数。
如果你部署了2次,那么每个消费者会平分qps,每个消费者是变成50qps,总共100qps。
如果你部署了5次,那么每个消费者会平分qps,每个消费者是变成20qps,总共100qps。
如果你中途关闭2个消费者,变成了3个消费者,每个消费者是变成 33.33qps,总共100qps。(框架qps支持小数,0.1qps表示每10秒执行1次)
4.8 再次说明qps能做什么,qps为什么流弊?常规并发方式无法完成的需求是什么?
以模拟请求一个flask接口为例子,我要求每一秒都持续精确完成8次请求,即控制台每1秒都持续得到8次flask接口返回的hello world结果。
4.8.1 下面讲讲常规并发手段为什么对8qps控频需求无能为力?
不用框架也可以实现8并发, 例如Threadpool设置8线程很容易,但不用框架实现8qps不仅难而且烦
虽然
框架能自动实现 单线程 ,多线程, gevent , eventlet ,asyncio ,多进程 并发 ,
多进程 + 单线程 ,多进程 + 多线程,多进程 + gevent, 多进程 + eventlet ,多进程 + asyncio 的组合并发
可以说囊括了python界的一切知名的并发模型,能做到这一点就很方便强大了
但是
此框架还额外能实现qps控频,能够实现函数每秒运行次数的精确控制,我觉得这个功能也很实用,甚至比上面的那些并发用起来还实用。
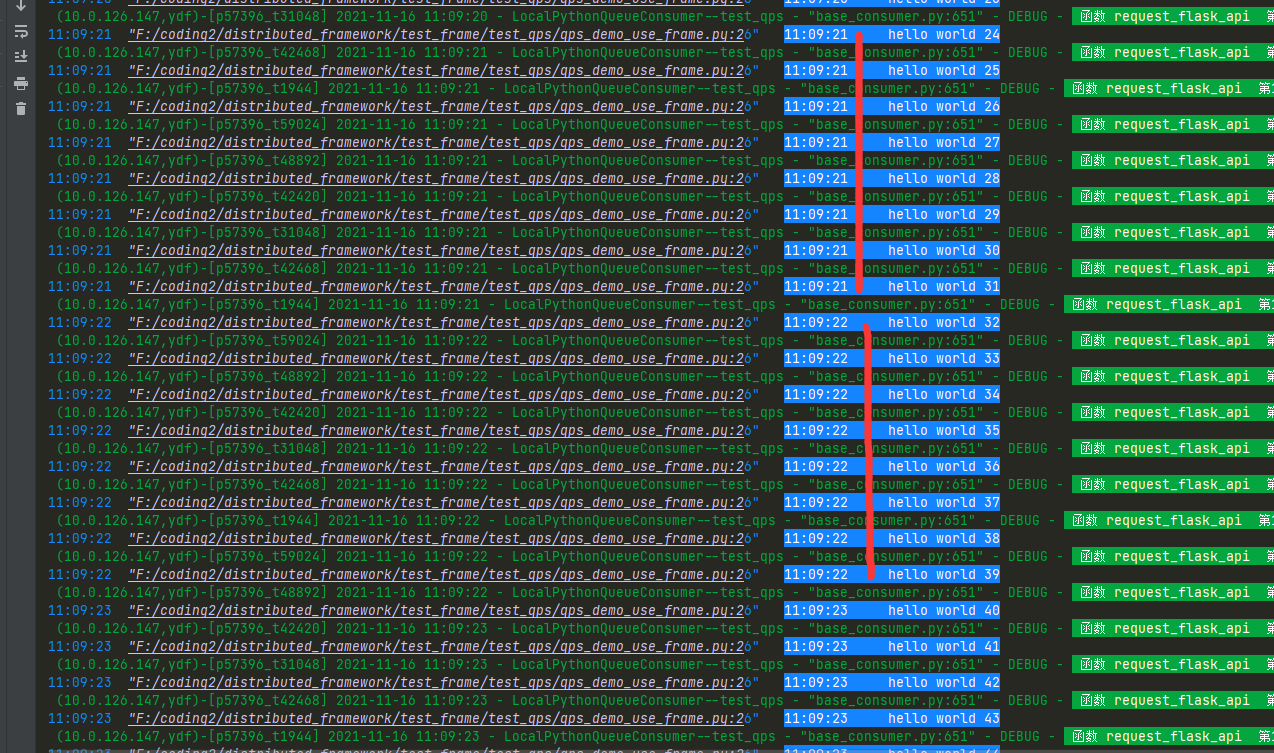
这个代码是模拟常规并发手段无法达到每秒持续精确运行8次函数(请求flask接口8次)的目的。
下面的代码使用8个线程并发运行 request_flask_api 函数,
当flask_veiw_mock 接口耗时0.1秒时候,在python输出控制台可以看到,10秒钟就运行结束了,控制台每秒打印了80次hello world,严重超频10倍了不符合需求
当flask_veiw_mock 接口耗时刚好精确等于1秒时候,在python输出控制台可以看到,100秒钟运行结束了,控制台每秒打印了8次hello world,只有当接口耗时刚好精确等于1秒时候,并发数量才符合qps需求
当flask_veiw_mock 接口耗时10秒时候,在python输出控制台可以看到,需要1000秒钟运行结束,控制台每隔10秒打印8次hello world,严重不符合持续每秒打印8次的目的。
由此可见,用设置并发数量来达到每秒请求8次flask的目的非常困难,99.99%的情况下服务端没那么巧刚好耗时1秒。
天真的人会说根据函数耗时大小,来设置并发数量,这可行吗?
有人会说,为了达到8qps目的,当函数里面sleep 0.1 时候他开1线程,那你这样仍然超频啊,你是每1秒钟打印10次了超过了8次。
当sleep 0.01 时候,为了达到8qps目的,就算你开1线程,那不是每1秒钟打印100次hello?你不会想到开0.08个线程个线程来实现控频吧?
当sleep 10秒时候,为了8qps目的,你开80线程,那这样是控制台每隔10秒打印80次hello,我要求的是控制台每一秒都打印8次hello,没告诉你是每隔10秒打印80次hello吧?还是没达到目的。
如果函数里面是sleep 0.005 0.07 0.09 1.3 2.7 7 11 13这些不规则无法整除的数字?请问你是如何一一计算精确开多少线程来达到8qps的?
如果flask网站接口昨天是3秒的响应时间,今天变成了0.1秒的响应时间,你的线程池数量不做变化,代码不进行重启,请问你如何做到自适应无视请求耗时,一直持续8qps的目的?
固定并发数量大小就是定速巡航不够智能前车减速会撞车,qps自适应控频那就是acc自适应巡航了,自动调整极端智能,压根无需提前测算预估函数需要耗时多久(接口响应耗时多久)。
所以综上所述,如果你有控频需求,你想用并发数量来达到控频目的,那是不可能的。
有些人到现在还没明白并发数量和qps(每秒执行多少次)之间的区别,并发数量只有在函数耗时刚好精确等于1秒时候才等于qps。
```python
import time
from concurrent.futures import ThreadPoolExecutor
def flask_veiw_mock(x):
# time.sleep(0.1) # 通过不同的sleep大小来模拟服务端响应需要消耗的时间
# time.sleep(1) # 通过不同的sleep大小来模拟服务端响应需要消耗的时间
time.sleep(10) # 通过不同的sleep大小来模拟服务端响应需要消耗的时间
return f"hello world {x}"
def request_flask_api(x):
response = flask_veiw_mock(x)
print(time.strftime("%H:%M:%S"), ' ', response)
if __name__ == '__main__':
with ThreadPoolExecutor(8) as pool:
for i in range(800):
pool.submit(request_flask_api,i)
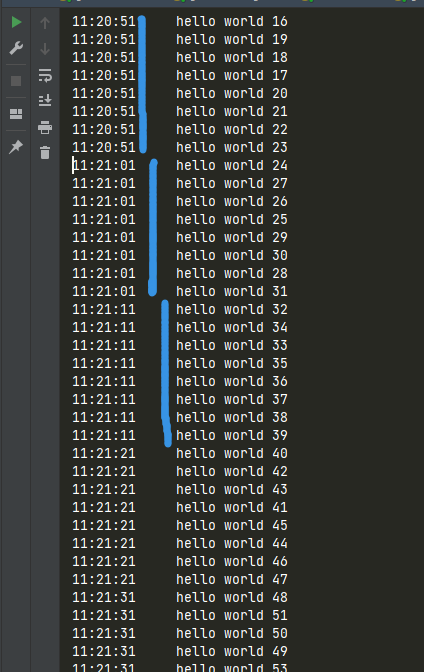
截图是当 flask_veiw_mock 耗时为10秒时候,控制台是每隔10秒打印8次 hello world,没达到每一秒都打印8次的目的
当 flask_veiw_mock 耗时为0.1 秒时候,控制台是每隔1秒打印80次 hello world,没达到每一秒都打印8次的目的
4.8.2 使用分布式函数调度框架,无论接口耗时多少,轻松达到8qps的例子
这个代码是模拟常规并发手段无法达到每秒持续精确运行8次函数(请求flask接口8次)的目的。
但是使用分布式函数调度框架能轻松达到这个目的。
下面的代码使用分部署函数调度框架来调度运行 request_flask_api 函数,
flask_veiw_mock 接口耗时0.1秒时候,控制台每秒打印8次 hello world,非常精确的符合控频目标
flask_veiw_mock 接口耗时1秒时候,控制台每秒打印8次 hello world,非常精确的符合控频目标
flask_veiw_mock 接口耗时10秒时候控,控制台每秒打印8次 hello world,非常精确的符合控频目标
flask_veiw_mock 接口耗时0.001秒时候,控制台每秒打印8次 hello world,非常精确的符合控频目标
flask_veiw_mock 接口耗时50 秒时候,控制台每秒打印8次 hello world,非常精确的符合控频目标
可以发现分布式函数调度框架无视函数耗时大小,都能做到精确控频,常规的线程池 asyncio什么的,面对这种不确定的接口耗时,简直毫无办法。
有些人到现在还没明白并发数量和qps(每秒执行多少次)之间的区别,并发数量只有在函数耗时刚好精确等于1秒时候才等于qps。
import time
from funboost import boost, BrokerEnum
def flask_veiw_mock(x):
time.sleep(0.1) # 通过不同的sleep大小来模拟服务端响应需要消耗的时间
# time.sleep(1) # 通过不同的sleep大小来模拟服务端响应需要消耗的时间
# time.sleep(10) # 通过不同的sleep大小来模拟服务端响应需要消耗的时间
return f"hello world {x}"
@boost("test_qps", broker_kind=BrokerEnum.MEMORY_QUEUE, qps=8)
def request_flask_api(x):
response = flask_veiw_mock(x)
print(time.strftime("%H:%M:%S"), ' ', response)
if __name__ == '__main__':
for i in range(800):
request_flask_api.push(i)
request_flask_api.consume()
从截图可以看出,分布式函数调度框架,控频稳如狗,完全无视flask_veiw_mock耗时是多少。
4.8.3 并发数量和qps(每秒执行多少次)之间的区别
有些人到现在还没明白并发数量和qps(每秒执行多少次)之间的区别,并发数量只有在函数耗时刚好精确等于1秒时候才等于qps。
拿10并发(线程/协程)和10qps 运行10000次函数 举例子,
如果函数耗时 0.1秒,10并发运行10000次,那么是 100秒运行完成
如果函数耗时 1 秒,10并发运行10000次,那么是 1000秒运行完成
如果函数耗时 10 秒,10并发运行10000次,那么是 10000秒运行完成
如果函数耗时 0.1秒,10qps运行10000次,那么是 1000秒运行完成
如果函数耗时 1 秒,10qps运行10000次,那么是 1000秒运行完成
如果函数耗时 10 秒,10qps运行10000次,那么是 1000秒运行完成
并发是恒定同时有多少个线程/协程 在运行函数,不能达到消费速率恒定,除非函数耗时是1秒并且稳定
qps是无视函数耗时多少,总是能在固定的时间内完成所有任务。
qps恒定,前提是电脑cpu能力范围之内,防止有杠精会说他要指定 qps为1千亿,在函数里面每次做一个很大数字的斐波那契数列,与求和1到1万亿,
然后框架达不到这个速度,杠精说qps不准。
4.9 演示延时运行任务
4.4章节的定时任务一般指的是周期性重复触发执行某个参数任务,4.9的演示任务是说对一个消息规定在什么时候去运行。
4.4是重复周期性的触发执行任务,4.9是对一个消息规定延时多长时间来执行它。一个有周期性重复触发的含义,一个是一次性的含义。
因为有很多人有这样的需求,希望发布后不是马上运行,而是延迟60秒或者现在发布晚上18点运行。
然来是希望用户自己亲自在消费函数内部写个sleep(60)秒再执行业务逻辑,来达到延时执行的目的,
但这样会被sleep占据大量的并发线程/协程,如果是用户消费函数内部写sleep7200秒这么长的时间,那
sleep等待会占据99.9%的并发工作线程/协程的时间,导致真正的执行函数的速度大幅度下降,所以框架
现在从框架层面新增这个延时任务的功能。
之前已做的功能是定时任务,现在新增延时任务,这两个概念有一些不同。
定时任务一般情况下是配置为周期重复性任务,延时任务是一次性任务。
1)框架实现定时任务原理是代码本身自动定时发布,自然而然就能达到定时消费的目的。
2)框架实现延时任务的原理是马上立即发布,当消费者取出消息后,并不是立刻去运行,
而是使用定时运行一次的方式延迟这个任务的运行。
在需求开发过程中,我们经常会遇到一些类似下面的场景:
1)外卖订单超过15分钟未支付,自动取消
2)使用抢票软件订到车票后,1小时内未支付,自动取消
3)待处理申请超时1天,通知审核人员经理,超时2天通知审核人员总监
4)客户预定自如房子后,24小时内未支付,房源自动释放
分布式函数调度框架的延时任务概念类似celery的countdown和eta入参, add.apply_async(args=(1, 2),countdown=20) # 规定取出后20秒再运行
此框架的入参名称那就也叫 countdown和eta。
countdown 传一个数字,表示多少秒后运行。
eta传一个datetime对象表示,精确的运行时间运行一次。
消费,消费代码没有任何变化
from funboost import boost, BrokerEnum
@boost('test_delay', broker_kind=BrokerEnum.REDIS_ACK_ABLE)
def f(x):
print(x)
if __name__ == '__main__':
f.consume()
发布延时任务
# 需要用publish,而不是push,这个前面已经说明了,如果要传函数入参本身以外的参数到中间件,需要用publish。
# 不然框架分不清哪些是函数入参,哪些是控制参数。如果无法理解就,就好好想想琢磨下celery的 apply_async 和 delay的关系。
from test_frame.test_delay_task.test_delay_consume import f
import datetime
import time
from funboost import PriorityConsumingControlConfig
"""
测试发布延时任务,不是发布后马上就执行函数。
countdown 和 eta 只能设置一个。
countdown 指的是 离发布多少秒后执行,
eta是指定的精确时间运行一次。
misfire_grace_time 是指定消息轮到被消费时候,如果已经超过了应该运行的时间多少秒之内,仍然执行。
misfire_grace_time 如果设置为None,则消息一定会被运行,不会由于大连消息积压导致消费时候已近太晚了而取消运行。
misfire_grace_time 如果不为None,必须是大于等于1的整数,此值表示消息轮到消费时候超过本应该运行的时间的多少秒内仍然执行。
此值的数字设置越小,如果由于消费慢的原因,就有越大概率导致消息被丢弃不运行。如果此值设置为1亿,则几乎不会导致放弃运行(1亿的作用接近于None了)
如果还是不懂这个值的作用,可以百度 apscheduler 包的 misfire_grace_time 概念
"""
for i in range(1, 20):
time.sleep(1)
# 消息发布10秒后再执行。如果消费慢导致任务积压,misfire_grace_time为None,即使轮到消息消费时候离发布超过10秒了仍然执行。
f.publish({'x': i}, priority_control_config=PriorityConsumingControlConfig(countdown=10))
# 规定消息在17点56分30秒运行,如果消费慢导致任务积压,misfire_grace_time为None,即使轮到消息消费时候已经过了17点56分30秒仍然执行。
f.publish({'x': i * 10}, priority_control_config=PriorityConsumingControlConfig(
eta=datetime.datetime(2021, 5, 19, 17, 56, 30) + datetime.timedelta(seconds=i)))
# 消息发布10秒后再执行。如果消费慢导致任务积压,misfire_grace_time为30,如果轮到消息消费时候离发布超过40 (10+30) 秒了则放弃执行,
# 如果轮到消息消费时候离发布时间是20秒,由于 20 < (10 + 30),则仍然执行
f.publish({'x': i * 100}, priority_control_config=PriorityConsumingControlConfig(
countdown=10, misfire_grace_time=30))
# 规定消息在17点56分30秒运行,如果消费慢导致任务积压,如果轮到消息消费时候已经过了17点57分00秒,
# misfire_grace_time为30,如果轮到消息消费时候超过了17点57分0秒 则放弃执行,
# 如果如果轮到消息消费时候是17点56分50秒则执行。
f.publish({'x': i * 1000}, priority_control_config=PriorityConsumingControlConfig(
eta=datetime.datetime(2021, 5, 19, 17, 56, 30) + datetime.timedelta(seconds=i),
misfire_grace_time=30))
# 这个设置了消息由于推挤导致运行的时候比本应该运行的时间如果小于1亿秒,就仍然会被执行,所以几乎肯定不会被放弃运行
f.publish({'x': i * 10000}, priority_control_config=PriorityConsumingControlConfig(
eta=datetime.datetime(2021, 5, 19, 17, 56, 30) + datetime.timedelta(seconds=i),
misfire_grace_time=100000000))
4.10 在web中如flask fastapi django 如何搭配使用消费框架的例子。
在web中推送任务,后台进程消费任务,很多人问怎么在web使用,用法和不与web框架搭配并没有什么不同之处。
因为发布和消费是使用中间件解耦的,一般可以分成web接口启动一次,后台消费启动一次,需要独立部署两次。
演示了flask 使用app应用上下文。
web接口中发布任务到消息队列,独立启动异步消费。
flask + 分布式函数调度框架演示例子在:
https://github.com/ydf0509/distributed_framework/blob/master/test_frame/use_in_flask_tonardo_fastapi
fastapi + 分布式函数调度框架演示例子在:
https://github.com/ydf0509/fastapi_use_distributed_framework_demo
django + 分布式函数调度框架演示例子在:
https://github.com/ydf0509/django_use_funboost
dajngo + funboost + 函数中操作了django orm的例子在:
https://github.com/ydf0509/funboost_django_orm_demo
uwsgi + flask + funboost 演示例子在:
https://github.com/ydf0509/uwsgi_flask_funboost
这三个web框架demo + funboost 框架,几乎是一模一样的,有的人不能举一反三,非要我单独增加demo例子。
部署方式都是web部署一次,后台消费部署一次,web接口中发布消息到消息队列,funboost没有与任何web框架有任何绑定关系,都是一样的用法。
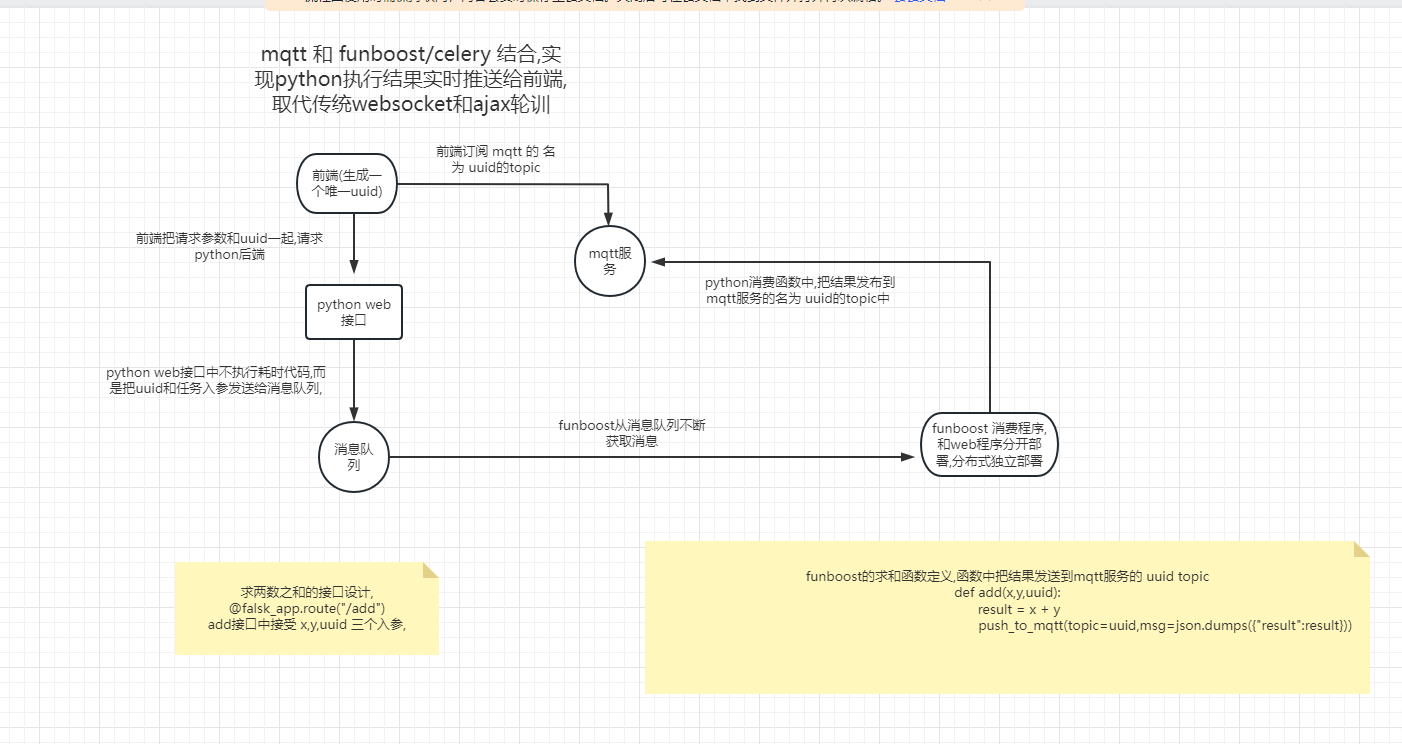
如果前端在乎任务的结果:
非常适合使用mqtt, 前端订阅唯一uuid的topic 然后表单中带上这个topic名字请求python接口 -> 接口中发布任务到rabbitmq或redis消息队列 ->
后台消费进程执行任务消费,并将结果发布到mqtt的那个唯一uuid的topic -> mqtt 把结果推送到前端。
使用ajax轮训或者后台导入websocket相关的包来做和前端的长耗时任务的交互 是伪命题。
使用 web + funboost +mqtt的流程图
4.11 保存消费状态和结果包mongo,开启消费状态结果的web页面
4.11.1 保存消费状态和结果到mongodb
需要配置好mongodb连接,并且设置 function_result_status_persistance_conf 持久化配置。
(1)需要安装mongodb,并且设置 MONGO_URL 的值
如果需要使用这个页面,那么无论选择何种中间件,即使不是使用mongo作为消息队列,也需要安装mongodb,因为因为是从这里读取数据的。
需要在 funboost_config.py 中设置MONGO_URL的值,mongo url的格式如下,这是通用的可以百度mongo url连接形式。
有密码 MONGO_CONNECT_URL = f'mongodb://yourname:yourpassword@127.0.01:27017/admin'
没密码 MONGO_CONNECT_URL = f'mongodb://192.168.6.132:27017/'
(2) 装饰器上需要设置持久化的配置参数,代码例子
框架默认不会保存消息状态和结果到mongo的,因为大部分人并没有安装mongo,且这个web显示并不是框架代码运行的必须部分,还有会降低一丝丝运行性能。
如果需要页面显示消费状态和结果,需要设置 @boost装饰器的 function_result_status_persistance_conf 的参数
FunctionResultStatusPersistanceConfig的如参是 (is_save_status: bool, is_save_result: bool, expire_seconds: int)
is_save_status 指的是是否保存消费状态,这个只有设置为True,才会保存消费状态到mongodb,从而使web页面能显示该队列任务的消费信息
is_save_result 指的是是否保存消费结果,如果函数的结果超大字符串或者对函数结果不关心或者函数没有返回值,可以设置为False。
expire_seconds 指的是多久以后,这些保存的数据自动从mongodb里面消失删除,避免爆磁盘。
from funboost import boost, FunctionResultStatusPersistanceConfig
@boost('queue_test_f01', qps=2,
function_result_status_persistance_conf=FunctionResultStatusPersistanceConfig(
is_save_status=True, is_save_result=True, expire_seconds=7 * 24 * 3600))
def f(a, b):
return a + b
if __name__ == '__main__':
f(5, 6) # 可以直接调用
for i in range(0, 200):
f.push(i, b=i * 2)
f.consume()
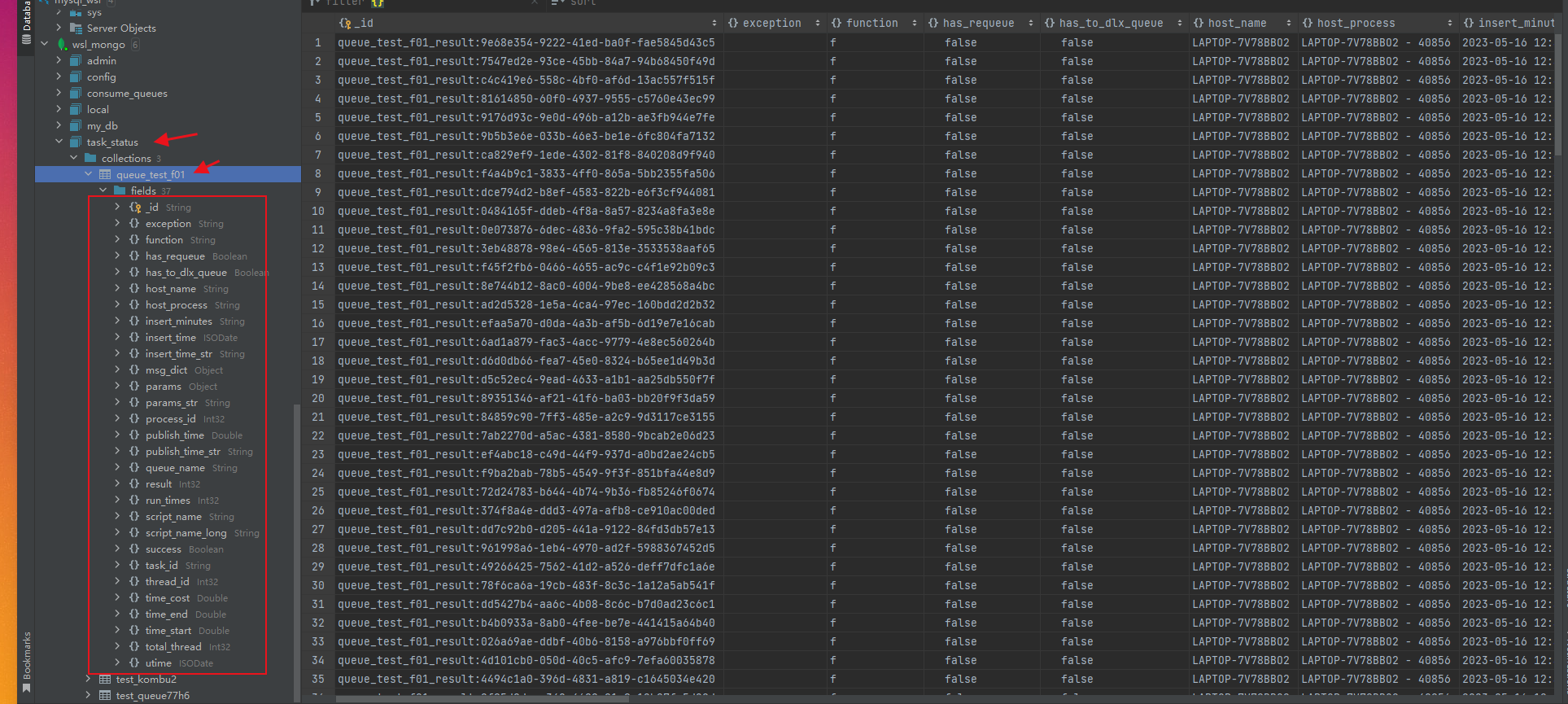
(3) 消费结果状态保存到mongo什么库什么表了?
是固定保存到名为 task_status 的库,表的名字就是队列名字。每个函数都会使用一个单独的表来保存消费状态结果。 有的人企图在 MONGO_CONNECT_URL 中指定db来决定消费结果保存到什么db
如下图所示,每次函数运行后,一共保存了37个字段到数据库中。
mongo保存结果截图
4.11.2 框架是可以自动保存消费状态/结果到mongo,你想保存到MySQL?
需要看 4.19 用户自定义记录函数消费 状态/结果 钩子函数 章节,设置一个记录函数运行状态的钩子函数, 你想在函数里面做啥都可以,把状态/结果插入到elastic orcale都没人管得了你。
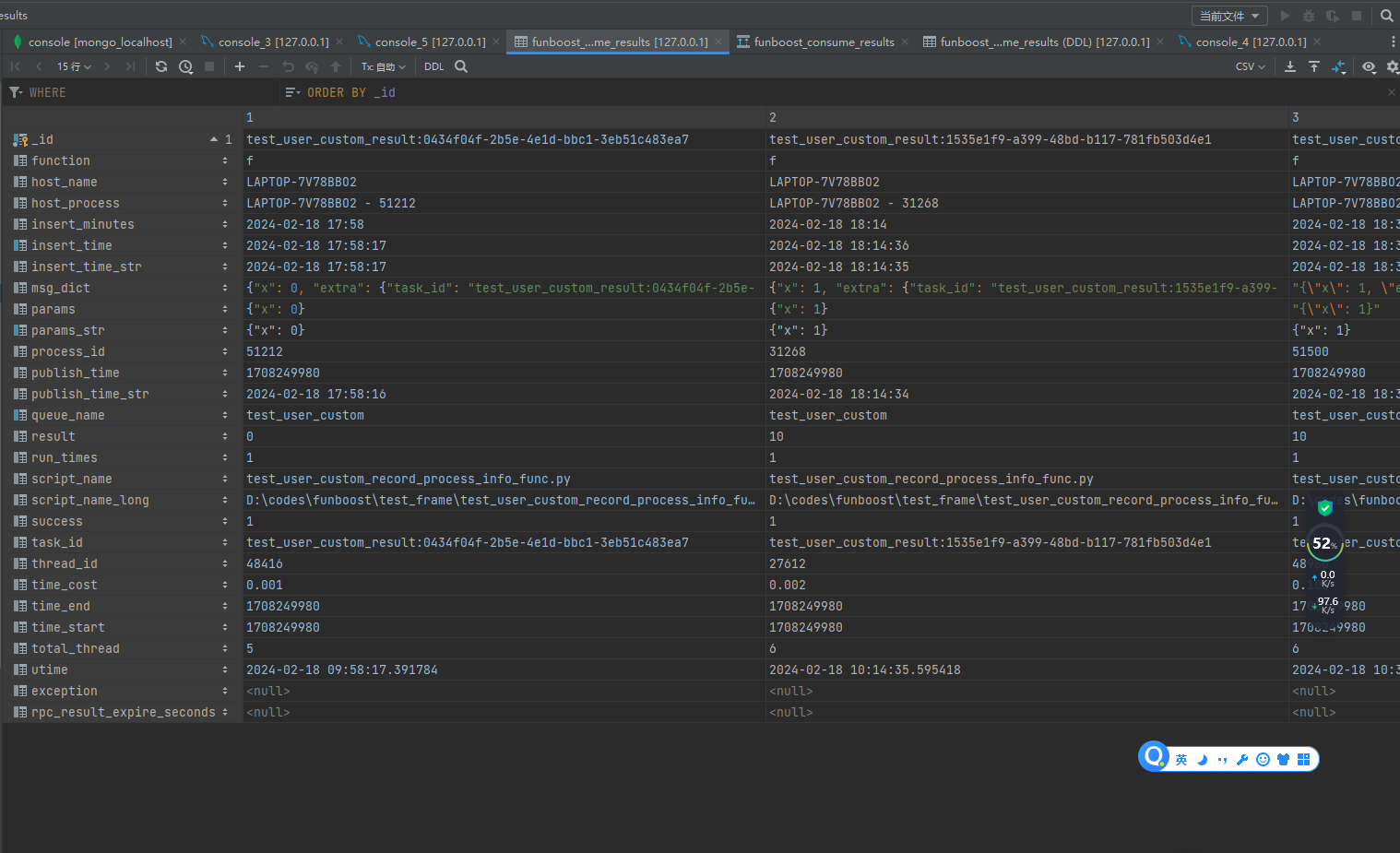
因为mysql需要运维建立数据库和建立表,funboost操作mongo可以代码中建立数据库和多个不同的队列名的表来保存消费状态。 用户想保存到mysql自己自定义 user_custom_record_process_info_func 钩子函数就好了,因为FunctionResultStatus对象上包含了所有必要信息。
4.11.2.b 作者自己贡献一个吧函数消费状态保存到mysql的函数,(2024.02新增)
实现代码见文件: https://github.com/ydf0509/funboost/blob/master/funboost/contrib/save_result_status_to_sqldb.py
from funboost import boost, FunctionResultStatus
import json
from funboost.contrib.save_result_status_to_sqldb import save_result_status_to_sqlalchemy # 不是框架必要部分的就通过 contrib 中增加代码.
"""
测试用户自定义记录函数消息处理的结果和状态到mysql
"""
# user_custom_record_process_info_func=my_save_process_info_fun 设置记录函数消费状态的钩子
@boost('test_user_custom', user_custom_record_process_info_func=save_result_status_to_sqlalchemy)
def f(x):
print(x * 10)
return x*10
if __name__ == '__main__':
for i in range(3):
f.push(i)
print(f.publisher.get_message_count())
f.consume()
作者自己实现的 save_result_status_to_sqlalchemy 记录函数,
1. 用户按照 funboost.contrib.save_result_status_to_sqldb 文件中的建表语句先建表,
2. 配置好 BrokerConnConfig.SQLACHEMY_ENGINE_URL 参数,
3. boost装饰器指定 user_custom_record_process_info_func=save_result_status_to_sqlalchemy
这样就能自动吧函数消费状态保存到mysql了.
用户自己也可以按需增加索引和增加字段和修改字段长度的,自己也可以改下建表语句或save_result_status_to_sqlalchemy函数就好了.
例如你可以增加消费函数的入参作为mysql表字段.
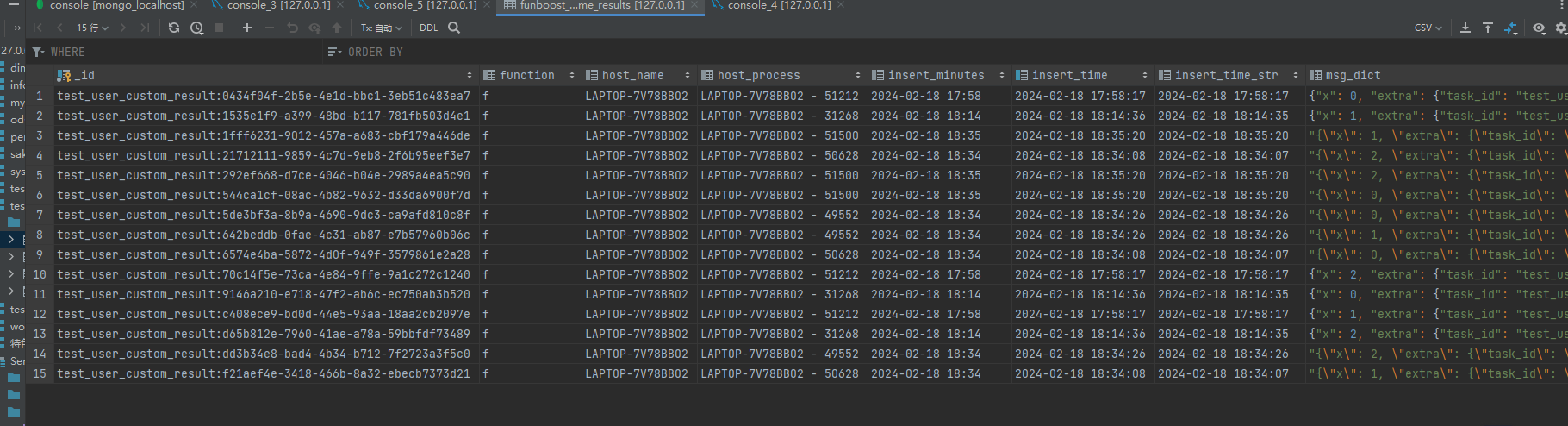
再一次附上funboost.contrib.save_result_status_to_sqldb 文件中的建表语句:
CREATE TABLE funboost_consume_results
(
_id VARCHAR(255),
`function` VARCHAR(255),
host_name VARCHAR(255),
host_process VARCHAR(255),
insert_minutes VARCHAR(255),
insert_time datetime,
insert_time_str VARCHAR(255),
msg_dict JSON,
params JSON,
params_str VARCHAR(255),
process_id BIGINT(20),
publish_time FLOAT,
publish_time_str VARCHAR(255),
queue_name VARCHAR(255),
result VARCHAR(255),
run_times INT,
script_name VARCHAR(255),
script_name_long VARCHAR(255),
success BOOLEAN,
task_id VARCHAR(255),
thread_id BIGINT(20),
time_cost FLOAT,
time_end FLOAT,
time_start FLOAT,
total_thread INT,
utime VARCHAR(255),
`exception` MEDIUMTEXT ,
rpc_result_expire_seconds BIGINT(20),
primary key (_id),
key idx_insert_time(insert_time),
key idx_queue_name_insert_time(queue_name,insert_time),
key idx_params_str(params_str)
)
保存到mysql中的消费状态和结果截图:
4.11.3 可视化,启动python分布式函数调度框架之函数运行结果状态web
web展示读取的是mongodb中保存的函数消费结果状态。
web代码在funboost包里面,所以可以直接使用命令行运行起来,不需要用户现亲自下载代码就可以直接运行。
# 第一步 export PYTHONPATH=你的项目根目录 ,这么做是为了这个web可以读取到你项目根目录下的funboost_config.py里面的配置
# 例如 export PYTHONPATH=/home/ydf/codes/ydfhome
或者 export PYTHONPATH=./ (./是相对路径,前提是已近cd到你的项目根目录了)
第二步
win上这么做 python3 -m funboost.function_result_web.app
linux上可以这么做使用gunicorn启动性能好一些,当然也可以按win的做。
gunicorn -w 4 --threads=30 --bind 0.0.0.0:27018 funboost.function_result_web.app:app
使用浏览器打开 127.0.0.1(启动web服务的机器ip):27018,输入默认用户名 密码 admin 123456,即可打开函数运行状态和结果页面。
函数执行结果及状态搜索查看
高并发
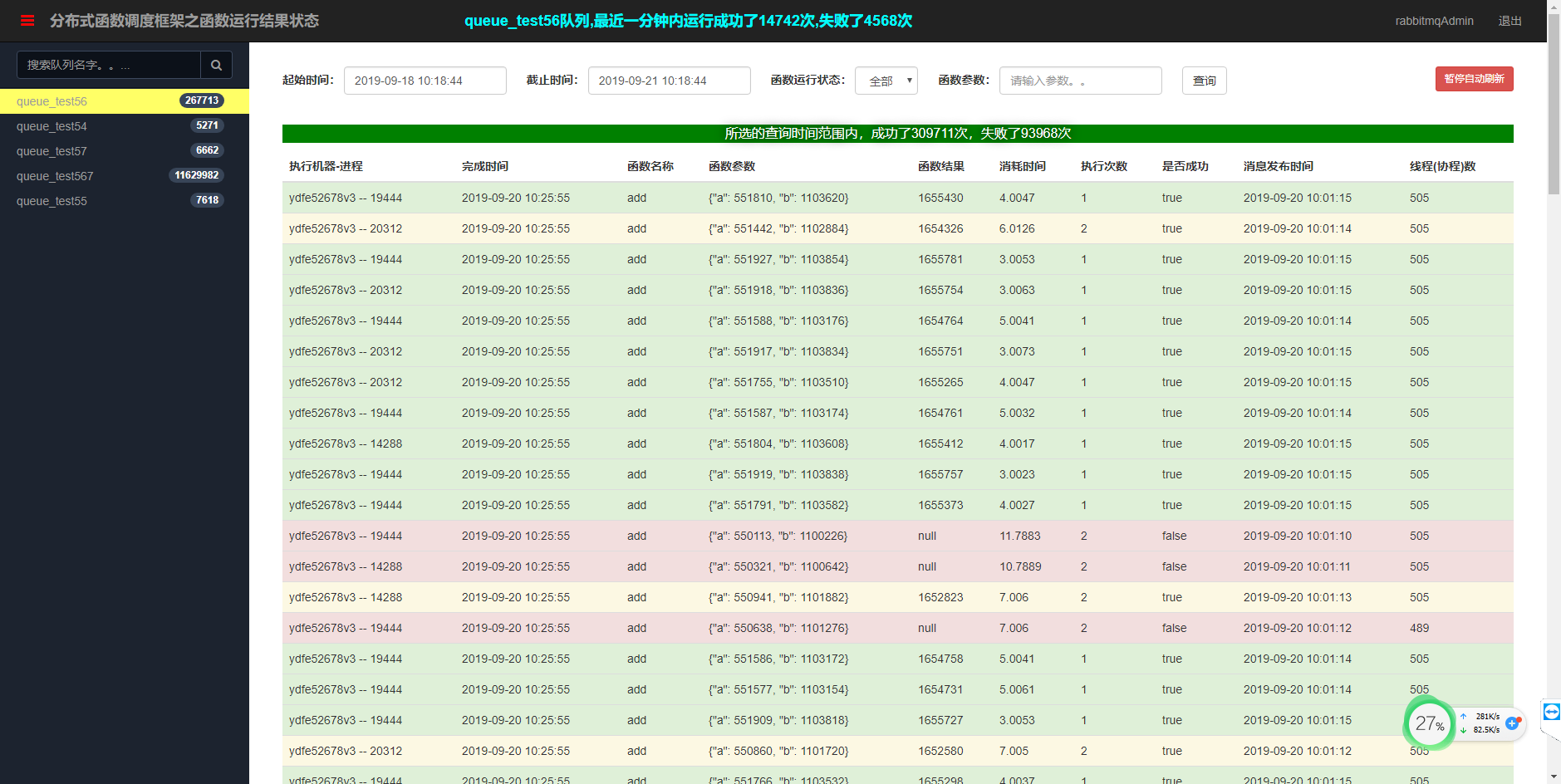
函数结果和运行次数和错误异常查看。使用的测试函数如下。
def add(a, b):
logger.info(f'消费此消息 {a} + {b} 中。。。。。')
time.sleep(random.randint(3, 5)) # 模拟做某事需要阻塞10秒种,必须用并发绕过此阻塞。
if random.randint(4, 6) == 5:
raise RandomError('演示随机出错')
logger.info(f'计算 {a} + {b} 得到的结果是 {a + b}')
return a + b
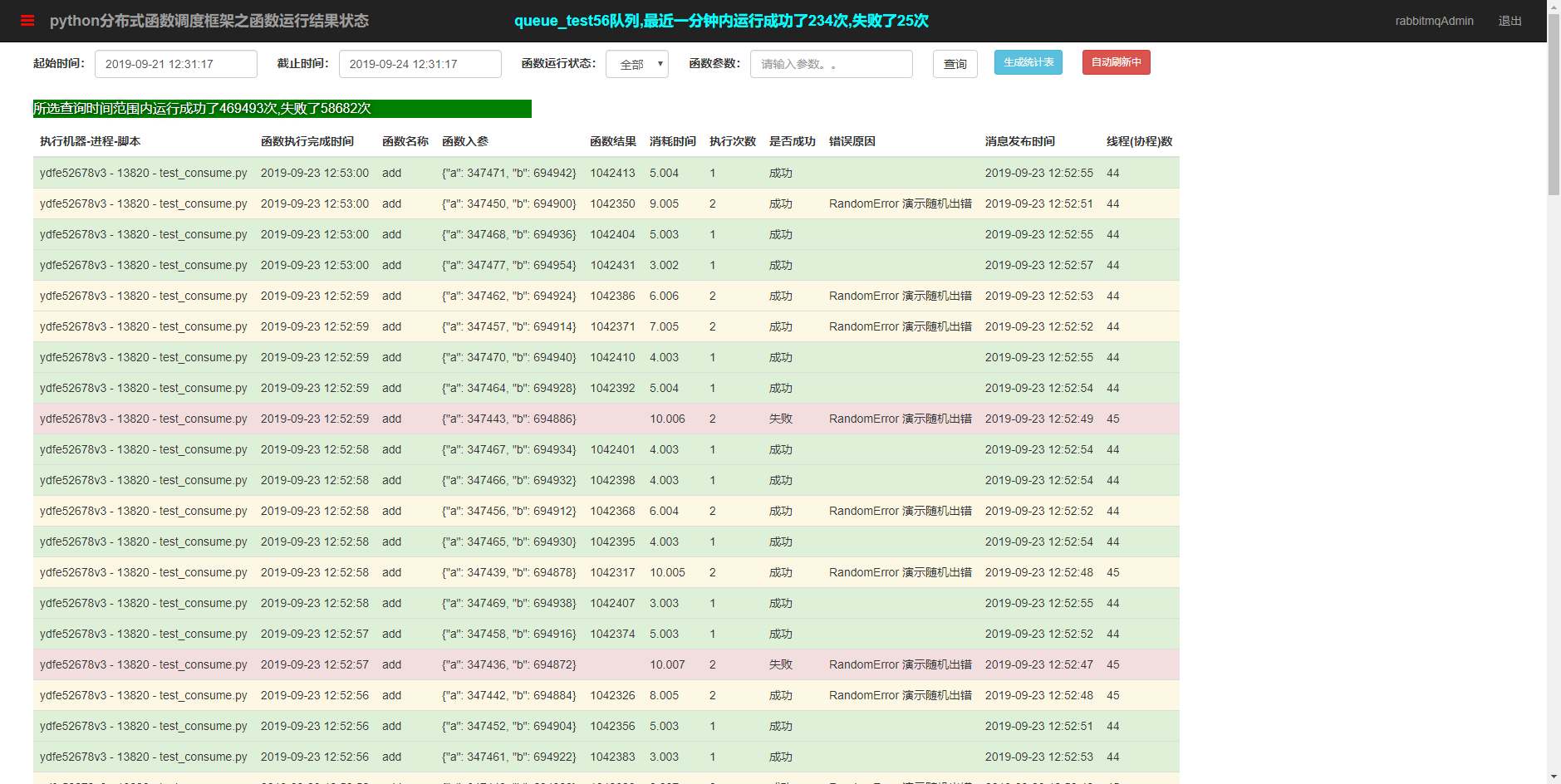
任务消费统计曲线。
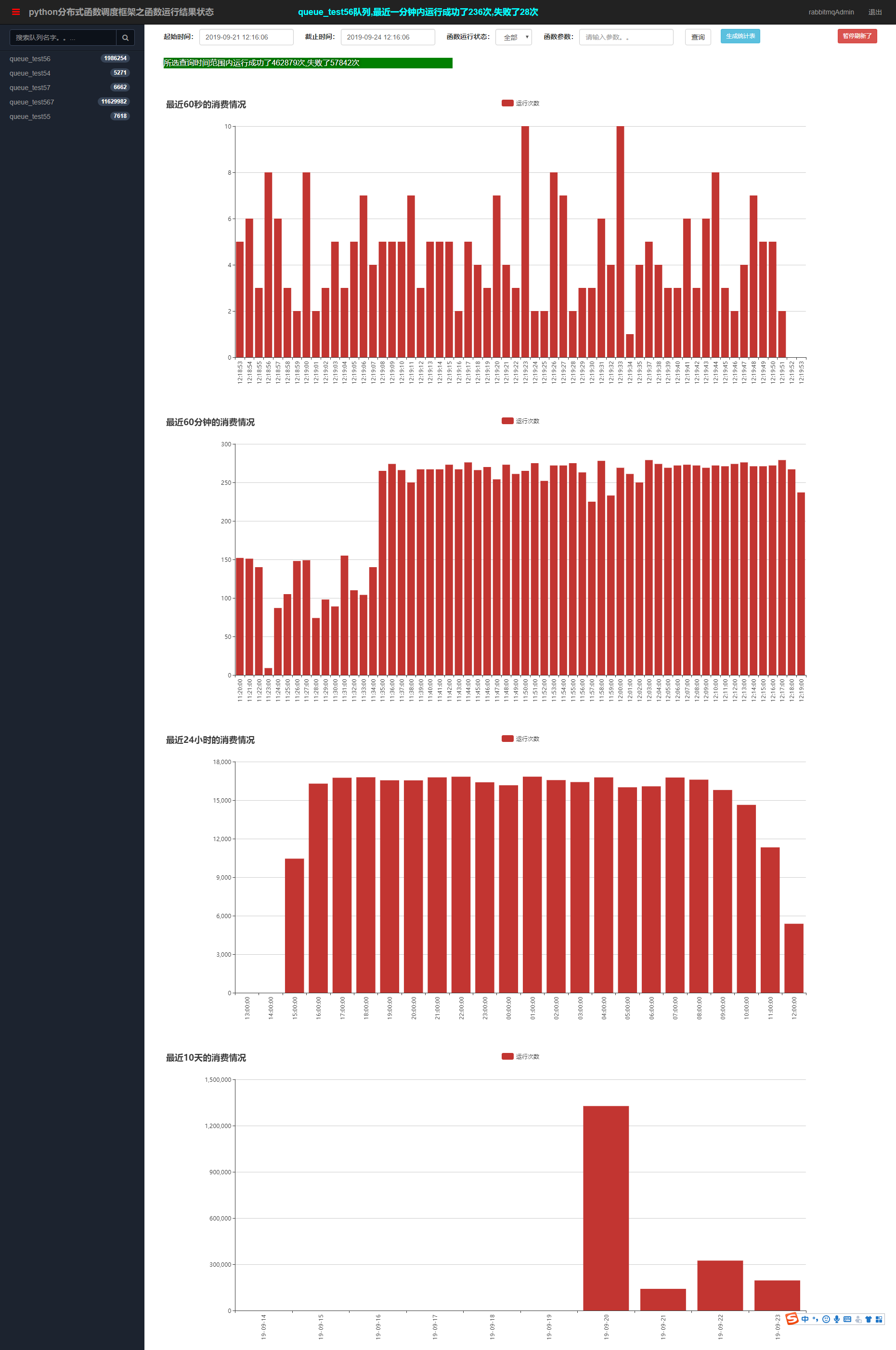
4.12 框架 asyncio 方式运行协程
4.12.1 concurrent_mode=ConcurrentModeEnum.ASYNC 运行协程
concurrent_mode=ConcurrentModeEnum.ASYNC是一个loop中真异步运行协程
见7.8的demo介绍,
import asyncio
from funboost import boost, ConcurrentModeEnum
@boost(....,concurrent_mode=ConcurrentModeEnum.ASYNC)
async def f():
await asyncio.sleep(2)
这种方式是@boost装饰在async def定义的函数上面。
celery不支持直接调度执行async def定义的函数,但此框架是直接支持asyncio并发的。
4.12.2 concurrent_mode=ConcurrentModeEnum.THREADING 运行asyncio协程
concurrent_mode=ConcurrentModeEnum.THREADING 在每个线程都创建独立的loop,每个协程运行在不同的loop中
见7.38的demo介绍,
import asyncio
from funboost import boost ConcurrentModeEnum
@boost(....,concurrent_mode=ConcurrentModeEnum.THREADING)
async def f():
await asyncio.sleep(2)
这种方式就是临时为每一个协程创建一个 loop,loop是一次性的。
funboot的asyncio 并发模式是真asyncio , 是在同一个loop中并发的运行多个协程对象。
伪 async 并发是多线程中每个线程临时 loop = asyncio.new_event_loop() ,然后 loop.run_until_complete() ,
这种就是假的,每隔协程都运行在不同的loop中。
ConcurrentModeEnum.THREADING 照样可以运行async def的函数。
这种当然是伪asyncio的,是临时 创建一个 loop。 看你咋想的喜欢真asyncio还是假的,这种也可以单进程1秒钟运行2000次asyncio的函数
4.13 跨项目怎么发布任务或者获取函数执行结果?
别的语言项目或者别的python项目手动发布消息到中间件,让分布式函数调度框架消费任务,
例如项目b中有add函数,项目a里面无法 import 导入这个add 函数。
1)第一种方式,使用能操作消息中间件的python包,手动发布任务到消息队列中间件
如果是别的语言发布任务,或者python项目a发布任务但是让python项目b的函数去执行,可以直接发布消息到中间件里面。
手动发布时候需要注意 中间件类型 中间件地址 队列名 @boost和funboost_config.py指定的配置要保持一致。
需要发布的消息内容是 入参字典转成json字符串,然后发布到消息队列中间件。
以下以redis中间件为例子。演示手动发布任务到中间件。
@boost('test_queue668', broker_kind=BrokerEnum.REDIS)
def add(x, y):
print(f''' 计算 {x} + {y} = {x + y}''')
time.sleep(4)
return x + y
if __name__ == '__main__':
r = Redis(db=7, host='127.0.0.1')
for i in range(10):
add.push(i, i * 2) # 正常同一个python项目是这么发布消息,使用函数.push或者publish方法
r.lpush('test_queue668', json.dumps({'x': i, 'y': i * 2})) # 不同的项目交互,可以直接手动发布消息到中间件
这个很容易黑盒测试出来,自己观察下中间件里面的内容格式就能很容易手动模仿构造出消息内容了。
需要说明的是 消息内容不仅包括 入参本身,也包括其他控制功能的辅助参数,可以用框架的自动发布功能发布消息,然后观察中间件里面的字段内容,模拟构造。
举个例子之一,例如如果要使用消息过期丢弃这个功能,那么就需要发布消息当时的时间戳了。
2)第二种方式,使用伪函数来作为任务,只写函数声明不写函数体。
此方式是一名网友的很机智的建议,我觉得可行。
例如还是以上面的求和函数任务为例,在项目a里面可以定义一个假函数声明,并且将b项目的求和add函数装饰器复制过去,但函数体不需要具体内容
@boost('test_queue668', broker_kind=BrokerEnum.REDIS) # a项目里面的这行和b项目里面的add函数装饰器保持一致。
def add(x, y): # 方法名可以一样,也可以不一样,但函数入参个数 位置 名称需要保持不变。
pass # 方法体,没有具体的求和逻辑代码,只需要写个pass就行了。
add.push(1,y=2)
之后通过这个假的add函数就可以享受到与在同一个项目中如何正常发布和获取求和函数的执行结果 一模一样的写法方式了。
例如add.clear() 清空消息队列,add.push发布,add.publish发布,async_result.get获取结果,都可以正常使用,
但不要使用add.consume启动消费,因为这个是假的函数体,不能真正的执行求和.
3)第三种方式,使用get_publisher来获取发布者,然后使用publish来发布函数的入参字典。
from funboost import get_publisher, BrokerEnum,PublisherParams
publisher1 = get_publisher(PublisherParams(queue_name='test_nameko_queue', broker_kind=BrokerEnum.REDIS))
publisher2 = get_publisher(PublisherParams(queue_name='test_nameko_queue2', broker_kind=BrokerEnum.REDIS))
for i in range(100):
print(publisher1.publish({'a':i,'b':i+1})) # 远程函数是 def (a,b)
print(publisher2.publish({'x':i,'y':i+1})) # 远程函数是 def (x,y)
4)第四种方式,在消费函数所在项目里面用 fastapi flask啥的写一个接口用于接受请求并把接收到的消息发送到消息队列(框架自带了一个fastapi 发布消息接口).
例如项目a是java,项目b是你的python消费函数所在项目.
你在b项目里面用falsk fastapi 框架开个接口,接口中根据队列名和消息体,在python项目的web接口中发布消息到消息队列.
funboost.contrib.api_publish_msg 贡献了一个fastapi的接口,可以用于发布消息和获取消息执行结果.
运行web前,用户需要手动import导入 @boost所在模块,或者BoosterDiscovery自动导入模块,以便能找到队列对应的函数.
from pathlib import Path
from funboost.contrib.api_publish_msg import app, BoosterDiscovery
"""
# 如果用户不使用 BoosterDiscovery,那么需要导入一下boost相关的函数所在的模块,不然无法根据队列名找到队列相关的函数定义.
需要
import test_frame.test_api_publish_msg.tasks.boost1
import test_frame.test_api_publish_msg.tasks.boost2
"""
BoosterDiscovery(project_root_path=Path(__file__).absolute().parent.parent.parent,
booster_dirs=[Path(__file__).absolute().parent / Path('tasks')]).auto_discovery()
if __name__ == '__main__':
'''
uvicorn test_frame.test_api_publish_msg.test_api_publish_server:app --workers 4 --port 16667
'''
import uvicorn
uvicorn.run('funboost.contrib.api_publish_msg:app', host="0.0.0.0", port=16667, workers=4)
4.14 获取消费进程信息的方法(用于排查查看正在运行的消费者)
from funboost import ActiveCousumerProcessInfoGetter
'''
获取分布式环境中的消费进程信息。
使用这里面的4个方法需要相应函数的@boost装饰器设置 is_send_consumer_hearbeat_to_redis=True,这样会自动发送活跃心跳到redis。否则查询不到该函数的消费者进程信息。
要想使用消费者进程信息统计功能,用户无论使用何种消息队列中间件类型,用户都必须安装redis,并在 funboost_config.py 中配置好redis链接信息
'''
# 获取分布式环境中 test_queue 队列的所有消费者信息
print(ActiveCousumerProcessInfoGetter().get_all_hearbeat_info_by_queue_name('test_queue'))
# 获取分布式环境中 当前列机器的所有消费者信息
print(ActiveCousumerProcessInfoGetter().get_all_hearbeat_info_by_ip())
# 获取分布式环境中 指定ip的所有消费者信息
print(ActiveCousumerProcessInfoGetter().get_all_hearbeat_info_by_ip('10.0.195.220'))
# 获取分布式环境中 所有 队列的所有消费者信息,按队列划分
print(ActiveCousumerProcessInfoGetter().get_all_hearbeat_info_partition_by_queue_name())
# 获取分布式环境中 所有 机器的所有消费者信息,按ip划分
print(ActiveCousumerProcessInfoGetter().get_all_hearbeat_info_partition_by_ip())
获取消费进程信息的方法的用途,用于排查查看正在运行的消费者
1、有的人老是说自己已经把消费进程关了,但是消息队列中的消费还在消费,用get_all_hearbeat_info_by_queue_name方法就能查出来还有哪些机器在消费这个队列了
2、有的人老是说发送消息,消息队列的任务,没被消费,也可以使用get_all_hearbeat_info_by_queue_name方法
3、get_all_hearbeat_info_by_ip 方法用于查看一台机器在运行哪些消息队列。
4、get_all_hearbeat_info_partition_by_queue_name和get_all_hearbeat_info_partition_by_ip分别按队列和机器分组显示
4.16 文件日志所在的地方
框架使用的是nb_log,控制台五彩日志 + 多进程安全切割文件的 nb_log
你项目根目录下的 nb_log_config.py 中的 LOG_PATH 决定了默认日志文件夹的位置,win默认在磁盘根目录下的/pythonlogs文件夹。 具体看 nb_log_config.py
nb_log 介绍见: https://github.com/ydf0509/nb_log
tips:
嫌弃日志提示详细(啰嗦)的问题见:文档6.17 https://funboost.readthedocs.io/zh/latest/articles/c6.html#b-2-logmanager-preset-log-level
4.16.1 没亲自指定 日志文件名
代码:
文件日志截图:

如上图,如果你不在boost装饰器亲自指定log_filename,那么每个队列的都有单独的日志文件,就是不同的消费函数写在不同的日志文件中,很方便查看问题。
4.16.2 亲自指定日志文件名,log_filename的值
如果你指定了log_filename,那么就会写入到你指定的文件中,而不是使用队列名自动生成文件名.
代码:
import logging
import time
from funboost import boost, BrokerEnum, BoosterParams
from nb_log import get_logger
LOG_FILENAME = '自定义日志文件名.log'
class BoosterParamsMy(BoosterParams): # 传这个类就可以少每次都亲自指定使用rabbitmq作为消息队列,和使用rpc模式。
"""
定义子类时候,字段也要注意带上类型注释
"""
broker_kind: str = BrokerEnum.RABBITMQ
max_retry_times: int = 4
log_level: int = logging.DEBUG
log_filename: str = LOG_FILENAME
my_file_logger = get_logger('my_business', log_filename=LOG_FILENAME)
@boost(boost_params=BoosterParamsMy(queue_name='task_queue_name1111', qps=3, ))
def task_fun(x, y):
print(f'{x} + {y} = {x + y}')
my_file_logger.debug(f"1111 这条日志会写到 {LOG_FILENAME} 日志文件中 {x} + {y} = {x + y}")
time.sleep(3) # 框架会自动并发绕开这个阻塞,无论函数内部随机耗时多久都能自动调节并发达到每秒运行 3 次 这个 task_fun 函数的目的。
@boost(boost_params=BoosterParamsMy(queue_name='task_queue_name2222', qps=10, ))
def task_fun2(x, y):
print(f'{x} - {y} = {x - y}')
my_file_logger.debug(f"2222 这条日志会写到 {LOG_FILENAME} 日志文件中 {x} - {y} = {x - y} ")
time.sleep(3) # 框架会自动并发绕开这个阻塞,无论函数内部随机耗时多久都能自动调节并发达到每秒运行 10 次 这个 task_fun 函数的目的。
if __name__ == "__main__":
task_fun.consume() # 消费者启动循环调度并发消费任务
task_fun2.consume()
for i in range(10):
task_fun.push(i, y=i * 2) # 发布者发布任务
task_fun2.push(i, i * 10)
日志文件截图,可以发现所有消费发布都写到 自定义日志文件名.log里面了,my_file_logger 的get_logger 入参 log_filename 也是指定写到 这个文件, 所以你的业务日志和框架日志可以是在同一个文件中
4.16.3 把用户自己的业务日志和funboost框架日志写到同一个文件
from nb_log import get_logger
如上 4.16.2, my_file_logger = get_logger('my_business', log_filename=LOG_FILENAME),
你用这个实例化的 my_file_logger 去记录日志,
在boost装饰器的log_filename 和get_logger 的 log_filename 指定为相同的文件名字,那就可以写入同一个文件了.
4.16.4 funboost 日志由 nb_log 提供。
关于funboost的日志和日志级别过滤,看nb_log 9.5 章节文档
https://nb-log-doc.readthedocs.io/zh_CN/latest/articles/c9.html#id6
4.17 判断函数运行完所有任务,再执行后续操作
框架是消息队列执行任务,理论上永不停止,消息源源不断的进入消息队列然后被消费,
不会有明显的结束含义,即使消息队列已经空了,代码也会待命拉取消费未来的下一条消息,
因为代码无法知道用户会不会将来又push消息到消息队列中。
但有的人脚本是一次性运行的或者他需要当前批次的消息消费完后执行某个操作,
可以使用 wait_for_possible_has_finish_all_tasks来判断函数的消息队列是否已经运行完了。
原理是消费者近n分钟内没有执行任务并且消息队列中间件中的消息数量持续n分钟是0,就判断为可能运行完了。
wait_for_possible_has_finish_all_tasks的入参是判断n分钟内消息数量,那么这个n最好是消费函数最大运行时间的3倍。
例如函数最大耗时120秒,那么可以设置入参为6分钟,如果设置过小,可能会出现实际还有余量任务正在执行中,导致判断失误。
wait_for_possible_has_finish_all_tasks是一个阻塞函数,只有判断疑似消息队列所有任务完成了,代码才会运行到下一行。
然后执行某些操作,例如可以发个邮件通知下,例如 os._exit()可以退出脚本,非常的灵活。
此功能可以用于,例如
爬取猫眼 淘票票 糯米全中国所有城市的电影院的放映场次,然后对电影场次进行全网匹配和统计分析,一个电影场次在每个app的价格,统计全中国每个城市播放多少场次电影。
那么这种后续的操作就必须先等每一个电影播放场次的详情页爬虫函数运行完了,再进行匹配和统计分析。如果都没爬取完成还在运行,就开始执行全量电影场次的统计分析那无疑是漏数据不准确。
import time
import os
from funboost import boost
@boost('test_f1_queue', qps=0.5)
def f1(x):
time.sleep(3)
print(f'x: {x}')
for j in range(1, 5):
f2.push(x * j)
@boost('test_f2_queue', qps=2)
def f2(y):
time.sleep(5)
print(f'y: {y}')
if __name__ == '__main__':
f1.clear()
f2.clear()
for i in range(30):
f1.push(i)
f1.consume()
f1.wait_for_possible_has_finish_all_tasks(4)
print('f1函数的队列中4分钟内没有需要执行的任务,f1运行完了,现在启动f2的消费')
f2.consume()
f2.wait_for_possible_has_finish_all_tasks(3)
print('f2函数的队列中3分钟内没有需要执行的任务,发个邮件通知一下')
print('f1 和f2任务都运行完了,。。。')
print('马上 os._exit(444) 结束脚本')
os._exit(444) # 结束脚本
4.18 暂停消费
框架支持暂停消费功能和继续消费功能,boost装饰器需要设置is_send_consumer_hearbeat_to_redis=True
from funboost import boost
@boost('test_queue73ac', is_send_consumer_hearbeat_to_redis=True)
def f2(a, b):
return a - b
if __name__ == '__main__':
for i in range(1000):
# f.push(i, i * 2)
f2.push(i, i * 2)
f2.consume()
while 1:
f2.pause_consume()
time.sleep(300)
f2.continue_consume()
time.sleep(300)
f.continue_consume 意思是继续消费,这个设置redis对应键 f'funboost_pause_flag:{self.queue_name}' 的状态为1了,
f.pause_consume 意思是暂停消费,这个设置redis对应键 f'funboost_pause_flag:{self.queue_name}' 的状态为0了,
框架中有专门的线程每隔10秒扫描redis中设置的暂停状态判断是否需要暂停和继续消费,所以设置暂停和接续后最多需要10秒就能暂停或启动消费生效了。
上图片为上面例子的代码消费5分钟然后暂停5分钟,一直循环
有的人问怎么在其他地方设置暂停消费,说我这例子是函数和设置暂停消费在同一个脚本,
这个从redis获取暂停状态本来就是为了支持从python解释器外部或者远程机器设置暂停,怎么可能只能在函数所在脚本设置暂停消费。
例如在脚本 control_pause.py中写
from xx import f2
f2.pause_consume()
这不就完了吗。如果是别的java项目代码中控制暂停消费,可以设置redis的 funboost_pause_flag:{queue_name} 这个键的值为 1,
这样就能使消费暂停了。在python web接口中设置暂停状态就用 f2.pause_consume() 就行了。
4.19 用户自定义记录函数消费 状态/结果 钩子函数
可以通过设置 user_custom_record_process_info_func 的值指向你的函数,来记录函数的消费结果,这种比较灵活。
用户定义一个函数,函数的入参只有一个 function_result_status ,这个变量是 FunctionResultStatus 类型的对象,有很多属性可供使用,
例如函数 入参 结果 耗时 发布时间 处理线程id 处理机器等等,可以更好的和用户自己的系统对接。
from funboost import boost, FunctionResultStatus
"""
测试用户自定义记录函数消息处理的结果和状态到mysql
"""
def my_save_process_info_fun(function_result_status: FunctionResultStatus):
""" function_result_status变量上有各种丰富的信息 ,用户可以使用其中的信息
用户自定义记录函数消费信息的钩子函数
"""
print('function_result_status变量上有各种丰富的信息: ',
function_result_status.publish_time, function_result_status.publish_time_str,
function_result_status.params, function_result_status.msg_dict,
function_result_status.time_cost, function_result_status.result,
function_result_status.process_id, function_result_status.thread_id,
function_result_status.host_process, )
print('保存到数据库', function_result_status.get_status_dict())
# user_custom_record_process_info_func=my_save_process_info_fun 设置记录函数消费状态的钩子
@boost('test_user_custom', user_custom_record_process_info_func=my_save_process_info_fun)
def f(x):
print(x * 10)
if __name__ == '__main__':
for i in range(50):
f.push(i)
print(f.publisher.get_message_count())
f.consume()
4.19.b 自定义保存函数消费状态结果到mysql/sqlite/pgsql请看4.11.2.b的章节
4.20 通过 broker_exclusive_config 参数 设置不同中间件能使用到的差异化独特配置
加上一个不同种类中间件非通用的配置,不同中间件自身独有的配置,不是所有中间件都兼容的配置,因为框架支持30种消息队列,消息队列不仅仅是一般的先进先出queue这么简单的概念,
例如kafka支持消费者组,rabbitmq也支持各种独特概念例如各种ack机制 复杂路由机制,每一种消息队列都有独特的配置参数意义,可以通过这里传递。
之前的做法是为了简化难度和兼容各种消息队列中间件用法,有的地方写死了不利于精细化控制使用,例如kafka消费其实有很多配置的高达30多项,不是光有个 bootstrap_servers 设置kafka的地址,
例如 group_id max_in_flight_requests_per_connection auto_offset_reset 等。以后会逐步精细化针对各种消息队列的独特概念用途放开更多的差异化独特配置。
使用方式例如设置
@boost('test_queue70ac', broker_kind=BrokerEnum.KAFKA_CONFLUENT,broker_exclusive_config={'group_id':"my_kafka_group_id_xx"})
def f(x):
pass
具体的每种消息队列能支持哪些参数配置,必须是对应Consumer类的 BROKER_EXCLUSIVE_CONFIG_KEYS 指定的配置名字的范围之类才能起作用,
例如你使用redis的list结构做消息队列,你去设置消费者组那是没什么卵用的。
打个比喻消费是看书,redis的list和rabbitmq消费消息,是看一页就把书本的那一页撕下来,下次继续看书本中剩下的页就好了。不可多组重复回拨消费,不需要存在啥消费者组这种概念。
kafka消费消息,是小明和小红分别看这本书,小明每看完几页后,会夹一个小明的书签到最新看到的地方,下次小明继续看就先找到小明的书签,继续读之后的页数。
小红和小明分别使用不同的书签标记他们各自读到哪一页了,kafka不是看完一页就把那张撕下来,所以kafka存在消费者组概念,
所以funboost提供broker_exclusive_config入参来支持不同消息队列独有特性。
以后将增加更多的差异化设置参数,能更深入灵活使用不同中间件的独特概念和功能
4.21 【完全自由定制扩展】 使用 register_custom_broker 完全彻底自由灵活自定义扩展和定制修改中间件(消费者和发布者)
这种扩展功能需要有python基础,继承框架的消费者和发布者抽象类或抽象类的子孙类,注册到框架种。消费和发布逻辑细节可以完全由用户自定义。
这个是增加的一种很强大的功能,用户可以自定义发布者和消费者,注册到框架中。boost装饰器就能自动使用你的消费者类和发布者类了。 这个功能很好很强,能彻底解决框架的流程逻辑不符合你的期望时候,用户能够自定义一些细节。需要用户有一定的python语法基础和面向对象 设计模式才能用这个功能。 为什么增加这个功能,是由于总是有不符合用户期望的细节,用户如果要定制就要修改源码这样不方便,现在有了这就可以自由定制扩展了
用户自定义的类可以继承 AbstractConsumer ,这种方式适合扩展支持新的中间件种类。
也可以继承自框架中已有的 AbstractConsumer 的子类,这种适合对逻辑进行调整,或者增加打印什么的 。 test_frame/test_custom_broker/test_custom_redis_consume_latest_publish_msg_broker.py 就是继承自 AbstractConsumer 的子类。
register_custom_broker有两个用途
1 是给用户提供一种方式新增消息队列中间件种类,(funboost框架支持了所有知名类型消息队列中间件或模拟中间件,这个用途的可能性比较少)
2 可以对已有中间件类型的消费者 发布者类继承重写符合自己意愿的,这样就不需要修改项目的源代码了,这种用法非常的强大自由,可以满足一切用户的特殊定制想法。
因为用户可以使用到self成员变量和通过重写使用其中的函数内部局部变量,能够做到更精细化的特殊定制。这个用途很强大自由灵活定制。
用法例如 register_custom_broker(BROKER_KIND_LIST, ListPublisher, ListConsumer) # 核心,这就是将自己写的类注册到框架中,框架可以自动使用用户的类,这样用户无需修改框架的源代码了。
以下为4个扩展或定制的代码例子:
继承AbstractConsumer基类 ,自定义扩展使用list作为消息队列
继承AbstractConsumer基类 ,自定义扩展使用deque作为消息队列
继承AbstractConsumer的子类 ,自定义扩展使用redis实现先进后出 后进先出,总是优先消费最晚发布的消息的例子
4.23 演示funboost框架是如何代替用户手写调用线程池的
为什么框架介绍中说有了funboost,再也无需用户手动操作线程和线程池ThradPoolExecutor以及multiprossing.Process()了。
手动使用线程池写法
import time
from concurrent.futures import ThreadPoolExecutor
def f(x, y):
print(f'{x} + {y} = {x + y}')
time.sleep(10)
if __name__ == '__main__':
pool = ThreadPoolExecutor(5)
for i in range(100):
pool.submit(f, i, i * 2)
funboost取代手写调用线程池
import time
from funboost import boost, BrokerEnum
@boost('test1', broker_kind=BrokerEnum.MEMORY_QUEUE, concurrent_num=5)
def f(x, y):
print(f'{x} + {y} = {x + y}')
time.sleep(10)
if __name__ == '__main__':
f.consume()
for i in range(100):
f.push(i, i * 2)
这两个的效果是一样的,都是使用内存queue来保存待运行的任务,都是使用5线程并发运行f函数的。
funboost还能开启多进程,取代用户手写 Process(target=fx),所以有了funboost,用户无需手写开启线程 进程。
如果用户希望任务保存到redis中先,而不是保存在python内存queue中,那就使用funboost比调用ThreadPoolExecutor方便多了。
再比如用户希望每秒运行完成10次f函数(控制台每秒都打印10次求和结果),而不是开启10线程来运行f函数,funboost则远方便于ThreadPoolExecutor
4.24 设置消费函数重试次数
import random
import time
from funboost import boost, BrokerEnum
@boost('test_queue9', broker_kind=BrokerEnum.REDIS_ACK_ABLE, max_retry_times=5)
def add(a, b):
time.sleep(2)
if random.random() >0.5:
raise ValueError('模拟消费函数可能出错')
return a + b
if __name__ == '__main__':
for i in range(1,1000):
add.push(i,i*2)
add.consume()
通过设置 max_retry_times 的值,可以设置最大重试次数,函数如果出错了,立即将参数重试max_retry_times次,如果重试次数达到指定的max_retry_times,就执行确认消费了。
4.24.b 抛出ExceptionForRequeue类型错误,消息立即重回消息队列
@boost('test_rpc_queue', is_using_rpc_mode=True, broker_kind=BrokerEnum.REDIS_ACK_ABLE, qps=100,max_retry_times=5)
def add(a, b):
time.sleep(2)
if random.random() >0.5:
raise ExceptionForRequeue('模拟消费函数可能出错,抛出ExceptionForRequeue类型的错误可以使消息立即重回消息队列')
return a + b
if __name__ == '__main__':
add.consume()
消费函数中 raise ExceptionForRequeue ,会使消息立即重回消息队列的尾部。 如果函数运行该消息的出错概率使100%,就要慎重了,
避免函数运行这个消息一直出错一直重回消息队列,无限蒙蔽死循环消费这个入参。
4.24.c 抛出 ExceptionForPushToDlxqueue 类型错误,消息发送到单独另外的死信队列中
@boost('test_rpc_queue', is_using_rpc_mode=True, broker_kind=BrokerEnum.REDIS_ACK_ABLE, qps=100,max_retry_times=5)
def add(a, b):
time.sleep(2)
if random.random() >0.5:
raise ExceptionForPushToDlxqueue('模拟消费函数可能出错,抛出ExceptionForPushToDlxqueue类型的错误,可以使消息发送到单独的死信队列中')
return a + b
if __name__ == '__main__':
add.consume()
消费函数中 raise ExceptionForPushToDlxqueue ,可以使消息发送到单独的死信队列中,死信队列的名字是正常队列的名字 + _dlx
4.24.d 设置is_push_to_dlx_queue_when_retry_max_times,重试到max_retry_times最大次数没成功发送到死信队列
@boost 装饰器 设置 is_push_to_dlx_queue_when_retry_max_times = True,
则函数运行消息出错达到max_retry_times最大重试次数后仍没成功,确认消费,同时发送到死信队列中。
4.24.e (内置辅助)将一个消息队列中的消息转移到另一个队列
可以用于死信队列转移到正常队列。
from funboost.contrib.queue2queue import consume_and_push_to_another_queue,multi_prcocess_queue2queue
if __name__ == '__main__':
# 一次转移一个队列,使用单进程
# consume_and_push_to_another_queue('test_queue77h3', BrokerEnum.RABBITMQ_AMQPSTORM,
# 'test_queue77h3_dlx', BrokerEnum.RABBITMQ_AMQPSTORM,
# log_level_int=logging.INFO, exit_script_when_finish=True)
# 转移多个队列,并使用多进程。
multi_prcocess_queue2queue([['test_queue77h5', BrokerEnum.RABBITMQ_AMQPSTORM, 'test_queue77h4', BrokerEnum.RABBITMQ_AMQPSTORM]],
log_level_int=logging.INFO, exit_script_when_finish=True, n=6)
4.25 push和publish发布消息区别
funboost的push和publish 就像celery的delay和apply_async关系一样。
一个简单方便,一个复杂强大。前者的入参和函数本身入参类似,后者除了函数入参本身,还可以单独指定改任务的控制属性。
from funboost import boost
@boost('test_queue_pub',)
def add(a, b):
return a + b
if __name__ == '__main__':
# push的入参就和正常调用函数一样的入参方式,框架会自动把多个入参组合成一个字典,字典再转化成json发布到消息队列。
add.push(1,2)
add.push(1,b=2)
add.push(a=1,b=2)
# publish 意思是把所有入参参数作为一个字典,框架会把字典转化成json发布到消息队列,publish除了发布函数入场本身外,还可以设置一些其他任务属性。
# 所以publish是比push更强大的存在,push是简单,publish是更可以发布任务控制参数。
add.publish({"a":1,"b":2})
# publish 除了可以发布函数入参本身以外,还能发布任务控制参数,例如可以手动的指定id而非有框架自动生成任务id,还能设置其他控制参数。
# 例如 在 priority_control_config的PriorityConsumingControlConfig中设置 msg_expire_senconds =5,可以使得发布消息离消费超过5秒,丢弃消息不消费。
# 例如设置is_using_rpc_mode = True ,则可以单独使该任务参数支持rpc获得结果。
add.publish({"a":1,"b":2},task_id=100005,priority_control_config=PriorityConsumingControlConfig(is_using_rpc_mode=True))
4.26 性能调优演示
要看4.5章节的说明,有的人不看文档,不知道怎么性能达到最好,不知道怎么开多进程,只知道简单demo的 fun.consume()方式启动消费
有的人不看4.5章节文档,需要重新说明
import time
from funboost import boost,ConcurrentModeEnum
@boost('test_queue_add',)
def add(a, b):
time.sleep(2) # 模拟io或cpu耗时
return a + b
@boost('test_queue_sub',concurrent_num=200,concurrent_mode=ConcurrentModeEnum.THREADING)
def sub(x, y):
time.sleep(5) # 模拟io或cpu耗时
return x - y
对于上面这两个消费函数,启动消费说明
4.26.1 在一个进程中启动多个函数的消费,适合轻型任务
常规启动方式是这样,直接在当前进程里面启动两个函数的consume
add.consume()
sub.consume()
这种是一个进程内部启动多个消费函数,每个函数是默认使用多线程运行或协程(有5种细粒度并发模式,默认是线程,详细看4.5章节的介绍)
如果这个python进程的任务较重,python进程的cpu已经明显很高了,则应该使用多进程叠加线程(协程)并发
4.26.2 在多个进程中启动函数的消费,适合一次启动大量函数的消费或重型任务
假如add和sub是很费cpu的函数,或者一次性启动30个函数的消费,4.26.1的在一个进程中启动多个函数的消费的方式就不合适了。
应该在独立进程中运行函数,这样性能好,突破单进程 无法使用多核心 gil限制,充分使用多核。
add.multi_process_consume(1) # 独立开1个进程,每个进程内部使用多线程运行或协程 来运行求和函数
sub.multi_process_consume(3) # 独立开3个进程来运行求差函数,每个进程内部使用多线程运行或协程 来运行求和函数.
sub函数是开3个进程,每个进程使用多线程并发方式,每个进程内部按照boost装饰器指定的,开了200线程。也就是总共600线程运行sub函数。
3进程,每个进程内部开200线程,比单进程设置600线程岁强很多的。尤其是cpu密集型,多进程优势明显。
要看4.5章节的说明,有的人不看文档,不知道怎么性能达到最好,不知道怎么开多进程,只知道简单demo的 fun.consume()方式启动消费
4.28 funboost 支持celery框架整体作为funboost的broker (2023.4新增)
funboost的api来操作celery,完爆用户亲自操作celery框架。
害怕celery框架用法pythoner的福音。
见11.1章节代码例子,celery框架整体作为funboost的broker,funboost的发布和消费将只作为极简api,核心的消费调度和发布和定时功能,都是由celery框架来完成,funboost框架的发布和调度代码不实际起作用。
用户操作funboost的api,语法和使用其他消息队列中间件类型一样,funboost自动化操作celery。
用户无需操作celery本身,无需敲击celery难记的命令行启动消费、定时、flower;
用户无需小心翼翼纠结亲自使用celery时候怎么规划目录结构 文件夹命名 需要怎么在配置写include 写task_routes,
完全不存在需要固定的celery目录结构,不需要手动配置懵逼的任务路由,不需要配置每个函数怎么使用不同的队列名字,funboost自动搞定这些。
celery框架的一大堆需要用户使用的重要的高频公有核心方法入参声明都是 *agrs,**kwargs,代码无法在ide补全,
并且点击到celery源码方法里面取也没有明确的说明*agrs **kwargs能传递哪些几十个参数,网上的简单demoi例子也不会列举出来各种细节入参,导致一般用户不知道celery能传什么,
比如@app.task的入参、task_fun.apply_async的入参、app.send_task、celery的配置大全 能传哪些,用户无法知道,这种不能再pycharm ide下代码补全的框架可以说是极端的操蛋,
不能代码补全的框架,就算是功能强大也没用,不好使用。还有celery启动work 启动定时 启动flower都需要手敲 cmd 命令行,用户连入参能传哪些控制命令大全都不知道,
所以celery框架对不非常熟练python的人是极端的操蛋。
用户只需要使用简单的funboost语法就能操控celery框架了。funboost使用celery作为broker_kind,远远的暴击亲自使用无法ide下代码补全的celery框架的语法。
funboost通过支持celery作为broker_kind,使celer框架变成了funboost的一个子集
funboost使用broker_kind=BrokerEnum.CELERY作为中间件的代码。
import time
from funboost import boost, BrokerEnum
from funboost.consumers.celery_consumer import CeleryHelper
@boost('celery_q1', broker_kind=BrokerEnum.CELERY, qps=5)
def f1(x, y):
time.sleep(3)
print('哈哈哈', x, y)
return x + y
@boost('celery_q2', broker_kind=BrokerEnum.CELERY, qps=1, )
def f2(a, b):
time.sleep(2)
print('嘻嘻', a, b)
return a - b
if __name__ == '__main__':
for i in range(200):
f1.push(i, i * 2)
f2.push(a=i, b=i * 10)
f1.consume() # 登记celery worker命令需要启动的--queues
f2.consume() # 登记celery worker命令需要启动的--queues
CeleryHelper.realy_start_celery_worker(worker_name='测试celery worker2') # 正正的启动celery worker
11.1章节有更多的funboost 操作celery代码说明,包括原生的celery定时和flower。
4.29 funboost支持任务优先级队列
目前只有 BrokerEnum.REDIS_PRIORITY 和 BrokerEnum.RABBITMQ_AMQPSTORM 两个broker支持队列优先级,选择其他的broker_kind不支持优先级队列。
4.29.1 队列支持优先级的说明:
注意: rabbitmq、celery队列优先级都指的是同一个队列中的每个消息具有不同的优先级,消息可以不遵守先进先出,而是优先级越高的消息越先取出来。
队列优先级其实是某个队列中的消息的优先级,这是队列的 x-max-priority 的原生概念。
队列优先级有的人错误的以为是 queuexx 和queueyy两个队列,以为是优先消费queuexx的消息,这是大错特错的想法。
队列优先级是指某个队列中的每个消息可以具有不同的优先级,不是在不同队列名之间来比较哪个队列名具有更高的优先级。
4.29.2 优先级通俗理解,用食堂打饭比喻:
校食堂有两个打饭窗口a和b。a窗口的排队是声明了支持优先级队列,b窗口的排队是没有声明支持优先级的队列。
声明了支持优先级的打饭窗口a排队可以允许插队,例如校领导优先级是3,老师优先级是2,学生优先级是1。就算是学生先去排队,但校长优先级高,
就算排了100个学生排队长龙打饭,校长在这个a窗口来打饭时候可以插队,优先给校长打饭,只要校领导和老师的饭没打完,学生是不能打饭的。
b打饭窗口由于没有声明支持优先级,任何人来这个b窗口打饭必须老老实实排队,谁先来排队就先给谁打饭,天王老子来了都不可以插队优先打饭。
a窗口和b窗口排队的人是互不影响的,优先级是针对各自的队列。
并不是有的人以为的,a窗口优先级高,b窗口优先级低,只要a窗口有人排队,就不给b窗口的人打饭了,你这样那就是想错了。自己好好搜索rabbitmq的 x-max-priority 概念先。
4.29.3 队列支持任务优先级的代码主要有三点:
第一,如果使用redis做支持优先级的消息队列, @boost中要选择 broker_kind = BrokerEnum.REDIS_PRIORITY,
如果是使用rabbitmq写 BrokerEnum.RABBITMQ_AMQPSTORM。
第二,broker_exclusive_config={'x-max-priority':5} 意思是声明这个队列中的任务消息支持多少种优先级,一般写5就完全够用了,不要写太大了,不需要那么多种级别。
第三,发布消息时候要使用publish而非push,发布要加入参 priority_control_config=PriorityConsumingControlConfig(other_extra_params={'priroty': priority}),
其中 priority 必须是整数,要大于等于0且小于队列声明的x-max-priority。x-max-priority这个概念是rabbitmq的原生概念,celery中也是这样的参数名字。
发布的消息priroty 越大,那么该消息就越先被取出来,这样就达到了打破了先进先出的规律。比如优先级高的消息可以给vip用户来运行函数实时,优先级低的消息可以离线跑批。
4.29.4 队列支持任务优先级的代码如下:
import random
import time
from funboost import boost, PriorityConsumingControlConfig,BrokerEnum
@boost('test_redis_priority_queue4', broker_kind=BrokerEnum.REDIS_PRIORITY, qps=100,concurrent_num=50,broker_exclusive_config={'x-max-priority':4})
def f(x):
time.sleep(60)
print(x)
if __name__ == '__main__':
f.clear()
print(f.get_message_count())
for i in range(1000):
randx = random.randint(1, 4)
f.publish({'x': randx}, priority_control_config=PriorityConsumingControlConfig(other_extra_params={'priroty': randx}))
print(f.get_message_count())
f.consume()
从控制台打印可以看到先print的都是4,最后print的是1,无视了消息的发布顺序,而是以消息的优先级来决定谁先被消费。
4.29.5 消息队列优先级是针对一个queue内消息的,那么怎样才能实现不同函数之间的按优先级运行?
很简单,既然优先级队列指的是一个队列中不同的消息可以具有不同的优先级。那么只要用一个队列就好了。一个总的函数消费消息队列,然后分发调用不同的函数,就可以实现优先运行哪个函数了。
下面例子就是,交替发布1000次 f1 f2 f3函数的消息到 test_priority_between_funs 队列中,但消费时候优先运行f3函数,最后才运行f1函数。通过控制台的打印可以看到。
"""
演示不同的函数,怎么优先消费某个函数。
比如爬虫你想深度优先,那就优先运行爬详情页的函数,发布消息时候把爬详情页函数的优先级设置的priroty更大。
你想广度优先就优先运行爬列表页的函数,发布消息时候把爬列表页函数的优先级设置的priroty更大。
如下代码就是把f3函数的优先级设置成了3,f2的优先级设置成了2,f1的优先级设置成了1,所以先交替发布3000个消息到消息队列中,会优先运行f3函数,最后才运行f1函数。
虽然优先级是针对某一个队列而言,不是针对不同队列的优先级,但只要懂得变通,在下面代码的例子中的 dispatch_fun 函数这样分发调用不同的函数,就可以实现多个函数之间的优先级了。
运行可以发现控制台先打印的都是f3,最后还是f1.
"""
"""
演示不同的函数,怎么优先消费某个函数。
比如爬虫你想深度优先,那就优先运行爬详情页的函数,把爬详情页函数的优先级调大。
你想广度优先就优先运行爬列表页的函数,把爬列表页页函数的优先级调大。
如下代码就是把f3函数的优先级设置成了3,f2的优先级设置成了2,f1的优先级设置成了1,所以先发布3000个消息到消息队列中,会优先运行f3函数,最后才运行f1函数。
优先级是针对某一个队列而言,不是针对不同队列的优先级,但只要懂得变通,在下面代码的例子中的boost_fun函数这样分发调用不同的函数,就可以实现多个函数之间的优先级了。
运行可以发现控制台先打印的都是f3,最后还是f1.
"""
from funboost import boost, PriorityConsumingControlConfig, BrokerEnum
def f1(x, y):
print(f'f1 x:{x},y:{y}')
def f2(a):
print(f'f2 a:{a}')
def f3(b):
print(f'f3 b:{b}')
@boost('test_priority_between_funs', broker_kind=BrokerEnum.RABBITMQ_AMQPSTORM, qps=100, broker_exclusive_config={'x-max-priority': 5})
def dispatch_fun(fun_name: str, fun_kwargs: dict, ):
function = globals()[fun_name]
return function(**fun_kwargs)
if __name__ == '__main__':
dispatch_fun.clear()
for i in range(1000):
dispatch_fun.publish({'fun_name': 'f1', 'fun_kwargs': {'x': i, 'y': i}, },
priority_control_config=PriorityConsumingControlConfig(other_extra_params={'priroty': 1}))
dispatch_fun.publish({'fun_name': 'f2', 'fun_kwargs': {'a': i, }, },
priority_control_config=PriorityConsumingControlConfig(other_extra_params={'priroty': 2}))
dispatch_fun.publish({'fun_name': 'f3', 'fun_kwargs': {'b': i, }, },
priority_control_config=PriorityConsumingControlConfig(other_extra_params={'priroty': 3}))
print(dispatch_fun.get_message_count())
dispatch_fun.consume()
4.30 funboost 远程杀死(取消)任务
之前有的人想远程杀死一个正在运行的任务,或者刚发布消息后后悔了,不想运行那个消息了,现在支持这种功能。 用户无论选择哪种消息队列中间件,想使用远程杀死就必须在funboost_config.py配置好redis连接。
远程杀死任务分两种情况:
1)对于发布后,还没从消息队列中取出来运行的消息,funboost会放弃运行这个消息。
2)对于正在执行中的消息,funboost会杀死正在运行的这个函数消息。
celery如果选择threading并发模式,celery不支持terminate杀死,celery的消费端在收到terminate命令时候会报错,celery多线程并发池没有实现杀死功能。
funboost支持杀死正在运行中的函数消息。
4.30.1 funboost远程杀死函数的代码例子
注意要设置 is_support_remote_kill_task=True,如果不需要远程杀死函数消息的功能,就别设置为True,浪费性能; 因为函数要支持杀死,必须把函数单独运行在一个线程中,杀死这个线程来达到杀死函数的目的。所以非必要别设置 is_support_remote_kill_task=True。
开启 is_support_remote_kill_task=True 适合任务数量少,函数运行耗时非常大的情况; 因为如果函数只需要10秒能运行完,你还没来得及开始写发送远程杀死命令的代码,函数就已经执行完了,杀死了个寂寞。
下面代码是让funboost结束执行求和 3+4。
消费端代码求和:
import time
from funboost import boost
@boost('test_kill_fun_queue', is_support_remote_kill_task=True) # is_support_remote_kill_task=True 要设置为True
def test_kill_add(x, y):
print(f'start {x} + {y} ....')
time.sleep(120)
print(f'over {x} + {y} = {x + y}')
if __name__ == '__main__':
test_kill_add.consume()
发布端代码:
import time
from test_funboost_kill_consume import test_kill_add
from funboost import RemoteTaskKiller
if __name__ == '__main__':
async_result = test_kill_add.push(3,4)
# time.sleep(10)
RemoteTaskKiller(test_kill_add.queue_name,async_result.task_id).send_kill_remote_task_comd() # RemoteTaskKiller 传入要杀死的队列名和消息的taskid
超时杀死控制台截图:

4.30.2 远程强制杀死函数、超时自动杀死(function_timeout设置不为0), 这两个功能要注意死锁:
funboost的多线程并发模式的 function_timeout超时自动杀死 和远程命令来杀死函数都需要注意杀死函数后的锁不释放问题。
1)在消费函数中 with 推荐
with lock:
长耗时代码
在执行长耗时代码块时候,这种函数被强制杀死,不会发生死锁。
2)在消费函数中,lock.acquire() 和 release() 不推荐,
lock.acquire():
长耗时代码
lock.release()
在执行长耗时代码块时候,这种函数被强制杀死,会发生死锁,杀死函数后,消费会一直卡住,所以消费会一直等待这个锁,导致消费无法继续运行。
对于使用锁的建议:
大家尽量使用with语法使用锁,或者锁别加在长耗时代码块上,减少死锁概率。
或使用可过期锁expire_lock。
4.30.2.b 如果想启用funboost函数超时自动杀死功能或者 远程杀死函数功能,推荐消费函数中使用可过期锁 expire_lock
pip install expire_lock
或者 from funboost.utils import expire_lock
expire_lock 使用文档: https://pypi.org/project/expire-lock/
expire_lock 规定了一个锁的最大占用时间,如果达到了最大的expire时间一直没有释放这个锁,会自动过期释放。
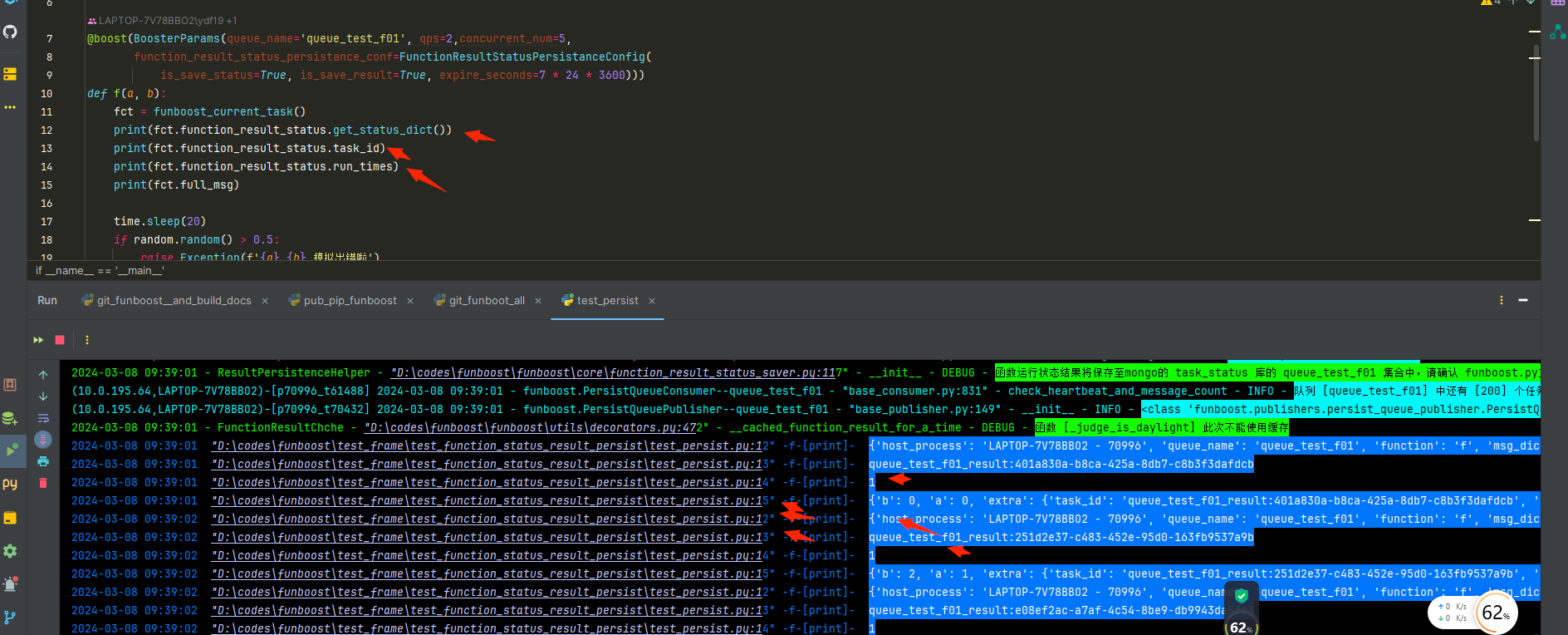
4.31 funboost_current_task 上下文获取当前消息和任务状态
fct = funboost_current_task()
通过fct这个线程/协程 级别的全局变量,可以获取消息的完全体
之前无法在用户的消费函数内部去获取消息的完全体,只能知道函数的入参,无法知道消息的发布时间 taskid等.
用户在任意消费函数中
fct = funboost_current_task()
就能获取当前的任务消息了。
这个功能使得用户在用户函数中就能知道消息的完全体、 当前是哪台机器 、哪个进程、 第几次重试运行函数
消息的发布时间 消息的task_id 等等。
原来用户在消费函数中是无法获取这些信息的。
import random
import time
from funboost import boost, FunctionResultStatusPersistanceConfig,BoosterParams
from funboost.core.current_task import funboost_current_task
@boost(BoosterParams(queue_name='queue_test_fct', qps=2,concurrent_num=5,))
def f(a, b):
fct = funboost_current_task() # 线程/协程隔离级别的上下文
print(fct.function_result_status.task_id) # 获取消息的任务id
print(fct.function_result_status.run_times) # 获取消息是第几次重试运行
print(fct.full_msg) # 获取消息的完全体。出了a和b的值意外,还有发布时间 task_id等。
print(fct.function_result_status.publish_time) # 获取消息的发布时间
print(fct.function_result_status.get_status_dict()) # 获取任务的信息,可以转成字典看。
time.sleep(20)
if random.random() > 0.5:
raise Exception(f'{a} {b} 模拟出错啦')
print(a+b)
return a + b
if __name__ == '__main__':
# f(5, 6) # 可以直接调用
for i in range(0, 200):
f.push(i, b=i * 2)
f.consume()
打印 fct = funboost_current_task() 的截图
4.100 使用funboost时候对框架的疑问和猜测的验证方式
有的人老是一开始学习funboost就用复杂业务函数逻辑来运行,不好调试,不方便表示自己的用法。
应该把自己的想法抽象成 1个简单的 包含 time.sleep 的函数,用简单demo才比较方便表示自己的疑惑和验证自己的猜测。
用户修改boost装饰器的参数 和 函数的sleep 大小 来 测试你想要验证你对框架功能的猜测。
例如你要测试确认消费,框架的broker_kind 为 redis_ack_able是否能做到消息确认消费不丢失消息,那你就可以发布20个任务,并启动消费,
消费函数里面time.sleep(200),然后你在第100秒时候突然把正在运行的消费脚本强行关闭,你就能看到消息被其他消费进程或机器拿运行了。
或者你只有一个脚本在运行,当你下次重新启动脚本时候这些消息也会被消费。
例如你要测试框架是不是能并发运行,那么运行下面的f函数,你设置10线程,那应该每50秒能打印求和10次,设置并发模式为single_thread那么每50秒能打印求和1次。
from funboost import boost
@boost('test_queue', ) # 用户修改boost的参数测试你想要的破欸子效果
def f(x,y):
time.sleep(50) # 用户修改sleep大小测试因函数耗时造成的猜测
print(f'{x} + {y} = {x + y}')
return x +y
if __name__ == '__main__':
for i in range(1000):
time.sleep(0.2)
f.push(i,i*2)
f.consume()
4.100.b 举个例子,验证测试框架的超时杀死 function_timeout参数的作用
有的人老是问超时杀死是不是杀死进程,杀死python脚本。
问的太不用大脑了,默认的 task_fun.consume() 是单进程多线程启动的,如果是杀进程和脚本,那部署脚本相当于自杀结束了,这可能吗?
把脚本杀死了,那就永远无法再消费了,框架怎么可能这么设计为,因为一个函数入参超时而退出程序。
做出这种猜测就不应该了,而且用户自己测试验证这个想法很难吗。
例如下面的求和函数,里面写个sleep,然后设置 function_timeout=20,
框架的各个控制功能都太容易通过写一个简单的sleep 求和函数demo来测试了。
测试脚本:
import random
import time
from funboost import boost
@boost('test_timeout',concurrent_num=5,function_timeout=20,max_retry_times=4)
def add(x,y):
t_sleep = random.randint(10, 30)
print(f'计算 {x} + {y} 中。。。。,需要耗费 {t_sleep} 秒时间')
time.sleep(t_sleep)
print(f'执行 {x} + {y} 的结果是 {x+y} ')
return x+y
if __name__ == '__main__':
for i in range(100):
add.push(i,i*2)
add.consume()
超时运行的截图
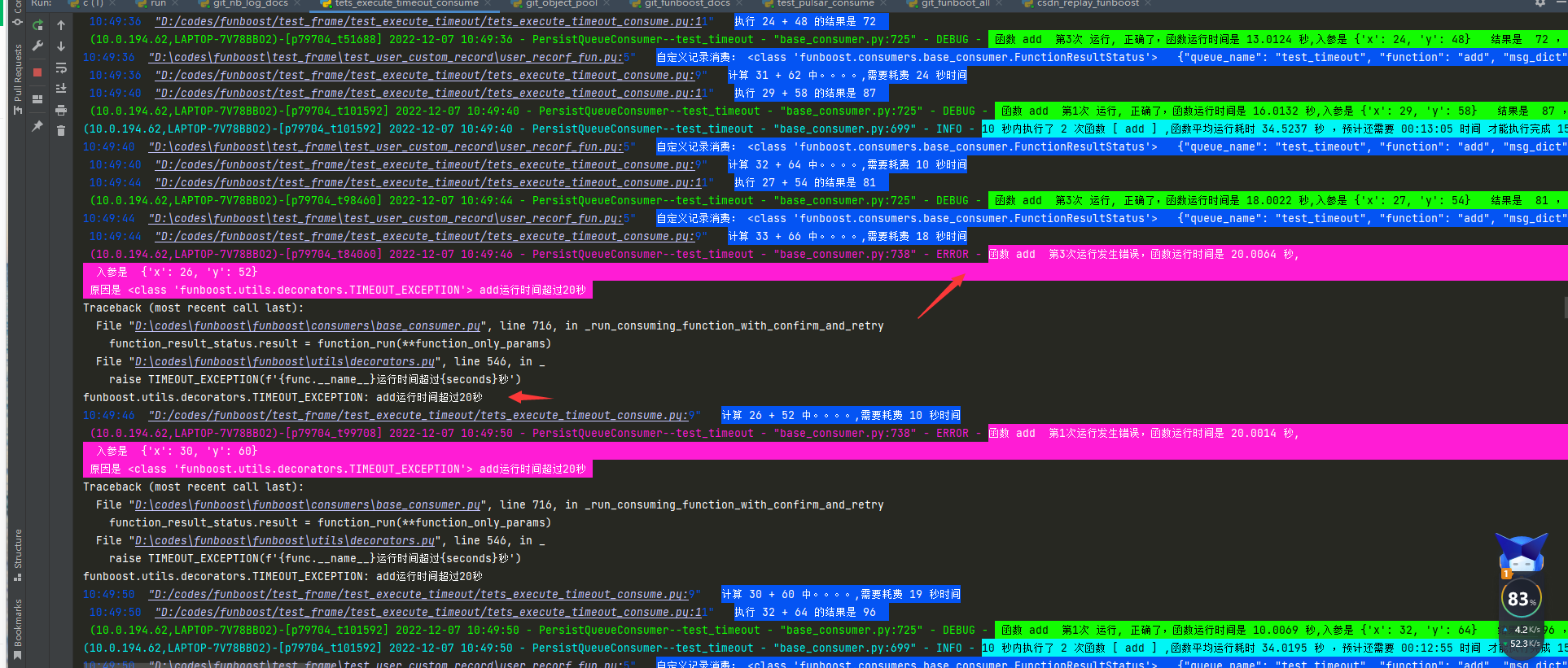
从运行来看就知道了,funboost的function_timeout超时杀死功能,是针对一个正在运行的函数执行参数,是杀死运行中的函数,使函数运行中断结束, 不继续往下运行函数了,不会把自身脚本整个杀死。所以对funboost提供的功能不用猜测,只需要写demo测试就可以了。
4.200 [分布式函数调度框架qq群]
现在新建一个qq群 189603256