6.常见问题回答
直接统一回复常见问题,例如是不是模仿celery
6.1 你干嘛要写这个框架?和celery 、rq有什么区别?
你干嘛要写这个框架?和celery 、rq有什么区别?是不是完全重复造轮子为了装x?
见第二章的2.4章节解释,有接近20种优势。
celery 从性能、用户编码需要的代码量、用户使用难度 各方面都远远差于此框架。
可以使用例子中的场景代码进行了严格的控制变量法实际运行对比验证。
6.2 为什么包的名字这么长?
为什么包的名字这么长,为什么不学celery把包名取成 花菜 茄子什么的?
答: 为了直接表达框架的意思。现在代码在ide都能补全,名字长没关系。
生产消费模式不是celery专利,是通用常见的编程思想,不是必须用水果取名。
6.3 框架是使用什么序列化协议来序列化消息的。
答:框架默认使用json。并且不提供序列化方式选择,有且只能用json序列化。json消息可读性很强,远超其他序列化方式。
默认使用json来序列化和反序列化消息。所以推送的消息必须是简单的,不要把一个自定义类型的对象作为消费函数的入参,
json键的值必须是简单类型,例如 数字 字符串 数组 字典这种。不可以是不可被json序列化的python自定义类型的对象。
用json序列化已经满足所有场景了,picke序列化更强,但仍然有一些自定义类型的对象的实例属性由于是一个不可被序列化
的东西,picke解决不了,这种东西例如self.r = Redis(),而redis对象又包括threding.Lock类型的属性 ,不可以被pike序列化
就算能序列化的对象也是要用一串很长的东西来。
用pike来序列化复杂嵌套属性类型的对象,不仅会导致中间件要存储很大的东西传输效率会降低,在编码和解码也会消耗更多的cpu。如果框架支持了pike序列化,会让使用者养成不好的粗暴习惯。
想消费函数传redis对象作为入参,这种完全可以使用json来解决,例如指定ip 和端口,在消费函数内部来使用redis。所以用json一定可以满足一切传参场景。
如果json不能满足你的消费任务的序列化,那不是框架的问题,一定是你代码设计的问题。所以没有预留不同种类序列化方式的扩展,
也不打算准备加入其他序列化方式。
6.4 框架如何实现定时?
答:使用的是定时发布任务,那么就能定时消费任务了。导入fsdf_background_scheduler然后添加定时发布任务。
FsdfBackgroundScheduler继承自 apscheduler 的 BackgroundScheduler,定时方式可以百度 apscheduler
6.5 为什么强调是函数调度框架不是类调度框架,不是方法调度框架?
为什么强调是函数调度框架不是类调度框架,不是方法调度框架?你代码里面使用了类,是不是和此框架水火不容了?
问的是consuming_function的值能不能是一个类或者一个实例方法。
答:一切对类的调用最后都是体现在对方法的调用。这个问题莫名其妙。
celery rq huery 框架都是针对函数。
调度函数而不是类是因为:
1)类实例化时候构造方法要传参,类的公有方法也要传参,这样就不确定要把中间件里面的参数哪些传给构造方法哪些传给普通方法了。
见5.8
2) 这种分布式一般要求是幂等的,传啥参数有固定的结果,函数是无依赖状态的。类是封装的带有状态,方法依赖了对象的实例属性。
3) 比如例子的add方法是一个是实例方法,看起来好像传个y的值就可以,实际是add要接受两个入参,一个是self,一个是y。如果把self推到消息队列,那就不好玩了。
对象的序列化浪费磁盘空间,浪费网速传输大体积消息,浪费cpu 序列化和反序列化。所以此框架的入参已近说明了,
仅仅支持能够被json序列化的东西,像普通的自定义类型的对象就不能被json序列化了。
celery也是这样的,演示的例子也是用函数(也可以是静态方法),而不是类或者实例方法,
这不是刻意要和celery一样,原因已经说了,自己好好体会好好想想原因吧。
框架如何调用你代码里面的类。
假设你的代码是:
class A():
def __init__(x):
self.x = x
def add(self,y):
return self.x + y
那么你不能 a =A(1) ; a.add.push(2),因为self也是入参之一,不能只发布y,要吧a对象(self)也发布进来。
add(2)的结果是不确定的,他是受到a对象的x属性的影响的,如果x的属性是100,那么a.add(2)的结果是102.
如果框架对实例方法,自动发布对象本身作为第一个入参到中间件,那么就需要采用pickle序列化,picke序列化对象,
消耗的cpu很大,占用的消息体积也很大,而且相当一大部分的对象压根无法支持pickle序列化。
无法支持序列化的对象我举个例子,
import pickle
import threading
import redis
class CannotPickleObject:
def __init__(self):
self._lock = threading.Lock()
class CannotPickleObject2:
def __init__(self):
self._redis = redis.Redis()
print(pickle.dumps(CannotPickleObject())) # 报错,因为lock对象无法pickle
print(pickle.dumps(CannotPickleObject2())) # 报错,因为redis客户端对象也有一个属性是lock对象。
以上这两个对象如果你想序列化,那就是天方夜谭,不可能绝对不可能。
真实场景下,一个类的对象包含了很多属性,而属性指向另一个对象,另一个对象的属性指向下一个对象,
只要其中某一个属性的对象不可pickle序列化,那么此对象就无法pickle序列化。
pickle序列化并不是全能的,所以经常才出现python在win下的多进程启动报错,
因为windows开多进程需要序列化入参,但复杂的入参,例如不是简单的数字 字母,而是一个自定义对象,
万一这个对象无法序列化,那么win上启动多进程就会直接报错。
所以如果为了调度上面的class A的add方法,你需要再写一个函数
def your_task(x,y):
return A(x).add(y)
然后把这个your_task函数传给框架就可以了。所以此框架和你在项目里面写类不是冲突的,
本人是100%推崇oop编程,非常鲜明的反对极端面向过程编程写代码,但是此框架鼓励你写函数而不是类+实例方法。
框架能支持@staticmethod装饰的静态方法,不支持实例方法,因为静态方法的第一个入参不是self。
如果对以上为什么不支持实例方法解释还是无法搞明白,主要是说明没静下心来仔细想想,
如果是你设计框架,你会怎么让框架支持实例方法?
statckflow上提问,celery为什么不支持实例方法加@task
https://stackoverflow.com/questions/39490052/how-to-make-any-method-from-view-model-as-celery-task
celery的作者的回答是:
You can create tasks out of methods. The bad thing about this is that the object itself gets passed around
(because the state of the object in worker has to be same as the state of the caller)
in order for it to be called, so you lose some flexibility. So your object has to be pickled every
time, which is why I am against this solution. Of course this concerns only class methods, s
tatic methods have no such problem.
Another solution, which I like, is to create separate tasks.py or class based tasks and call the methods
from within them. This way, you will have FULL control over Analytics object within your worker.
这段英文的意思和我上面解释的完全一样。所以主要是你没仔细思考想想为什么不支持实例方法。
6.6 是怎么调度一个函数的。
答:基本原理如下
def add(a,b):
print(a + b)
从消息中间件里面取出参数{"a":1,"b":2}
然后使用 add(**{"a":1,"b":2}),就是这样运行函数的。
6.7 框架适用哪些场景?
答:分布式 、并发、 控频、断点接续运行、定时、指定时间不运行、
消费确认、重试指定次数、重新入队、超时杀死、计算消费次数速度、预估消费时间、
函数运行日志记录、任务过滤、任务过期丢弃等数十种功能。
只需要其中的某一种功能就可以使用这。即使不用分布式,也可以使用python内置queue对象。
这就是给函数添加几十项控制的超级装饰器。是快速写代码的生产力保障。
适合一切耗时的函数,不管是cpu密集型 还是io密集型。
不适合的场景主要是:
比如你的函数非常简单,仅仅只需要1微妙 几十纳秒就能完成运行,比如做两数之和,print一下hello,这种就不是分需要使用这种框架了,
如果没有解耦的需求,直接调用这样的简单函数她不香吗,还加个消息队列在中间,那是多此一举。
6.8 怎么引入使用这个框架?门槛高不高?
答:先写自己的函数(类)来实现业务逻辑需求,不需要思考怎么导入框架。
写好函数后把 函数和队列名字绑定传给消费框架就可以了。一行代码就能启动分布式消费。
在你的函数上面加@boost装饰器,执行 your_function.conusme() 就能自动消费。
所以即使你不想用这个框架了,你写的your_function函数代码并没有作废。
所以不管是引入这个框架 、废弃使用这个框架、 换成celery框架,你项目的99%行 的业务代码都还是有用的,并没有成为废物。
别的框架如flask换django,scrapy换spider,代码形式就成了废物。
6.9 怎么写框架?
答: 需要学习真oop和36种设计模式。唯有oop编程思想和设计模式,才能持续设计开发出新的好用的包甚至框架。
如果有不信这句话的,你觉得可以使用纯函数编程,使用0个类来实现这样的框架。
如果完全不理会设计模式,实现threding gevent evenlet 3种并发模式,加上10种中间件类型,实现分布式消费流程,
需要反复复制粘贴扣字30次。代码绝对比你这个多。例如基于nsq消息队列实现任务队列框架,加空格只用了80行。
如果完全反对oop,需要多复制好几千行来实现。
例如没听说设计模式的人,在写完rabbitmq版本后写redis版本,肯定十有八九是在rabbitmq版本写完后,把整个所有文件夹,
全盘复制粘贴,然后在里面扣字母修改,把有关rabbitmq操作的全部扣字眼修改成redis。如果某个逻辑需要修改,
要在两个地方都修改,更别说这是10几种中间件,改一次逻辑需要修改10几次。
我接手维护得老项目很多,这种写法的编程思维的是特别常见的,主要是从来没听说设计模式4个字造成的,
在我没主动学习设计模式之前,我也肯定会是这么写代码的。
只要按照36种设计模式里面的oop4步转化公式思维写代码三个月,光就代码层面而言,写代码的速度、流畅度、可维护性
不会比三年经验的老程序员差,顶多是老程序员的数据库 中间件种类掌握的多一点而已,这个有机会接触只要花时间就能追赶上,
但是编程思维层次,如果没觉悟到,可不是那么容易转变的,包括有些科班大学学过java的也没这种意识,
非科班的只要牢牢抓住把设计模式 oop思维放在第一重要位置,写出来的代码就会比科班好,
不能光学 if else 字典 列表 的基本语法,以前我看python pdf资料时候,资料里面经常会有两章以上讲到类,
我非常头疼,一看到这里的章节,就直接跳过结束学习了,现在我也许只会特意去看这些章节,
然后看资料里面有没有把最本质的特点讲述好,从而让用户知道为什么要使用oop,而不是讲下类的语法,这样导致用户还是不会去使用的。
你来写完包括完成10种中间件和3种并发模式,并且预留消息中间件的扩展。
然后我们来和此框架 比较 实现框架难度上、 实现框架的代码行数上、 用户调用的难度上 这些方面。
6.10 框架能做什么
答:你在你的函数里面写什么,框架就是自动并发做什么。
框架在你的函数上加了自动使用消息队列、分布式、自动多进程+多线程(协程)超高并发、qps控频、自动重试。
只是增加了稳定性、扩展性、并发,但做什么任务是你的函数里面的代码目的决定的。
只要是你代码涉及到了使用并发,涉及到了手动调用线程或线程池或asyncio,那么就可以使用此框架,
使你的代码本身里面就不需要亲自操作任何线程 协程 asyncio了。
不需要使用此框架的场景是函数不需要消耗cpu也不需要消耗io,例如print("hello"),如果1微秒就能完成的任务不需要使用此框架。
6.11 日志的颜色不好看或者觉得太绚丽刺瞎眼,想要调整。
一 、关于日志颜色是使用的 \033实现的,控制台日志颜色不光是颜色代码决定的,最主要还是和ide的自身配色主题有关系,
同一个颜色代码,在pycahrm的十几个控制台颜色主题中,表现的都不一样。
所以代码一运行时候就已经能提示用户怎么设置优化控制台颜色了,文这个问题说明完全没看控制台的提示。
"""
1)使用pycharm时候,建议重新自定义设置pycharm的console里面的主题颜色。
设置方式为 打开pycharm的 file -> settings -> Editor -> Color Scheme -> Console Colors 选择monokai,
并重新修改自定义6个颜色,设置Blue为1585FF,Cyan为06B8B8,Green 为 05A53F,Magenta为 ff1cd5,red为FF0207,yellow为FFB009。
2)使用xshell或finashell工具连接linux也可以自定义主题颜色,默认使用shell连接工具的颜色也可以。
颜色效果如连接 https://imgse.com/i/pkFSfc8
在当前项目根目录的 nb_log_config.py 中可以修改当get_logger方法不传参时后的默认日志行为。
"""
二、关于日志太绚丽,你觉得不需要背景色块,在当前项目根目录的 nb_log_config.py 中可以设置
DISPLAY_BACKGROUD_COLOR_IN_CONSOLE = False # 在控制台是否显示彩色块状的日志。为False则不使用大块的背景颜色。
6.12 是不是抄袭模仿 celery
答:有20种优势,例如celery不支持asyncio、celery的控频严重不精确,光抄袭解决不了。比celery有20项提升,具体看2.4章节
我到现在也只能通过实际运行来达到了解推车celery的目的,并不能直接默读代码就搞懂。
celery的层层继承,特别是层层组合,又没多少类型提示,说能精通里面每一行源码的人,多数是高估自己自信过头了。
celery的代码太魔幻,不运行想默读就看懂是不可能的,不信的人可以把自己关在小黑屋不吃不喝把celery源码背诵3个月,
然后3个月后 试试默写能不能写出来实现里面的兼容 多种中间件 + 多种并发模式 + 几十种控制方式的框架。
这是从一个乞丐版精简框架衍生的,加上36种设计模式付诸实践。
此框架运行print hello函数, 性能强过celery 20倍以上(测试每秒消费次数,具体看我的性能对比项目)。
此框架支持的中间件比celery多
此框架引用方式和celery完全不一样,完全不依赖任何特定的项目结构,celery门槛很高。
此框架和celery没有关系,没有受到celery启发,也不可能找出与celery连续3行一模一样的代码。
这个是从原来项目代码里面大量重复while 1:redis.blpop() 发散扩展的。
这个和celery唯一有相同点是,都是生产者 消费者 + 消息队列中间件的模式,这种生产消费的编程思想或者叫想法不是celery的专利。
包括我们现在java框架实时处理数据的,其实也就是生产者 消费者加kfaka中间件封装的,难道java人员开发框架时候也是需要模仿一下python celery源码或者思想吗。
任何人都有资格开发封装生产者消费者模式的框架,生产者 消费者模式不是celery专利。生产消费模式很容易想到,不是什么高深的架构思想,不需要受到celery的启发才能开发。
6.13 使用此框架时候,在一个python项目中如何连接多个相同种类的消息队列中间件ip地址
这个问题是问一个项目中,有些脚本要连接 192.168.0.1的redis ,有些脚本要连接192.168.0.2的redis,但框架配置文件只有一个,如何解决?
例如目录结构是
your_proj/
funboost_config.py (此文件是第一次启动任意消费脚本后自动生成的,用户按需修改配置)
dira/a_consumer.py (此脚本中启动funa函数消费)
dirb/b_consumer.py (此脚本中启动funb函数消费)
如果funa函数要连接 192.168.0.1的redis,funb函数要连接192.168.0.2的redis,有两种解决方式
第一种是在启动消费的脚本,脚本里面手动调用 patch_frame_config()函数来设置各种中间件的值
第二种是 把 funboost_config.py 分别复制到dira和dirb文件夹.
这种就会自动优先使用 a_consumer.py和b_consumer.py同文件夹层级的配置了,
而非是自动优先读取python项目根目录的配置文件,这个是利用了python语言的import 模块导入优先级机制。
6.14 什么是确认消费?为什么框架总是强调确认消费?
发布端:
from scripxx import fun
for i in range(10):
fun.push(i)
消费端:
import time
from funboost import boost
@boost('test_confirm')
def fun(x):
print(f'开始处理 {x}')
time.sleep(120)
print(f'处理完成 {x}')
fun.consume()
启动消费脚本后,任意时刻随意强制反复关闭重启消费代码,只要函数没有完整的执行完成,函数参数就不会丢失。达到了消息万无一失。
具体的那些中间件消费者支持消费确认,具体见 3.1 介绍。
实现了4种redis消息队列中间件,其中有3种是确认消费的。
确认消费很重要,如果你自己写个简单粗暴的 while 1:redis.blpop()的脚本,你以为是可以断点接续呢,
在多线程并发执行函数时候,大量的消息会丢的很惨。导致虽然是断点接续但你不敢随意重启。
6.15 如何等待队列中的消息全部消费完成
如果有这种需求需要等待消费完成,使用 wait_for_possible_has_finish_all_tasks()
f.consume()
f.wait_for_possible_has_finish_all_tasks(minutes=3) # 框架提供阻塞方法,直至队列任务全部消费完成,才会运行到下一行。
print("over") # 如果不加上面那一行,这个会迅速打印over
6.16 框架支不支持函数上加两个装饰器?
由于发布任务时候需要自动精确组装入参字典,所以不支持 *args **kwargs形式的入参,不支持叠加两个@装饰器
想在消费函数加装饰器,通过 boost 装饰器的 consumin_function_decorator 入参指定装饰器函数就行了。
那么如果是想叠加3个装饰器怎么写,例如本来想:
@boost('queue666')
@deco1('hello')
@deco2
def task_fun(x,y):
...
那就是写成 consumin_function_decorator=deco1('hello')(deco2) 就可以了,具体要了解装饰器的本质就知道,叠加100个装饰器都可以。
如下的例子是使用redis的incr命令统计每台机器ip 总共运行了多少次函数。
import inspect
import nb_log
from funboost import boost
from funboost.utils.redis_manager import RedisMixin
from functools import wraps
def incr_deco(redis_key):
def _inner(f):
@wraps(f)
def __inner(*args, **kwargs):
result = f(*args, **kwargs)
RedisMixin().redis_db_frame.incr(redis_key)
# mongo_col.insert_one({'result':result,'args':str(args),'kwargs':str(kwargs)})
return result
return __inner
return _inner
@boost('test_queue_235',consumin_function_decorator=incr_deco(nb_log.nb_log_config_default.computer_ip))
def fun(xxx, yyy):
print(xxx + yyy)
return xxx + yyy
if __name__ == '__main__':
print(inspect.getfullargspec(fun))
for i in range(10):
fun.push(i, 2 * i)
fun.consume()
6.17 嫌框架日志记录太详细?
6.17.a 设置发布者消费者的日志级别,控制是否显示发布了什么消息和消费了什么消息.
日志是了解当前框架正在运行什么的好手段,不然用户懵逼不知道背后在发生执行什么。
@boost 装饰器设置 log_level=20 或logging.INFO,就不会再记录框架正在运行什么函数了。
如图再装饰器加上 log_level=20后,框架以后就再也不会记录框架正在运行什么函数入参结果是什么了。
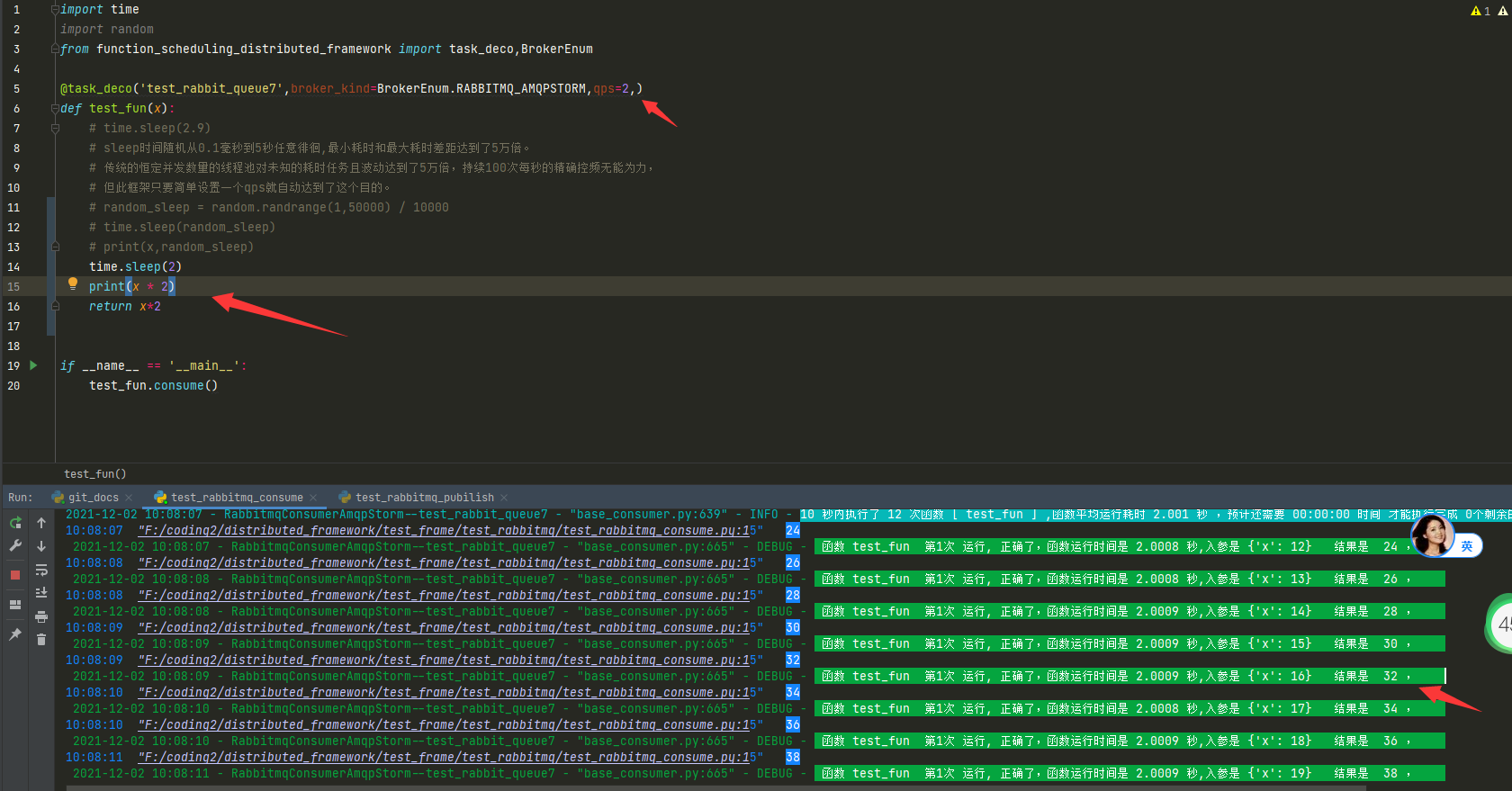
@boost 装饰器设置 log_level=20 只是控制消费者和发布者命名空间自身的日志的,不是控制所有命名空间的日志的, 有些人到现在不清楚,不同的命名空间的logger是可以设置不同的日志级别和handlers的,这要学习logging基础了.
6.17b 嫌funboost启动时候打印太多提示用户的消息?
答: 主要是提示用户怎么设置配置文件,和读取的配置文件路径是什么,读取的配置内容是什么,免得用户丈二和尚摸不着头脑,不知道自己的配置是什么.
因为很多python人员,到现在完全不清楚 PYTHONPATH 这个重要概念,说了几百遍这个概念很重要,这么基础的又不学习,
还嫌弃提示你funboost_config配置麻烦,建议不懂PYTHONPATH的人不要屏蔽启动时候的打印提示了.
老手可以通过设置日志级别来屏蔽funboost_config的配置提示.
修改你的funboost_config.py的FunboostCommonConfig的配置,可以设置一些命名空间的日志级别,去掉启动时候的提示
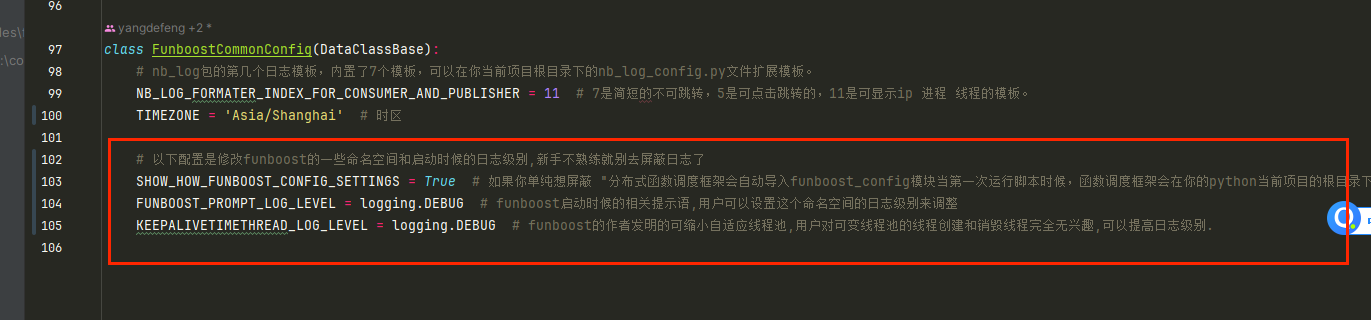
class FunboostCommonConfig(DataClassBase):
# nb_log包的第几个日志模板,内置了7个模板,可以在你当前项目根目录下的nb_log_config.py文件扩展模板。
NB_LOG_FORMATER_INDEX_FOR_CONSUMER_AND_PUBLISHER = 11 # 7是简短的不可跳转,5是可点击跳转的,11是可显示ip 进程 线程的模板。
TIMEZONE = 'Asia/Shanghai' # 时区
# 以下配置是修改funboost的一些命名空间和启动时候的日志级别,新手不熟练就别去屏蔽日志了
SHOW_HOW_FUNBOOST_CONFIG_SETTINGS = False # 如果你单纯想屏蔽 "分布式函数调度框架会自动导入funboost_config模块当第一次运行脚本时候,函数调度框架会在你的python当前项目的根目录下 ...... " 这句话,
FUNBOOST_PROMPT_LOG_LEVEL = logging.INFO # funboost启动时候的相关提示语,用户可以设置这个命名空间的日志级别来调整
KEEPALIVETIMETHREAD_LOG_LEVEL = logging.INFO # funboost的作者发明的可缩小自适应线程池,用户对可变线程池的线程创建和销毁线程完全无兴趣,可以提高日志级别.
屏蔽日志级别前:
屏蔽日志级别后:
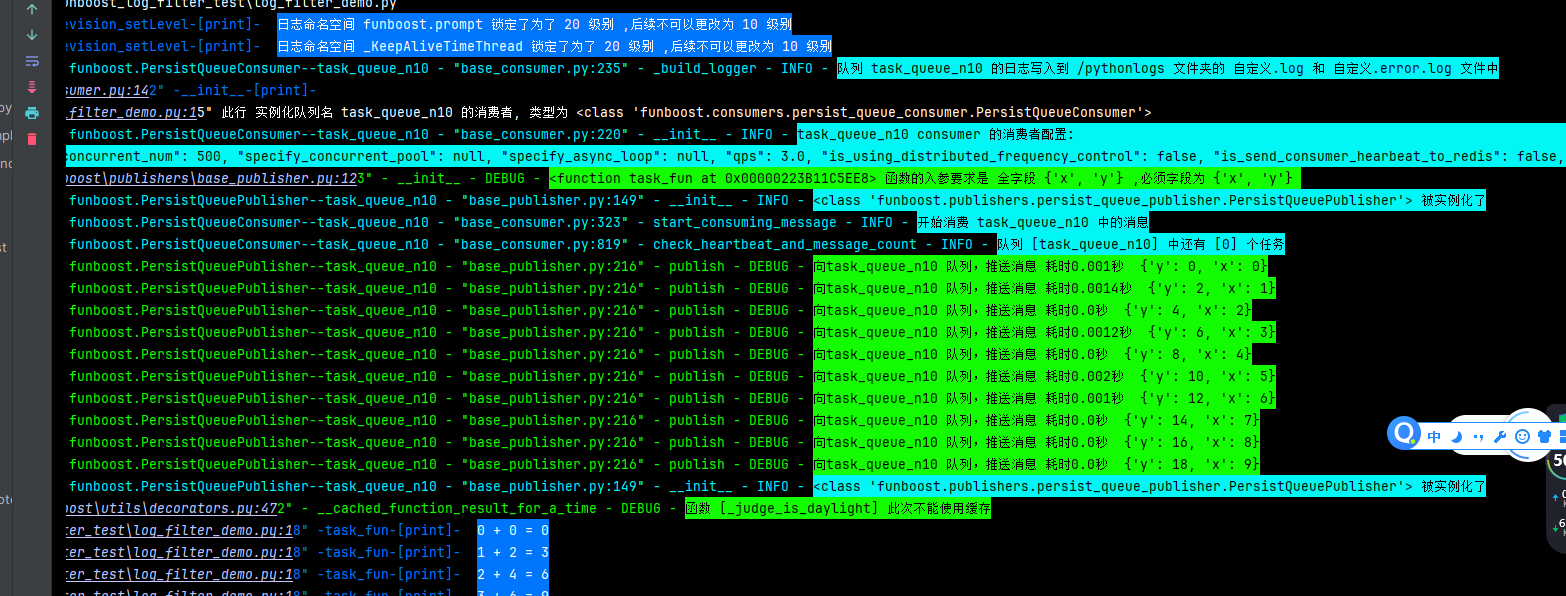
6.18 为什么框架在cmd shell终端运行时候要求会话中设置环境变量 export PYTHONPATH=你的项目根目录?
有的人写了三四年的python代码,连PYTHONPATH作用和概念都没听说过,真的很悲剧
如果是下面的 pythonpathdemo是一个python项目根目录,pycharm以项目方式打开这个文件夹。
你会发现run5.py在pycahrm可以运行,在cmd中无法运行,因为无法找到d1包,笨瓜会硬编码操作sys.path.insert非常的愚蠢,
这种笨瓜主要是写代码一意孤行,导致不学习PYTHONPATH。
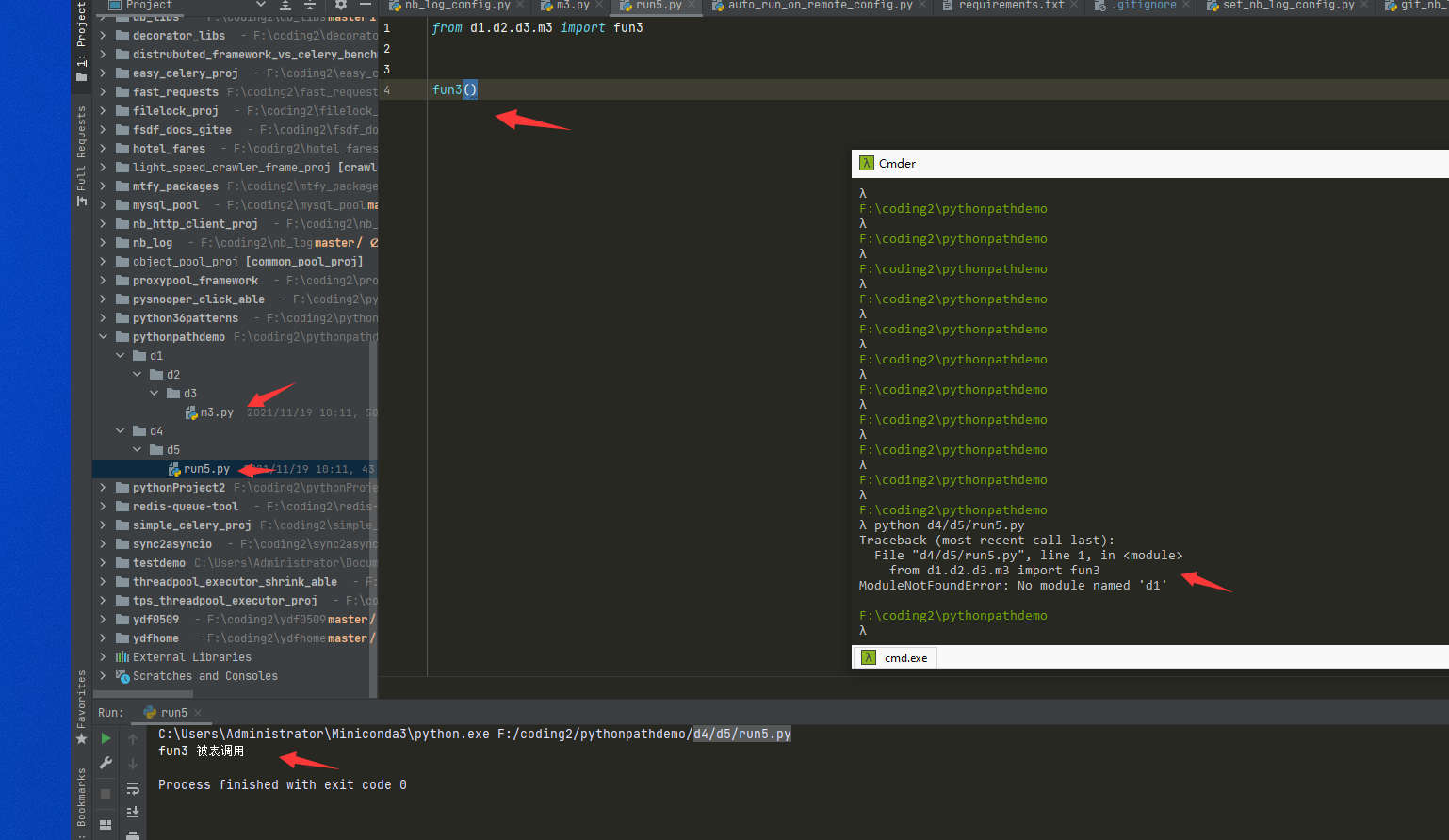
完整讲解pythonpath重要性文章在:
https://github.com/ydf0509/pythonpathdemo
一句命令行解决设置 pythonpath 和运行 python脚本
一定要设置的是临时终端会话级pythonpath,不要设置到配置文件写死永久固定环境变量
例如你的项目根目录是 /home/xiaomin/myproj/
你的运行起点脚本在 /home/xiaomin/myproj/dir2/dir3/run_consume6.py
一句话就是
linux: export PYTHONPATH=/home/xiaomin/myproj/; python3 /home/xiaomin/myproj/dir2/dir3/run_consume6.py
win的cmd:假设代码在d盘先切换到盘符d盘 d:/ 。 然后 set PYTHONPATH=/codes2022/myproj/ & python3 /codes2022/myproj/dir2/dir3/run_consume6.py
win10和11的powershell: 假设代码在d盘先切换到盘符d盘 d:/。然后 $env:PYTHONPATH="/codes2022/myproj/"; python3 /codes2022/myproj/dir2/dir3/run_consume6.py
压根不要敲击两次命令行好不。
如果你已经cd切换到项目根目录myproj了,那就 export PYTHONPATH=./;python3 dir2/dir3/run_consume6.py
6.18.2 为什么celery scrapy django不需要用户设置pythonpath?
因为这些框架都是固定死用户的项目目录解构,项目运行起点有固定的唯一脚本,而且该脚本在项目跟目录的第一个直接层级。
例如django scrapy ,他的命令行启动,你必须先cd 到项目的根目录再运行命令行。
而此框架是为了兼容用户的cmd命令当前文件夹在任意文件夹下,就可以运行你项目下的任意多层级深层级下的脚本。
用户设置了pythonpath后,可以cd到任意文件夹下,再运行 python /dir1/dir2/xxx.py 任然能正确的import。
如果用户能够保证他要python启动运行的脚本始终是放在了项目的第一层级目录下面,当然可以不用设置 PYTHONPATH了。
6.18.3 怎么指定配置文件读取 funboost_config.py 和nb_log_config.py的文件夹位置
默认就是放在项目根目录,然后设置 export PYTHONPATH=你的项目根目录, (linux win+cmd win+powershell 设置临时会话的环境变量语法不一样,6.18已经介绍了)
如果要指定读取的配置文件的存放位置为别的文件夹,也很容易,归根结底还是要精通PYTHONPATH的作用。
例如你的项目根目录是 /home/codes/proj ,你不想使用项目根目录下的配置文件,想读取别的文件夹的配置文件作为funboost的中间件配置。
假设你的文件夹是 /home/xiaomin/conf_dir ,里面有 funboost_config.py ,如果你的/home/codes/proj 项目想使用 /home/xiaomin/conf_dir/funboost_config.py
作为配置文件, 那就 export PYTHONPATH=/home/xiaomin/conf_dir:/home/codes/proj
也就是意思添加两个文件夹路径到 PYTHONPATH
因为funboost是尝试导入import funboost_config.py 只要能import 到就能读取到,所以只要你把文件夹添加到PYTHONPATH环境变量就可以了(可以print sys.path来查看这个数组)
归根结底是要懂PYTHONPATH,有的人老是不懂PYTHONPATH作用,不愿意认真看 https://github.com/ydf0509/pythonpathdemo ,非常杯具。
6.18.4 怎么根据不同环境使用不同的funboost_config配置文件?
框架获取配置的方式就是直接import funboost_config,然后将里面的值覆盖框架的 funboost_config_deafult.py 值。
为什么能import 到 funboost_config,是因为要求export PYTHONPATH=你的项目根目录,然后第一次运行时候自动生成配置文件到项目根目录了。
假设你的项目根目录是 /data/app/myproject/
方案一:利用python导入机制,自动import 有PYTHONPATH的文件夹下的配置文件。
例如你在 /data/config_prod/ 放置 funboost_config.py ,然后shell临时命令行 export PYTHONPATH=/data/config_prod/:/data/app/myproject/,再python xx.py。 (这里export 多个值用:隔开,linux设置环境变量为多个值的基本常识无需多说。)
这样就能自动优先使用/data/config_prod/里面的funboost_config.py作为配置文件了,因为import自动会优先从这里。
然后在测试环境 /data/config_test/ 放置 funboost_config.py,然后shell临时命令行 export PYTHONPATH=/data/config_test/:/data/app/myproject/,再python xx.py。
这样测试环境就能自动使用 /data/config_test/ 里面的funboost_config.py作为配置文件了,因为import自动会优先从这里。
方案二:
直接在funboost_config.py种写if else,if os.get("env")=="test" REDIS_HOST=xx ,if os.get("env")=="prod" REDIS_HOST=xx ,
因为配置文件本身就是python文件,所以非常灵活,这不是.ini或者 .yaml文件只能写静态的死字符串和数字,
python作为配置文件优势本来就很大,里面可以写if else,也可以调用各种函数,只要你的模块下包含那些变量就行了。
6.18.5 多个ptyhon项目怎么使用同一个funboost_config.py 作为配置文件
还是因为不懂 PYTHONPATH 造成的,需要我无数次举例说明。 这样太low了,这么多python人员到现在还不知道 PYTHONPATH作用, python导入一个模块是怎么去查找的。
6.18 开头就说了 pythonpathdemo 项目连接,有的人不懂PYTHONPATH又不看这个博客。死猪不怕开水烫,永远不学习 PYTHONPATH 的强大作用。
假设你想每隔项目都使用 /data/conf/funboost_config.py 这一个相同的 funboost_config 作为配置文件,
你有两个python项目在 /data/codes/proj1 和 /data/codes/proj2,
你运行proj1的项目脚本前,只需要 export PYTHONPATH=/data/conf/:/data/codes/proj1 ,然后运行proj1项中的脚本 python dir1/dir2/xx.py
你运行proj2的项目脚本前,只需要 export PYTHONPATH=/data/conf/:/data/codes/proj2 ,然后运行proj2项中的脚本 python dir3/dir4/yy.py
因为你设置了/data/conf/ 为 pythonpath后,那么funboost在 import funboost_config 时候就能自动 import 到 /data/conf/下的 funboost_config.py 模块了。
funboost控制台都打印了 读取的是什么文件作为配置文件了。
归根结底问这个问题的人是完全不懂 PYTHONPATH.
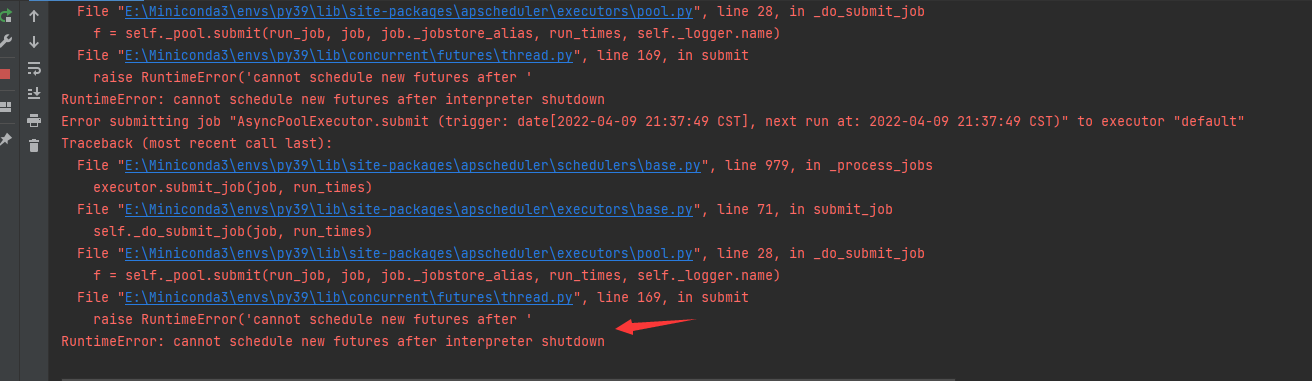
6.19 定时任务或延时任务报错 RuntimeError: cannot schedule new futures after interpreter shutdown
如下图所示,运行定时任务或延时任务在高版本python报错,可以在代码末尾加个while 1:time.sleep(10)
因为程序默认是 schedule_tasks_on_main_thread=False,为了方便连续启动多个消费者消费,
没有在主线程调度运行,自己在代码结尾加个不让主线程结束的代码就行了。
在消费启动的那个代码末尾加两行
while 1:
time.sleep(10)
6.21 支不支持redis cluster集群模式的redis作为消息队列?
此框架没有实现操作redis集群模式,
但只要是celery能支持的中间件类型和redis模式,此框架都能支持。因为此框架支持kombu包操作消息队列。
此框架能够支持的中间件类型比celery只会多不会少,因为框架支持celery的依赖kombu操作各种消息队列。
在funboost_config.py 配置文件中设置 KOMBU_URL 的值了,如
KOMBU_URL = 'sentinel://root:redis@localhost:26079;sentinel://root:redis@localhost:26080;sentinel://root:redis@localhost:26081'
KOMBU_URL 的规则就是 celery的 broker_url的规则。KOMBU_URL支持多种消息队列,celery的broker_url能设置什么样,KOMBU_URL就能设置什么样,
网上大把的资料celery 配置各种broker_url 来操作如 mysql rabbimtq redis 作为消息队列。。
如下这么写,就能使用kombu包来操作各种消息队列了。
@boost("queue_namexx",broker_kind=BrokerEnum.KOMBU)
def add(a,b):
print(a+b)
6.22 怎么使用tcp socket 作为消息队列
见 7.19章节,或者在文档的搜索框输入 tcp 或者 socket 就能搜到了。框架文档支持搜索。
git的 test_frame 文件夹的各种文件夹,是测试脚本也是学习脚本,测试各种中间件的都有。
6.23 安装包时候自动安装的三方依赖包太多?
1.安装第三方包是自动的,又不需要手动一个个指令安装,安装多少三方包都没关系。
2.所有三方包加起来还不到30M,对硬盘体积无影响。
3.只要指定阿里云pip源安装,就能很快安装完,30秒以内就安装完了,又不是需要天天安装。
pip install funboost -i https://mirrors.aliyun.com/pypi/simple/
4.三方包与自己环境不一致问题?
用户完全可以自由选择任何三方包版本。例如你的 sqlalchemy pymongo等等与框架需要的版本不一致,你完全可以自由选择任何版本。
我开发时候实现了很多种中间件,没有时间长期对每一种中间件三方包的每个发布版本都做兼容测试,所以我固定死了。
用户完全可以选择自己的三方包版本,大胆点,等报错了再说,不出错怎么进步,不要怕代码报错,请大胆点升级你想用的版本。
如果是你是用你自己项目里面的requirements.txt方式自动安装三方包,我建议你在文件中第一行写上 funboost,之后再写其它包
这样就能使用你喜欢的版本覆盖funboost框架依赖的版本了。
等用的时候报错了再说。一般不会不兼容报错的请大胆点。
5.为什么要一次性安装完,而不是让用户自己用什么再安装什么?
是为了方便用户切换尝试各种中间件和各种功能时候,不需要自己再亲自一个个安装第三方包,那样手动一个个安装三方包简直是烦死了。
6.23.b 作者为什么不开发pip 选装方式?例如实现选装 pip install funboost[rabbitmq]
这个你是怎么知道funboost作者没有使用选装方式的? 你是怎么知道作者没有掌握 pip 中括号选装依赖包 技术方式的?
用户可以看看setup.py里面的 extras_require里面,有没有开发选装方式? pip funboost[all] 才是安装所有依赖.
作者去掉依赖很容易,已经实现了, funboost/factories/broker_kind__publsiher_consumer_type_map.py 中的 regist_to_funboost 就是动态导入生产者消费者,很容易去掉各种三方包依赖,
但是很容易安装的三方包,我是不会去做成选装的,没有那个必要,自己设置pip 国内源,30秒就能安装完成funboost了,不需要去纠结这个依赖包多少的问题.
6.24 funboost框架从消息队列获取多少条消息?有没有负载均衡?
funboost 每个消费者进程会从消息队列获取 并发个数 n + 10 条消息,每个消费者实现有差异,一般不会超过并发数2倍。
所以不会造成发布10万条消息后,再a b机器启动2个消费,b机器一直无法消费,全部a机器消费,不会出现这种情况。
如果你只发布6条消息,先在a机器启动消费,下一秒启动b机器,那很有可能b机器无法获取到消息。只要消息数量够多,不会出现忙的忙死,闲的闲死。
例如框架的默认并发方式使线程池,内置了一个有10大小的界队列queue,同时还有n个并发线程正在运行消息,所以每个消费者会获取很多消息在python内存中。
但不会出现一个消费者进程获取了1000条以上的消息,导致站着某坑不拉屎,别的消费进程没办法消费的情况。
如果你是重型任务,希望不预取,每台机器只获取一条消息运行,可以设置并发模式为 SINGLE_THREAD 模式,
boost装饰器设置 concurrent_mode=ConcurrentModeEnum.SINGLE_THREAD,这样在a b 两台机器都没有内存缓冲队列,只会一次获取一条消息执行,不预取。