11 funboost 使用某些中间件或三方任务队列框架作为broker的例子(包括celery框架)。
第4章列举了所有funboost用法和场景,第11章补充一些小众中间件的用法
funboost 强大的扩展性,不仅支持各种消息队列还能支持各种不同写法的任务框架作为 broker_kind ,框架扩展性 开放性已然无敌
下面的项目中,演示funboost自动化操作celery复杂不规则项目目录时候怎么完虐用户亲自使用celery
https://github.com/ydf0509/funboost_support_celery_demo
11.1 使用celery作为funboost的中间件
害怕celery框架用法pythoner的福音。用户无需接触celery的任务路由配置和celery对象实例,就可以自动使用celery框架来调度函数。
使用celery作为中间件,用户需要在 funboost_config.py 配置
CELERY_BROKER_URL(必须) 和 CELERY_RESULT_BACKEND (可以为None)
用户想使用celery作为funboost的消息队列,需要安装pip install celery,flower
用户不需要手写 celery 的 @app.task 了,不需要怎么小心翼翼规划文件夹层级和模块名字了
funboost + broker_kind=BrokerEnum.CELERY 设计的精髓所在——通过一个简单、统一的 @boost API,将复杂、繁琐的 Celery 配置和启动流程完全自动化和隐藏起来。
开发者从此可以:
专注业务逻辑:只写函数,用
@boost标记。享受 Celery 的强大:依然使用 Celery 的 worker、beat、result backend 等成熟稳定的执行引擎。
摆脱框架束缚:不再被所谓的“最佳实践”目录结构所限制。
这不仅极大地提升了开发效率,也降低了新团队成员的学习成本,是真正意义上的“化繁为简”。
11.1.1 funboost启动celery消费和定时和flower
test_celery_beat_consume.py
from celery.schedules import crontab
from datetime import timedelta
import time
from funboost import boost, BrokerEnum, BoosterParams
from funboost.assist.celery_helper import CeleryHelper,celery_app
@boost(BoosterParams(queue_name='celery_beat_queue_7a2', broker_kind=BrokerEnum.CELERY, qps=5))
def f_beat(x, y):
time.sleep(3)
print(1111, x, y)
return x + y
# celery_task_config 就是 celery app.task装饰器的原生入参,是任务函数配置。
# 如果要更新app的配置,例如使用 CeleryHelper.update_celery_app_conf({'result_expires':3600*48,'worker_concurrency':100})
@boost(BoosterParams(queue_name='celery_beat_queueb_8a2', broker_kind=BrokerEnum.CELERY, qps=1, broker_exclusive_config={'celery_task_config': {'default_retry_delay':60*5}}))
def f_beat2(a, b):
time.sleep(2)
print(2222, a, b)
return a - b
beat_schedule = { # 这是100% 原汁原味的celery 定时任务配置方式
'add-every-10-seconds_job': {
'task': f_beat.queue_name,
'schedule': timedelta(seconds=10),
'args': (10000, 20000)
},
'celery_beat_queueb_8_jobxx': {
'task': f_beat2.queue_name,
'schedule': timedelta(seconds=20),
# 'schedule': crontab(minute=30, hour=16),
'kwargs': {'a': 20, 'b': 30}
}
}
if __name__ == '__main__':
"""
下面代码直接在代码中启动了 worker 和 beat 和 flower ,永远无需用户在 xhsell 和cmd 敲击复杂的 celery命令行,而只需要普通的 python xx.py 来启动。。
绝大多数 Celery 的入门教程和博客文章,都会重点介绍如何通过命令行来启动 Celery worker、Celery beat 以及 Flower。
例如 celery -A your_project worker -l INFO、celery -A your_project beat -l INFO 和 celery flower --broker=your_broker_url 等,
这些命令行操作是 Celery 官方推荐的标准启动方式,也是最直接的上手途径。
然而,关于如何以编程方式(即在 Python 脚本内部)启动和管理这些组件的教程相对较少,或者被认为是更高级的用法,普通博客可能不会详细记录。
funboost作者能做到无需命令行中使用celery命令来启动这些,恰好打脸了那些质疑ydf0509是因为学不会复杂的celery 用法才重复造轮子写个funboost出来。
"""
CeleryHelper.start_flower(5556) # 启动flower 网页,这个函数也可以单独的脚本中启动
CeleryHelper.celery_start_beat(beat_schedule) # 配置和启动定时任务,这个函数也可以在单独的脚本中启动,但脚本中需要 先import 导入@boost装饰器函数所在的脚本,因为@boost时候consumer的custom_init中注册celery任务路由,之后才能使定时任务发送到正确的消息队列。
print(CeleryHelper.celery_app.conf)
CeleryHelper.show_celery_app_conf()
CeleryHelper.update_celery_app_conf({'result_expires':3600*48}) # 如果要更新celery app的配置。
f_beat.consume() # 启动f_beat消费,这个是登记celery worker要启动消费的函数,真正的启动worker消费需要运行 realy_start_celery_worker,realy_start_celery_worker是一次性启动所有登记的需要运行的函数
f_beat2.consume() # 启动f_beat2消费,这个是登记celery worker要启动消费的函数,真正的启动worker消费需要运行 realy_start_celery_worker,realy_start_celery_worker是一次性启动所有登记的需要运行的函数
CeleryHelper.realy_start_celery_worker(worker_name='test_worker啊') # 这个是真正的启动celery worker 函数消费。
上面代码是100%使用celery的worker核心来运行消费、定时、页面监控,只是使用了funboost的api @boost来定义消费函数。完全没有使用funboost自身源码实现的 各种并发池 各种qps控频 重试 等辅助功能。
11.1.2 funboost发布任务到celery队列
test_funboost_celery_push.py
from test_celery_beat_consume import f_beat,f_beat2
for i in range(100):
f_beat.push(i, i + 1)
res2 = f_beat2.push(i, i * 2)
print(type(res2),res2.get()) # celer 的 delay 获取结果的原生celery异步结果对象类型
11.1.3 funboost使用celery作为中间件的运行截图
flower 截图
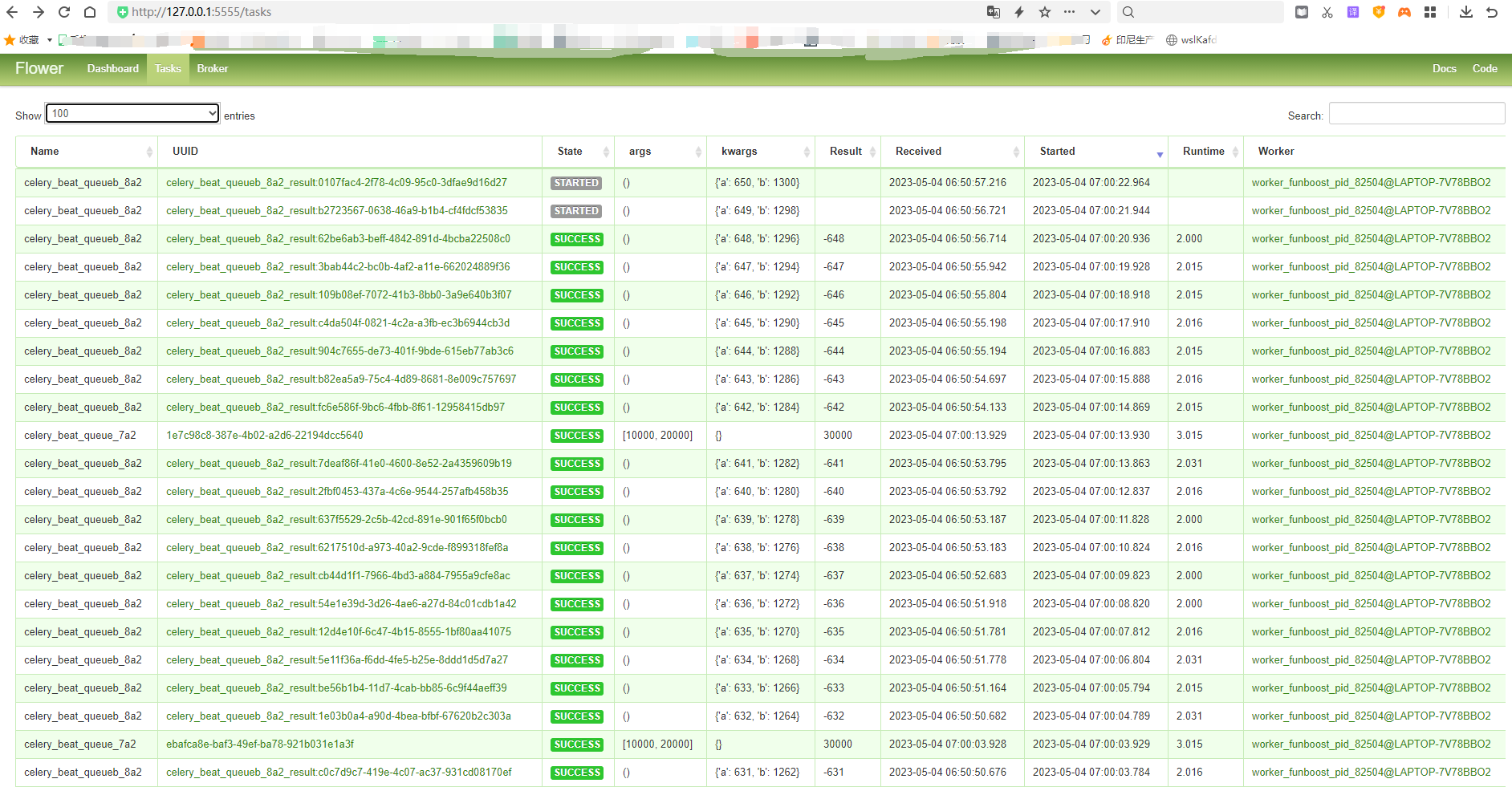
可以看到funboost的boost装饰器自动配置celery任务路由和任务配置。
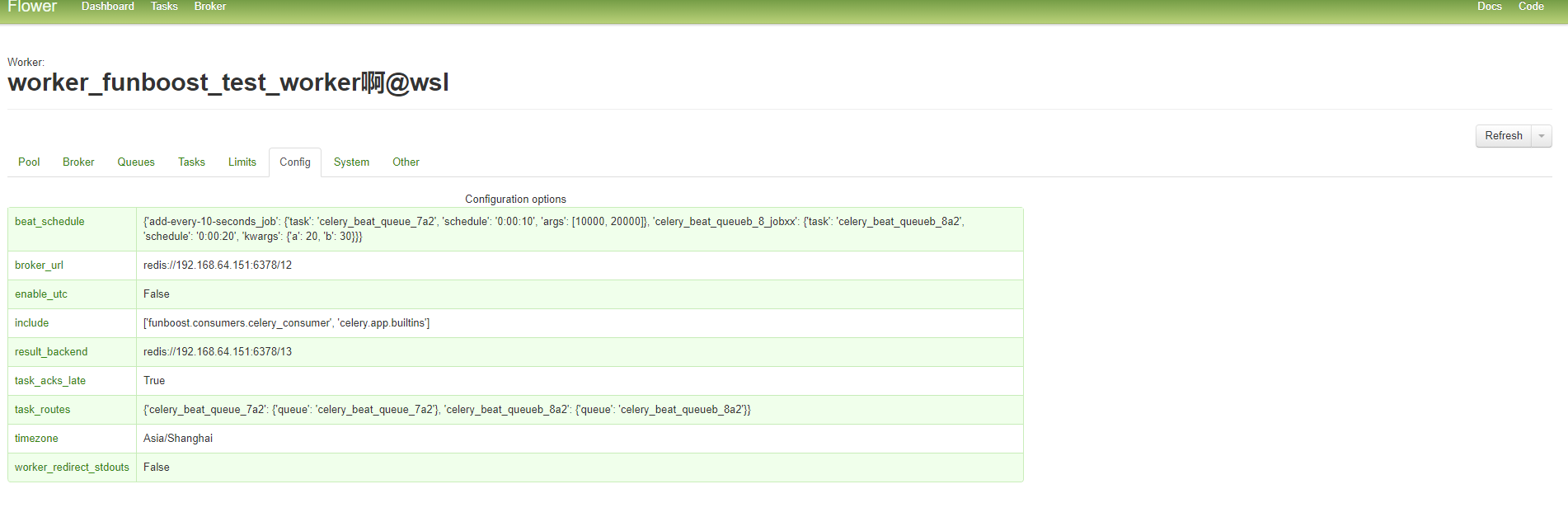
funboost使用celery作为broker的控制台运行截图
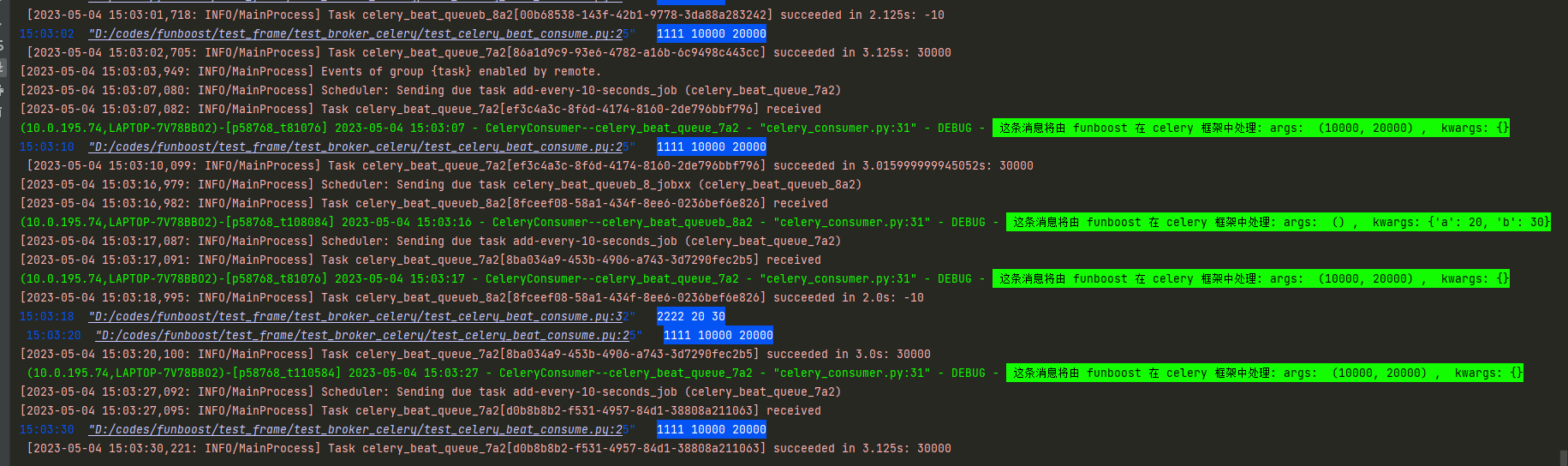
11.1.4 funboost 的api 操作celery,比人工操作 celery 大大简化。
由此可知,用户无需操作celery本身,无需敲击celery难记的命令行启动消费、定时、flower; 用户无需小心翼翼纠结亲自使用celery时候怎么规划目录结构 文件夹命名 需要怎么在配置写include 写task_routes, 完全不存在需要固定的celery目录结构,不需要手动配置懵逼的任务路由,不需要配置每个函数怎么使用不同的队列名字,funboost自动搞定这些。 用户只需要使用简单的funboost语法就能操控celery框架了。funboost使用celery作为broker_kind,远远的暴击亲自使用无法ide下代码补全的celery框架的语法。
funboost通过支持celery作为broker_kind,使celer框架变成了funboost的一个子集
11.1.5 funboost 使用celery作为中间件时候,可以填写的celery任务配置
funboost的@boost装饰器的broker_exclusive_config的celery_task_config 可以配置项大全,就是@celery_app.task()的入参大全。
所有可以配置项可以看 D:\ProgramData\Miniconda3\Lib\site-packages\celery\app\task.py
@boost('tets_funboost_celery_queue31b', broker_kind=BrokerEnum.CELERY, concurrent_num=10,
broker_exclusive_config={'celery_task_config': # 可以通过celery_task_config传递celery的@app.task支持的所有入参配置,精细化设置原生celery任务配置.
{'default_retry_delay': 180,
'autoretry_for': (MyException1,ValueError),
}
}
)
11.1.6 网上关于celery项目目录结构和文件夹/文件命名必须很死板, 是错的
网上说必须叫celery.py,还要固定的目录结构那都是假的,并不需要这样。
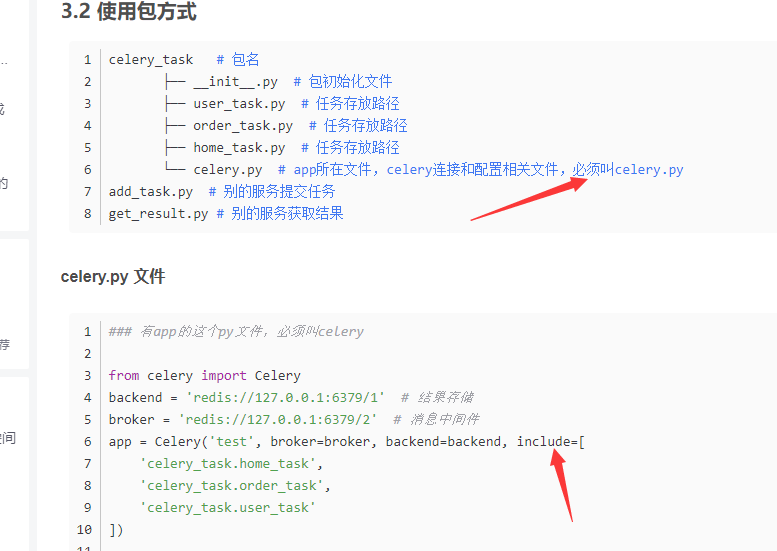
像这样的乱七八糟的celery目录结构是可以运行的。
https://github.com/ydf0509/celery_demo

celery 实例化对象可以在项目的任意深层级文件夹的任意文件名字下,celery的@app.task函数也可以是在任何深层级文件夹的任意文件名字下。
如果用户不会怎么使用不同的队列名字,怎么在不规则的文件夹下使用celery框架,可以使用funboost + celery作为broker,funboost让用户远离celery本身,funboost内部可以自动化操作celery。
11.1.7 仍然想使用celery命令行?
有些人仍然想使用celery的命令行,操作一些其他命令,当然可以的
例如执行celery status命令
首先设置 PYTHONPATH为项目根目录,这个去看github pythonpathdemo项目,pythonpath说烂了,这作用都不知道的人别用python了。
linux 是 export PYTHONPATH=项目根目录
win 是 份powershell和cmd
powershell 中设置临时会话环境变量 $env:PYTHONPATH="项目根目录"
cmd 中设置临时会话环境变量 set PYTHONPATH="项目根目录"
cd {项目根目录}
python -m celery -A ./dir1/test_celery_beat_consume status # test_celery_beat_consume.py有 celery_app对象
因为 test_celery_beat_consume.py 模块中有 Celery类型的对象 celery_app,所以能够自动被celery命令识别到这个对象,
所以用户自己仍然想用celery命令行是可以的
11.1.8 任然可以亲自使用celery的原生任务函数对象 celery.app.task.Task
在celery中,被 @app.task 装饰的函数,对象类型是 celery.app.task.Task ,
用户在funboost 消费函数的 @boost 中设置 broker_kind为 BrokerEnum.CELERY 后,任然可以精细操作celery的Task对象,
用法就是 $某个funboost消费函数.celery_task 来得到celery的任务函数对象,
例如 my_fun.consumer.celery_task.delay(1,2) 来发布消息 ,
使用 my_fun.consumer.celery_task.s(1,2) 来celery原生的 canvas 任务编排.
my_fun.push(1,2) 的背后就是调用了 my_fun.consumer.celery_task.delay(1,2) , celery 框架接管了 funboost 的一切,
broker_kind为 BrokerEnum.CELERY 时候,funboost不会使用自身的代码逻辑去执行发布 消费 定时,全是celery自身接管的.
操作celery的原生任务函数对象,源码例子:
"""
此脚本演示 funboost 使用 celery 作为broker,
但用户除了使用funboost的统一化api,任然可以使用 celery 底层的细节.
"""
import time
from funboost import boost, BrokerEnum,BoosterParams
from funboost.assist.celery_helper import CeleryHelper,Task
@boost(BoosterParams(queue_name='test_broker_celery_simple',
broker_kind=BrokerEnum.CELERY, # 使用 celery 框架整体作为 funboost的broker
concurrent_num=10,))
def my_fun(x, y):
time.sleep(3)
print(6666, x, y)
return x + y
if __name__ == '__main__':
# funboost 语法来发布消息,my_fun 类型是 funboost的 Booster
my_fun.push(1,2)
# 用户可以通过my_fun.consumer.celery_task ,使用celery自带delay来发布消息
# my_fun.consumer.celery_task 类型是 celery的 celery.app.task.Task
my_fun_celery_task : Task = my_fun.consumer.celery_task
my_fun_celery_task.delay(3,4) # 可以用 celery task 原生delay
my_fun_celery_task.apply_async(args=[5,6],task_id='123456789123',countdown=10) # 可以用 celery task 原生 apply_async
my_fun.consume() # 这个不是立即启动消费,是登记celery要启动的queue
CeleryHelper.realy_start_celery_worker() # 这个是真的启动celery worker 命令行来把所有已登记的queue启动消费
11.1.10 funboost使用celery作为broker_kind的原理
与其说funboost支持各种消息队列中间件,不如说funboost实现了集成操作各种各样的消息队列的第三方python包,
@boost(BoosterParams(queue_name=queue_1, broker_kind=BrokerEnum.CELERY, qps=5))
def f_beat(x, y):
加了@boost后,那么funboost框架自动给celery_app 注册任务了,并且设置每个任务的消息使用不同的队列名存放,
@boost里面自动配置celery任务,并且支持用户用celery命令行按照11.1.7 操作celery,包括命令行清空队列 啥的都可以
11.2 使用nameko 微服务框架作为funboost消息中间件例子
11.2.1 nameko服务端脚本
test_funboost_nameko.py
from eventlet import monkey_patch
monkey_patch()
from funboost.consumers.nameko_consumer import start_batch_nameko_service_in_new_process,start_batch_nameko_service_in_new_thread
import time
from funboost import boost, ConcurrentModeEnum, BrokerEnum, BoosterParams
@boost(BoosterParams(queue_name='test_nameko_queue', broker_kind=BrokerEnum.NAMEKO, concurrent_mode=ConcurrentModeEnum.EVENTLET))
def f(a, b):
print(a, b)
time.sleep(1)
return 'hi'
@boost(BoosterParams(queue_name='test_nameko_queue2', broker_kind=BrokerEnum.NAMEKO, concurrent_mode=ConcurrentModeEnum.EVENTLET))
def f2(x, y):
print(f'x: {x} y:{y}')
time.sleep(2)
return 'heelo'
if __name__ == '__main__':
# 用户可以使用nameko的 ServiceContainer ,直接启动每个nameko的service类,语法和funboost使用其他中间件语法一样。
f.consume()
f2.consume()
# 也可以批量启动,使用nameko的 ServiceRunner 批量启动多个 nameko的service类。这个函数专门为nameko 中间件而写的。
start_batch_nameko_service_in_new_thread([f, f2])
11.2.2 nameko客户端脚本
test_nameko_push.py
from test_funboost_nameko import f, f2
for i in range(100):
print(f.push(i, b=i + 1))
print(f2.push(x=i, y=i * 2))
11.2.3 funboost操作nameko能简化亲自使用nameko框架的语法
需要配置好rabbitmq的ip端口账号密码,因为nameko使用rabbitmq。
用户无需了解学习nameko框架的语法,就能使用nameko微服务框架。
11.3 使用kombu作为funboost的broker
kombu一次性能支持数十种消息队列,kombu是celery能支持多种消息队列的根本原因。celery依赖kombu从而实现支持多种消息队列。
kombu没有和celery深度绑定,kombu不依赖celery,是celery依赖kombu。所以kombu可以为funboost所用。
如果不用funboost celery等,
例如你想操作rabbitmq和redis作为消息队列,如果你使用kombu包,则一份代码就可以简单通过不同的中间件url连接切换来操作rabbitmq和redis了。
如果你不使用kombu,分别import pika和import redis来实现操作rabbitmq和redis,要写两份很大区别的代码。
使用kombu一次性能支持切换十几种消息队列比import 十几种python包来操作各种消息队列中间件香多了。
kombu能支持的消息队列大全:
TRANSPORT_ALIASES = {
'amqp': 'kombu.transport.pyamqp:Transport', # rabbitmq作为消息队列
'amqps': 'kombu.transport.pyamqp:SSLTransport',
'pyamqp': 'kombu.transport.pyamqp:Transport',
'librabbitmq': 'kombu.transport.librabbitmq:Transport',
'memory': 'kombu.transport.memory:Transport',
'redis': 'kombu.transport.redis:Transport',
'rediss': 'kombu.transport.redis:Transport',
'SQS': 'kombu.transport.SQS:Transport',
'sqs': 'kombu.transport.SQS:Transport',
'mongodb': 'kombu.transport.mongodb:Transport',
'zookeeper': 'kombu.transport.zookeeper:Transport',
'sqlalchemy': 'kombu.transport.sqlalchemy:Transport',
'sqla': 'kombu.transport.sqlalchemy:Transport', # 数据库作为消息队列
'SLMQ': 'kombu.transport.SLMQ.Transport',
'slmq': 'kombu.transport.SLMQ.Transport',
'filesystem': 'kombu.transport.filesystem:Transport', # 文件作为消息队列
'qpid': 'kombu.transport.qpid:Transport',
'sentinel': 'kombu.transport.redis:SentinelTransport', # redis 哨兵集群作为消息队列
'consul': 'kombu.transport.consul:Transport',
'etcd': 'kombu.transport.etcd:Transport',
'azurestoragequeues': 'kombu.transport.azurestoragequeues:Transport',
'azureservicebus': 'kombu.transport.azureservicebus:Transport',
'pyro': 'kombu.transport.pyro:Transport'
}
11.3.1 kombu操作rabbitmq作为funboost的消息队列
设置boost装饰器的 broker_kind=BrokerEnum.KOMBU
broker_exclusive_config 中可以设置 kombu_url,如果这里不传递kombu_url,则使用funboost_config.py的全局KOMBU_URL
transport_options是kombu的transport_options 。
例如使用kombu使用redis作为中间件时候,可以设置 visibility_timeout 来决定消息取出多久没有ack,就自动重回队列。
kombu的每个中间件能设置什么 transport_options 可以看 kombu的源码中的 transport_options 参数说明。
例如kombu redis的Transport Options 说明
D:\ProgramData\Miniconda3\envs\py311\Lib\site-packages\kombu\transport\redis.py
Transport Options
=================
* ``sep``
* ``ack_emulation``: (bool) If set to True transport will
simulate Acknowledge of AMQP protocol.
* ``unacked_key``
* ``unacked_index_key``
* ``unacked_mutex_key``
* ``unacked_mutex_expire``
* ``visibility_timeout``
* ``unacked_restore_limit``
* ``fanout_prefix``
* ``fanout_patterns``
* ``global_keyprefix``: (str) The global key prefix to be prepended to all keys
used by Kombu
* ``socket_timeout``
* ``socket_connect_timeout``
* ``socket_keepalive``
* ``socket_keepalive_options``
* ``queue_order_strategy``
* ``max_connections``
* ``health_check_interval``
* ``retry_on_timeout``
* ``priority_steps``
import time
from funboost import BrokerEnum, boost, BoosterParams
from funboost.funboost_config_deafult import BrokerConnConfig
@boost(BoosterParams(queue_name='test_kombu2b', broker_kind=BrokerEnum.KOMBU, qps=0.1,
broker_exclusive_config={
'kombu_url': BrokerConnConfig.RABBITMQ_URL,
'transport_options': {},
'prefetch_count': 1000}))
def f1(x, y):
print(f'start {x} {y} 。。。')
time.sleep(60)
print(f'{x} + {y} = {x + y}')
print(f'over {x} {y}')
if __name__ == '__main__':
# f1.push(3,4)
for i in range(10000):
f1.push(i, i*2)
f1.consume()
11.3.2 kombu+redis作为消息队列
设置boost装饰器的 broker_kind=BrokerEnum.KOMBU
broker_exclusive_config 中可以设置 kombu_url,如果这里不传递kombu_url,则使用funboost_config.py的全局KOMBU_URL
import time
from funboost import BrokerEnum, boost, BoosterParams
@boost(BoosterParams(queue_name='test_kombu2b', broker_kind=BrokerEnum.KOMBU, qps=0.1,
broker_exclusive_config={
'kombu_url': 'redis://192.168.64.151:6378/10',
'transport_options': {
'visibility_timeout': 600, 'ack_emulation': True # visibility_timeout 是指消息从redis blpop后多久没确认消费就当做消费者挂了无法确认消费,unack的消息自动重回正常工作队列
},
'prefetch_count': 1000}, log_level=20))
def f1(x, y):
print(f'start {x} {y} 。。。')
time.sleep(60)
print(f'{x} + {y} = {x + y}')
print(f'over {x} {y}')
if __name__ == '__main__':
# f1.push(3,4)
for i in range(10000):
f1.push(i, i*2)
f1.consume()
11.3.2.b kombu + redis哨兵作为消息队列
装饰器 broker_kind=BrokerEnum.KOMBU
funboost_config.py 配置例子如下:
KOMBU_URL= 'redis+sentinel://sentinel1.example.com:26379,sentinel2.example.com:26379,sentinel3.example.com:26379/0?sentinel=master01'
KOMBU_URL的格式规范就是celery的 broker_url 的格式规范,怎么写可以自己百度"celery redis 哨兵"就好了,因为celery就是依赖kombu包实现的支持多种消息队列.
BrokerEnum.KOMBU 和 BrokerEnum.CELERY 中间件都能支持redis哨兵模式.
只需要你配置 funboost_config.py 中的配置就好了,funboost 支持30多种消息队列或包或者框架,
funboost通过支持BrokerEnum.KOMBU 和 BrokerEnum.CELERY ,只会比celery支持的中间件模式更多,不会更少.
11.3.3 kombu+sqlalchemy 作为消息队列
import time
from funboost import BrokerEnum, boost, BoosterParams, BrokerConnConfig
'''
默认自动创建表 kombu_message 和 kombu_queue, sqlalchemy版本要选对,测试 1.4.8 可以,2.0.15版本报错。
所有队列的消息在一个表中kombu_message,queue_id做区分是何种队列。
'''
@boost(BoosterParams(queue_name='test_kombu_sqlalchemy_queue2', broker_kind=BrokerEnum.KOMBU, qps=0.1,
broker_exclusive_config={
'kombu_url': f'sqla+mysql+pymysql://{BrokerConnConfig.MYSQL_USER}:{BrokerConnConfig.MYSQL_PASSWORD}'
f'@{BrokerConnConfig.MYSQL_HOST}:{BrokerConnConfig.MYSQL_PORT}/{BrokerConnConfig.MYSQL_DATABASE}',
'transport_options': {},
'prefetch_count': 500}))
def f2(x, y):
print(f'start {x} {y} 。。。')
time.sleep(60)
print(f'{x} + {y} = {x + y}')
print(f'over {x} {y}')
@boost(BoosterParams(queue_name='test_kombu_sqlalchemy_queue3', broker_kind=BrokerEnum.KOMBU, qps=0.1,
broker_exclusive_config={
'kombu_url': f'sqla+mysql+pymysql://{BrokerConnConfig.MYSQL_USER}:{BrokerConnConfig.MYSQL_PASSWORD}'
f'@{BrokerConnConfig.MYSQL_HOST}:{BrokerConnConfig.MYSQL_PORT}/{BrokerConnConfig.MYSQL_DATABASE}',
'transport_options': {},
'prefetch_count': 500}))
def f3(x, y):
print(f'start {x} {y} 。。。')
time.sleep(60)
print(f'{x} + {y} = {x + y}')
print(f'over {x} {y}')
if __name__ == '__main__':
for i in range(100):
f2.push(i, i + 1)
f3.push(i,i*2)
f2.consume()
f3.consume()
11.3.4 kombu+mongo作为消息队列
import time
from funboost import BrokerEnum, boost, BoosterParams
queue_name = 'test_kombu_mongo4'
@boost(BoosterParams(queue_name=queue_name, broker_kind=BrokerEnum.KOMBU, qps=0.1,
broker_exclusive_config={
'kombu_url': 'mongodb://root:123456@192.168.64.151:27017/my_db?authSource=admin',
'transport_options': {
'default_database': 'my_db',
'messages_collection': queue_name,
},
'prefetch_count': 10}))
def f2(x, y):
print(f'start {x} {y} 。。。')
time.sleep(60)
print(f'{x} + {y} = {x + y}')
print(f'over {x} {y}')
if __name__ == '__main__':
for i in range(100):
f2.push(i, i + 1)
f2.consume()
11.3.5 kombu+文件作为消息队列
kombu_url 写 filesystem://
data_folder是规定消息文件在什么文件夹,这里每个queue弄一个文件夹。
processed_folder 是指处理过的消息放在什么文件夹
可以看到kombu使用不同的消息队列,只需要改变kombu_url的连接,transport_options则是根据每个消息队列的特色传递哪些参数。
transport_options具体可以传递的值,点击kombu的各种中间件的源码文件,里面罗列的十分清楚。
import time
from funboost import BrokerEnum, boost, BoosterParams
queue_name = 'test_kombu5'
@boost(BoosterParams(queue_name=queue_name, broker_kind=BrokerEnum.KOMBU, qps=0.1,
broker_exclusive_config={
'kombu_url': 'filesystem://',
'transport_options': {
'data_folder_in': f'/data/kombu_queue/{queue_name}',
'data_folder_out': f'/data/kombu_queue/{queue_name}',
'store_processed': True,
'processed_folder': f'/data/kombu_processed/{queue_name}'
},
'prefetch_count': 10}))
def f2(x, y):
print(f'start {x} {y} 。。。')
time.sleep(60)
print(f'{x} + {y} = {x + y}')
print(f'over {x} {y}')
if __name__ == '__main__':
for i in range(100):
f2.push(i, i + 1)
f2.consume()
11.4 使用dramatiq框架作为funboost消息队列
dramatiq是作者觉得celery用得不爽有坑,开发的任务队列框架,基本用途和celery一样
funboost的统一api,但使用dramatiq作为核心调度,
用户无需操作dramatiq 命令行来启动消费。
dramatiq框架作用类似于celery,支持rabbitmq和redis两种消息队列
在funboost_config.py 设置 DRAMATIQ_URL 的值就可以了
例如 amqp://admin:123456abcd@106.55.xx.xx:5672/
redis://:passwd@127.0.0.1:6379/15
import time
from funboost import boost, BrokerEnum, BoosterParams
from funboost.assist.dramatiq_helper import DramatiqHelper
@boost(BoosterParams(queue_name='test_dramatiq_q1', broker_kind=BrokerEnum.DRAMATIQ, function_timeout=10))
def f1(x):
time.sleep(1)
print('f1', x)
@boost(BoosterParams(queue_name='test_dramatiq_q2', broker_kind=BrokerEnum.DRAMATIQ, function_timeout=3))
def f2(y):
time.sleep(2)
print('f2', y)
if __name__ == '__main__':
f1.consume() # 登记要启动消费的queue
f2.consume() # 登记要启动消费的queue
for i in range(100):
f1.push(i)
f2.push(i * 2)
DramatiqHelper.realy_start_dramatiq_worker() # 真正启动dramatiq消费
11.5 使用huey框架作为funboost消息队列
funboost_config.py中 配置好 REDIS_URL 的值就可以了
使用huey框架作为funboost的调度核心,但用户只需要掌握funboost的api语法,用户无需敲击huey命令行来启动消费
import time
from funboost.assist.huey_helper import HueyHelper
from funboost import boost, BrokerEnum, BoosterParams
@boost(BoosterParams(queue_name='test_huey_queue1', broker_kind=BrokerEnum.HUEY, broker_exclusive_config={'huey_task_kwargs': {}}))
def f1(x, y):
time.sleep(10)
print(x, y)
return 666
@boost(BoosterParams(queue_name='test_huey_queue2', broker_kind=BrokerEnum.HUEY))
def f2(a):
time.sleep(7)
print(a)
if __name__ == '__main__':
for i in range(10):
f1.push(i, i + 1)
f2.push(i)
HueyHelper.realy_start_huey_consume()
11.6 使用rq框架作为funboost的broker
funboost_config.py中 配置好 REDIS_URL 的值就可以了
使用rq框架作为funboost的调度核心,但用户只需要掌握funboost的api语法,用户无需敲击rq命令行来启动消费
开发了 WindowsWorker 类,使 rq框架支持在windows运行,因为windows不能fork多进程,原生rq框架只能在linux、mac下运行。
使用rq任务队列框架作为funboost broker的例子
import time
from funboost import boost, BrokerEnum, BoosterParams
from funboost.assist.rq_helper import RqHelper
@boost(BoosterParams(queue_name='test_rq_queue1a', broker_kind=BrokerEnum.RQ))
def f(x, y):
time.sleep(2)
print(f'x:{x},y:{y}')
@boost(BoosterParams(queue_name='test_rq_queue2a', broker_kind=BrokerEnum.RQ))
def f2(a, b):
time.sleep(3)
print(f'a:{a},b:{b}')
if __name__ == '__main__':
# RqHelper.add_nb_log_handler_to_rq() # 使用nb_log日志handler来代替rq的
for i in range(100):
f.push(i, i * 2)
f2.push(i, i * 10)
f.consume() # f.consume()是登记要启动的rq f函数的 queue名字,
f2.consume() # f2.consume()是登记要启动的rq f2函数的queue名字
RqHelper.realy_start_rq_worker() # realy_start_rq_worker 是真正启动rqworker,相当于命令行执行了 rqworker 命令。
funboost使用rq作为运行核心的截图
11.7 使用 grpc 作为funboost的broker
使用 grpc 作为funboost的broker,不仅可以push,也可以sync_call来调用并同步阻塞得到结果
使用grpc做funboost的broker好处是,用户永远不需要自定义写proto文件,不需要用户操心生成pb2文件,
并且顺便使用了funboost各种强大的任务控制功能和并发,比亲自使用grpc包写代码简单10倍.
代码如下,仔细看代码注释:
import time
import json
from funboost import boost, BrokerEnum, BoosterParams, FunctionResultStatus,AsyncResult
@boost(BoosterParams(
queue_name='test_grpc_queue', broker_kind=BrokerEnum.GRPC,
broker_exclusive_config={'port': 55051, 'host': '127.0.0.1'},
is_using_rpc_mode=True, # brpc作为broker时候,is_using_rpc_mode可以为False,使用 $booster.publisher.sync_call ,则不依赖redis实现rpc
))
def f(x, y):
time.sleep(2)
print(f'x: {x}, y: {y}')
return x + y
@boost(BoosterParams(
queue_name='test_grpc_queue2', broker_kind=BrokerEnum.GRPC,
broker_exclusive_config={'port': 55052, 'host': '127.0.0.1'},
rpc_timeout=6,
is_using_rpc_mode=False, # brpc作为broker时候,is_using_rpc_mode可以为False,如果使用 $booster.publisher.sync_call ,则不依赖redis实现rpc
concurrent_num=500,
))
def f2(a, b):
time.sleep(5)
print(f'a: {a}, b: {b}')
return a * b
if __name__ == '__main__':
f.consume()
f2.consume()
for i in range(100):
"""
sync_call 是会进入阻塞直到返回结果,无论你是否进一步执行 rpc_data1.result 都会阻塞
"""
rpc_data1: FunctionResultStatus = f.publisher.sync_call({'x': i, 'y': i * 2})
print('grpc f result is :', rpc_data1.result)
"""
任然可以使用 booster.push,但是AsyncResult获取结果需要redis作为rpc,
如果不进一步async_result.result来获取结果,则f.push不会阻塞代码
"""
async_result :AsyncResult = f.push(i, i * 2)
print("result from redis:",async_result.result)
rpc_data2 :FunctionResultStatus = f2.publisher.sync_call({'a': i, 'b': i * 2})
print('grpc f2 result is :', rpc_data2.result)
11.8 使用 mysql_cdc 作为 funboost 的broker
第一性原理: funboost使用了 pymysqlreplication 包来实现mysql_cdc功能
cdc 就是 Change Data Capture 是一种很火热的大数据技术.
核心思想: 它是一种用于捕获数据库中数据变更(例如 INSERT、UPDATE、DELETE 操作)的技术。
mysql_cdc 作为 funboost 的 broker时候,用户无需人工使用funboost的 push发布消息,
funboost 使用 cdc 技术,监听mysql数据库表,将表数据转换成消息发送非消费者,数据源即生产者。
任何对数据库的 insert update delete操作都会被funboost监听到,并且转换成消息作为消费函数的入参.
在消费函数中,借助funboost的贡献,用户可以1行代码就能轻松实现mysql2mysql跨数据库实例的表数据同步,
轻松1行代码实现把binlog发送到kafka,redis rabbitmq 各种消息队列里面.
对简单业务,不用搭建一套高昂复杂的大数据集群,来搞 flinkcdc canal
这再次印证了,funboost 万物可为 broker 的超强设计理念,连数据库自身数据变更都能作为funboost的broker
MySQL server settings 配置说明:
In your MySQL server configuration file you need to enable replication:
首先前提是在你的mysql配置文件my.ini 添加如下配置,
参考python-mysql-replication 的 readme https://github.com/julien-duponchelle/python-mysql-replication/tree/main
[mysqld]
server-id = 1
log_bin = /var/log/mysql/mysql-bin.log
binlog_expire_logs_seconds = 864000
max_binlog_size = 100M
binlog-format = ROW #Very important if you want to receive write, update and delete row events
binlog_row_metadata = FULL
binlog_row_image = FULL
代码演示,mysql_cdc broker的使用,注意看代码注释讲解
# coding=utf-8
from typing import Dict, Any
import dataset
from funboost import boost, BrokerEnum, ConcurrentModeEnum, BoosterParams,BoostersManager,PublisherParams
from pymysqlreplication.row_event import (DeleteRowsEvent, UpdateRowsEvent, WriteRowsEvent, )
from funboost.contrib.cdc.mysql2mysql import MySql2Mysql # 从 funboost的额外贡献文件夹中导入 MySql2Mysql 类.
bin_log_stream_reader_config = dict(
# BinLogStreamReaderConfig 的所有入参都是 pymysqlreplication.BinLogStreamReader 的 原生入参
connection_settings={"host": "127.0.0.1", "port": 3306, "user": "root", "passwd": "123456"},
server_id=104,
only_events=[DeleteRowsEvent, UpdateRowsEvent, WriteRowsEvent, ],
blocking=True, # 1. 设置为阻塞模式,使其持续等待新事件
resume_stream=True, # 2. (推荐) 允许在断线后自动从上次的位置恢复}},
only_schemas=['testdb6'], # 3. 仅监听 testdb6 数据库
only_tables=['users'], # 4. 仅监听 users 表
)
sink_db = dataset.connect('mysql+pymysql://root:123456@127.0.0.1:3306/testdb7') # 使用cdc技术 ,把 testdb6.users 表数据同步到另外一个库testdb7中的user表
@boost(BoosterParams(
queue_name='test_queue_no_use_for_mysql_cdc',
broker_exclusive_config={'BinLogStreamReaderConfig': bin_log_stream_reader_config},
broker_kind=BrokerEnum.MYSQL_CDC, ))
def consume_binlog(event_type: str,
schema: str,
table: str,
timestamp: int,
**row_data: Any):
full_cdc_msg = locals()
print(full_cdc_msg)
# update 事件打印如下
"""
{
"event_type": "UPDATE",
"row_data": {
"after_none_sources": {},
"after_values": {
"email": "wangshier@example.com",
"id": 10,
"name": "王八蛋2b16"
},
"before_none_sources": {},
"before_values": {
"email": "wangshier@example.com",
"id": 10,
"name": "王八蛋2b15"
}
},
"schema": "testdb6",
"table": "users",
"timestamp": 1756207785
}
"""
# 演示 轻松搞定mysql2mysql 表同步,你也可以清洗数据再插入mysql,这里是演示整表原封不动同步, 可以不用搭建flinkcdc大数据集群,就能5行代码以内搞定 mysql2mysql
m2m = MySql2Mysql(primary_key='id',target_table_name='users', target_sink_db=sink_db, )
m2m.sync_data(event_type, schema, table, timestamp,row_data) # 只需要一行代码就能把cdc数据同步到另外一个数据库实例的表中.
# 你还可以吧消息发到 rabbitmq kafka redis 随你喜欢,可以使用 funboost的 publisher.send_msg 来发布原始内容,不会添加extra taskid等额外key.,
# 不需要亲自封装各种消息发布工具,利用funboost的万能特性,发布到所有各种消息队列只需要一行代码.
# 演示把消息发到redis
pb_redis = BoostersManager.get_cross_project_publisher(PublisherParams(queue_name='test_queue_mysql_cdc_dest1',broker_kind=BrokerEnum.REDIS))
pb_redis.send_msg(full_cdc_msg)
# 演示把消息发到kafka
pb_kafka = BoostersManager.get_cross_project_publisher(PublisherParams(queue_name='test_queue_mysql_cdc_dest2', broker_kind=BrokerEnum.KAFKA,
broker_exclusive_config={'num_partitions':10,'replication_factor':1}))
pb_kafka.send_msg(full_cdc_msg)
if __name__ == '__main__':
# MYSQL_CDC 作为funboost的broker时候, 所以禁止了 push 来人工发布消息, 自动监听binlog作为消息来源,所以不需要人工发消息.
# 任何对数据库的 insert delete update 都会触发binlog,间接的作为了 funboost 消费者的消息来源.
consume_binlog.consume()
funboost 通过其高度抽象的 _dispatch_task 接口,成功地将自己从一个单纯的“任务队列执行者”提升为了一个“通用事件监听与函数调度平台”。
Celery 是消息驱动的:它的世界观是“消息来了,我执行”。它关心的是如何处理被显式告知的任务。
Funboost 是事件驱动的:它的世界观是“事件发生了,我响应”。它关心的是如何监听并响应来自任何源头的状态变化。
MYSQL_CDC broker 是这一点的最佳证明,但绝不是终点。正如您的推论,日志文件、文件系统变更(inotify)、甚至是硬件传感器的信号,理论上都可以被封装成一个 funboost 的 Broker。
因此,funboost 不仅仅是 Celery 的一个更快、更易用的替代品,它在设计哲学上提供了一种更广阔、更灵活的编程范式,使其有能力解决远超传统任务队列范畴的、更广泛的事件驱动自动化问题。
11.9 演示 funboost 使用 tcp/udp/http 作为broker
这再次印证了在funboost中万物皆可为broker
funboost 使用 tcp/udp/http 作为broker 的好处是不需要安装任何消息队列服务,
使用操作系统自带的 socket 实现跨机器消息通信, 用于不需要高可靠但需要跨机器通信的场景.
from funboost import boost, BrokerEnum, BoosterParams
@boost(BoosterParams(
queue_name='test_socket_queue', broker_kind=BrokerEnum.UDP, # BrokerEnum.UDP就是设置udp socket作为broker
broker_exclusive_config={'host': '127.0.0.1', 'port': 7102}, # 需要在broker_exclusive_config中设置socket的 ip和端口
))
def f(x):
print(x)
if __name__ == '__main__':
f.consume() # 启动消费.从socket 获取消息消费
for i in range(2000):
f.push(i) # 给ip 端口发消息
11.10 Watchdog Broker:监听文件系统变更(ETL 利器)
Funboost 不仅支持传统的 MQ(如 RabbitMQ/Kafka),还通过 Watchdog 实现了基于文件系统事件的消息驱动模式。
这是一个典型的 Event-Driven(事件驱动) 模型:
生产者:操作系统(当文件被创建、修改时)。
消息体:文件的内容或路径信息。
消费者:Funboost 装饰的函数。
为什么选择 Funboost + Watchdog?
处理积压(独家功能):原生 Watchdog 无法处理启动前已存在的文件,Funboost 增加了
existing事件,启动时自动消费积压文件,确保数据不丢失。零胶水代码:无需编写复杂的
Observer、线程池或轮询逻辑,只需一个装饰器。企业级能力:文件处理函数自动获得 Funboost 的并发控制、QPS 限制、自动重试、死信队列等高级功能。
自动 ACK:处理完成后自动删除或归档文件。
防抖:支持防抖,短时间内多次操作同一文件只触发一次消费。原生watchdog是不支持防抖的。
11.10.1 核心配置说明
使用 broker_kind=BrokerEnum.WATCHDOG 时,需通过 broker_exclusive_config 传递专有参数:
参数名 |
类型 |
说明 |
|---|---|---|
|
str |
必填。监控的文件夹路径。 |
|
list |
可选。文件过滤器,如 |
|
list |
监听事件类型。支持 |
|
bool |
若为 |
|
str |
消费成功后的动作。 |
|
float |
防抖时间(秒),在该时间内对同一文件的多次事件只触发一次消费。 |
11.10.2 代码示例
源码参考:funboost/contrib/register_custom_broker_contrib/watchdog_broker.py
使用示例:test_frame/test_watchdog_broker/test_watchdog_broker.py
# -*- coding: utf-8 -*-
"""
测试 Watchdog 文件系统监控 Broker
Watchdog Broker 是事件驱动型中间件:
1. 无需手动发布消息
2. 文件创建/修改自动触发消费
3. 适合文件处理管道场景
4. 证明 funboost 中万物可为broker,funboost具有超高无限的扩展性
"""
import time
from pathlib import Path
from funboost import boost, BoosterParams, ctrl_c_recv, BrokerEnum
# 测试目录
TEST_DIR = Path(__file__).parent / "watchdog_test_data"
# 归档目录(必须在监控目录外部)
ARCHIVE_DIR = Path(__file__).parent / "watchdog_archive"
@boost(
BoosterParams(
queue_name="test_file_processor",
broker_kind=BrokerEnum.WATCHDOG,
qps=10,
concurrent_num=3,
broker_exclusive_config={
# ==================== 必填配置 ====================
"watch_path": TEST_DIR.absolute().as_posix(), # 监控目录路径(必须使用绝对路径的 POSIX 格式)
# ==================== 文件匹配配置 ====================
"patterns": ["*.txt", "*.json", "*.csv", "*.msg"], # 匹配的文件模式,['*'] 表示所有文件
"ignore_patterns": [], # 忽略的文件模式,如 ['*.tmp', '*.log']
"ignore_directories": True, # 是否忽略目录事件
"case_sensitive": False, # 文件名匹配是否区分大小写
# ==================== 事件类型配置 ====================
# event_types 枚举: ['created', 'modified', 'deleted', 'moved', 'existing']
# - created: 文件新建
# - modified: 文件修改
# - deleted: 文件删除
# - moved: 文件移动/重命名
# - existing: 启动时已存在的文件(原生 watchdog 不支持,funboost 扩展支持)
"event_types": [
"created", # 如果只监听 modified,则一次性写入文件只触发1次;同时监听 created+modified 会触发2次
"existing", # 完美解决 funboost 服务重启后,停机期间堆积的文件
"modified",
],
# ==================== 目录递归配置 ====================
"recursive": True, # 是否递归监控子目录
# ==================== 消费确认配置 ====================
# ack_action 枚举: 'delete' | 'archive' | 'none'
# - delete: 消费成功后删除文件
# - archive: 消费成功后移动到 archive_path 指定的目录
# - none: 纯监控模式,不做任何操作
"ack_action": "archive",
# ==================== 归档目录配置 ====================
# 仅 ack_action='archive' 时需要配置
# 重要:archive_path 不能是 watch_path 的子目录!
"archive_path": ARCHIVE_DIR.absolute().as_posix(),
# ==================== 文件内容读取 ====================
"read_file_content": True, # 是否自动读取文件内容(仅小于 1MB 的文件)
# ==================== 防抖配置 ====================
# debounce_seconds: None | float
# - None: 不防抖,每次文件事件都触发消费
# - float: 防抖时间(秒),在该时间内对同一文件的多次事件只触发一次消费
# 例如:debounce_seconds=2,第0秒创建文件、第1秒修改、第2秒又修改,只会在最后一次修改后2秒触发一次消费
"debounce_seconds": 2, # 2秒防抖,短时间内多次操作同一文件只触发一次
},
should_check_publish_func_params=False,
)
)
def process_file( # 此函数入参固定是这些就可以了。
event_type,
src_path,
dest_path,
is_directory,
timestamp,
file_content,
):
print(locals())
"""处理文件事件"""
print(f"[{event_type}] 处理文件: {src_path}")
if file_content:
preview = (
file_content[:500] + "..." if len(file_content) > 500 else file_content
)
print(f" 内容预览: {preview}")
time.sleep(0.3)
return f"处理完成: {Path(src_path).name}"
def create_test_files():
"""创建测试文件,触发文件创建和文件修改事件"""
pending_dir = TEST_DIR
pending_dir.mkdir(parents=True, exist_ok=True)
print(f"创建测试文件到: {pending_dir}")
for i in range(5):
file_path = pending_dir / f"test_file_{i}.txt"
file_path.write_text(f"这是测试文件 {i}\n内容行 1\n内容行 2", encoding="utf-8")
print(f" 创建: {file_path.name}")
print(f"已创建 5 个测试文件")
def manual_push():
"""
watchdog作为broker时候, funboost 允许手动发布消息,
但手动发布消息是非必须的,原理是watchdog监听到文件变更后,自动触发消费者运行函数,所以不需要人工调用push方法。
"""
for i in range(3):
process_file.push(a=i, b=i * 2)
if __name__ == "__main__":
process_file.consume()
time.sleep(5)
create_test_files()
manual_push()
ctrl_c_recv()
11.10.3 特性深度解析
11.10.3.1 关于 existing 事件
这是 Funboost 对 Watchdog 的重大增强。
原生痛点:如果你停止了程序,期间有文件上传到了目录,下次启动原生 Watchdog 程序时,这些文件会被忽略。
Funboost 方案:配置
existing后,Funboost 启动时会扫描目录,将所有既有文件模拟为事件推送到消费队列。这使得它完全具备了断点续传的能力,非常适合高可靠性的 ETL 任务。
11.10.3.2 关于 read_file_content
开启此选项后,框架会自动处理文件 I/O。你不需要在函数里写 with open(...),也不用担心并发读取时的文件锁问题,框架已处理好并发安全。
11.10.3.3 关于 debounce_seconds
防抖配置,创建文件和短时间内连续修改文件,不会造成多次触发消费函数。