4b.使用框架的各种代码示例(高级进阶)
4b.1 日志模板中自动显示task_id
4b.1.1 日志模板中显示task_id
在 funboost_config.py 中设置如下 (43.0版本以后的配置默认就是待task_id的模板了)
如果用户的 funboost_config.py 是旧的日志模板,升级到43.0以后版本,需要修改 NB_LOG_FORMATER_INDEX_FOR_CONSUMER_AND_PUBLISHER 为新的带task_id的日志模板,日志中才能自动显示task_id
import logging
from nb_log import nb_log_config_default
class FunboostCommonConfig(DataClassBase):
# nb_log包的第几个日志模板,内置了7个模板,可以在你当前项目根目录下的nb_log_config.py文件扩展模板。
# NB_LOG_FORMATER_INDEX_FOR_CONSUMER_AND_PUBLISHER = 11 # 7是简短的不可跳转,5是可点击跳转的,11是可显示ip 进程 线程的模板,也可以亲自设置日志模板不传递数字。
NB_LOG_FORMATER_INDEX_FOR_CONSUMER_AND_PUBLISHER = logging.Formatter(
f'%(asctime)s-({nb_log_config_default.computer_ip},{nb_log_config_default.computer_name})-[p%(process)d_t%(thread)d] - %(name)s - "%(filename)s:%(lineno)d" - %(funcName)s - %(levelname)s - %(task_id)s - %(message)s',
"%Y-%m-%d %H:%M:%S",) # 这个是带task_id的日志模板,日志可以显示task_id,方便用户串联起来排查某一个人物消息的所有日志.
待task_id的日志模板如下图

4b.1.2 用户在消费函数中想自动显示task_id,方便搜索task_id的关键字来排查某条消息的所有日志.
用户使用 logger = LogManager('namexx',logger_cls=TaskIdLogger).get_logger_and_add_handlers(......) 的方式来创建logger,
关键是用户需要设置 logger_cls=TaskIdLogger
代码如下:
import random
import time
from funboost import boost, FunctionResultStatusPersistanceConfig, BoosterParams,fct
from funboost.core.task_id_logger import TaskIdLogger
import nb_log
from funboost.funboost_config_deafult import FunboostCommonConfig
from nb_log import LogManager
LOG_FILENAME_QUEUE_FCT = 'queue_fct.log'
# 使用TaskIdLogger创建的日志配合带task_id的日志模板,每条日志会自动带上task_id,方便用户搜索日志,定位某一个任务id的所有日志。
task_id_logger = LogManager('namexx', logger_cls=TaskIdLogger).get_logger_and_add_handlers(
log_filename='queue_fct.log',
error_log_filename=nb_log.generate_error_file_name(LOG_FILENAME_QUEUE_FCT),
formatter_template=FunboostCommonConfig.NB_LOG_FORMATER_INDEX_FOR_CONSUMER_AND_PUBLISHER, )
# 如果不使用TaskIdLogger来创建logger还想使用task_id的日志模板,需要用户在打印日志时候手动传 extra={'task_id': fct.task_id}
common_logger = nb_log.get_logger('namexx2',formatter_template=FunboostCommonConfig.NB_LOG_FORMATER_INDEX_FOR_CONSUMER_AND_PUBLISHER)
@boost(BoosterParams(queue_name='queue_test_fct', qps=2, concurrent_num=5, log_filename=LOG_FILENAME_QUEUE_FCT))
def f(a, b):
# 以下的每一条日志都会自带task_id显示,方便用户串联起来排查问题。
fct.logger.warning('如果不想亲自创建logger对象,可以使用fct.logger来记录日志,fct.logger是当前队列的消费者logger对象')
task_id_logger.info(fct.function_result_status.task_id) # 获取消息的任务id
task_id_logger.debug(fct.function_result_status.run_times) # 获取消息是第几次重试运行
task_id_logger.info(fct.full_msg) # 获取消息的完全体。出了a和b的值意外,还有发布时间 task_id等。
task_id_logger.debug(fct.function_result_status.publish_time_format) # 获取消息的发布时间
task_id_logger.debug(fct.function_result_status.get_status_dict()) # 获取任务的信息,可以转成字典看。
# 如果 用户不是使用TaskIdLogger插件的logger对象,那么要在模板中显示task_id,
common_logger.debug('假设logger不是TaskIdLogger类型的,想使用带task_id的日志模板,那么需要使用extra={"task_id":fct.task_id}', extra={'task_id': fct.task_id})
time.sleep(2)
task_id_logger.debug(f'哈哈 a: {a}')
task_id_logger.debug(f'哈哈 b: {b}')
task_id_logger.info(a + b)
if random.random() > 0.99:
raise Exception(f'{a} {b} 模拟出错啦')
return a + b
if __name__ == '__main__':
# f(5, 6) # 可以直接调用
for i in range(0, 200):
f.push(i, b=i * 2)
f.consume()
运行如图:
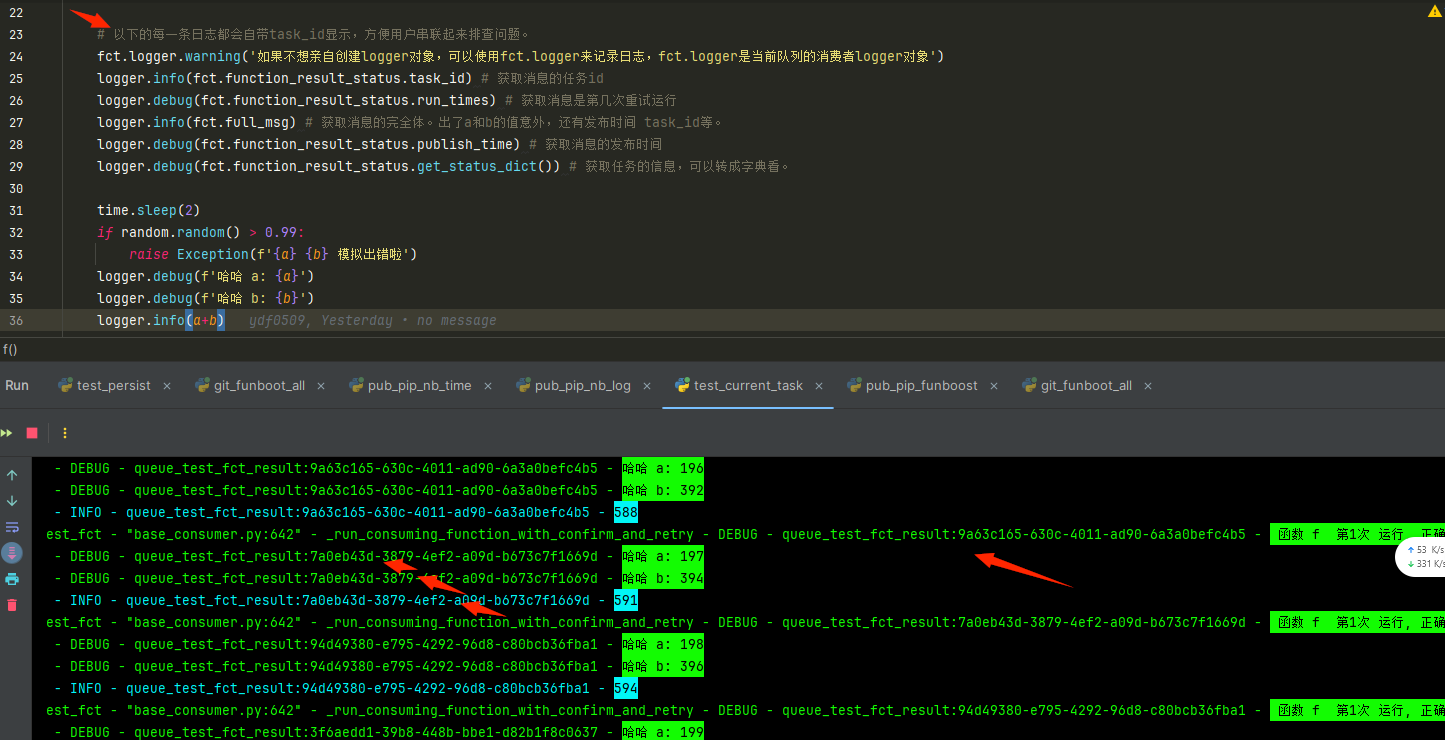
可以看到每条日志自动就显示了task_id, 这样的好处是可以通过搜索 task_id,来排查用户的某条消息的整条链路情况.
4b.1.3 一键全局使用 TaskIdLogger 代替 logging.Logger 的方式
import logging
logging.setLoggerClass(TaskIdLogger) # 越早运行越好,这样就不需要每次都设置TaskIdLogger来实例化logger了。
4b.1.4 能在消费函数的整个链路里面的调用的任意函数获取task_id的原理
fct 因为是线程 /协程 级别隔离的,就是线程/协程上下文.
4b.2 支持消费函数定义入参 **kwargs ,用于消费包含随机不确定keys(或者keys太多了)的json消息
相比Celery等工具,在4b.2和4b.2c 章节 ,funboost展现出极强的异构兼容性.
4b.2.0 funboost函数执行一条消息的最根本原理是 fun(**消息字典)
funboost push的背后
假设消费函数签名是 def task_fun(a,b,c,d,e):pass ,
那么funboost框架的 task_fun.push(1,2,3,4,5) ,会把 {"a":1,"b":2,"c":3,"d":4,"e":5} 这个字典转成json
发到消息队列. (当然funboost框架也会生成包含其他辅助字段,放到extra字段中,例如task_id,发布时间等等)
掌握funboost push背后原理,就可以知道怎么消费任意非funboost发布的已存在的json消息了
例如别的部门手动发布了 {"a":1,"b":2,"c":3,"d":4,"e":5} 这个json到消息队列,
那么用户消费函数定义成 def task_fun(a,b,c,d,e):pass ,
那么就可以消费到这个消息.
如果字段太多了或者或json的keys会发生变化,
那么可以按照两种方式:
4b.2.3 方式一 :消费函数定义成 def task_fun(**kwargs):pass ,来接受不定项的json keys
或者 def task_fun(**message) 也可以,此时 kwargs/message 就是这个json字典.
这是基本通用的python语法问题,用户可以问ai, fun(**字典) 是什么意思
4b.2.4 方式二 :消费函数定义成 def task_fun(my_msg):pass ,但 使用 _user_convert_msg_before_run,
生成一个新的字典/json, 把原始消息作为 my_msg 这个key的value
相当于是funboost识别到的消息是 {"my_msg":{"a":1,"b":2,"c":3,"d":4,"e":5}}
你用 task_fun(my_msg={"a":1,"b":2,"c":3,"d":4,"e":5}) 来调用 task_fun(my_msg) 签名的函数肯定合法
4b.2.1 演示错误的消费已存在json消息的例子,企图使用 def task_fun(message) 的函数签名来消费
例如别的部门手动发布了 {"a":1,"b":2,"c":3,"d":4,"e":5} 这个json到消息队列,
用户不是正确的定义一个 def task_fun(a,b,c,d,e):pass 的函数来消费,
而是错误的定义成了一个 def task_fun(message):pass 的函数,
用户错误的以为 message 会代表 {"a":1,"b":2,"c":3,"d":4,"e":5}
def task_fun(message) 这样肯定会报错啊 ,
框架相当于是使用 task_fun(a=1,b=2,c=3,d=4,e=5) 来调用 task_fun(message) 签名的函数,
肯定不行.函数入参个数和名字都不一样,咋能不报错.
小结:
面对已存在的 json消息 {"a":1,"b":2,"c":3,"d":4,"e":5}
1)这样写消费函数正确 def task_fun(a,b,c,d,e):pass ,json的一级keys和消费函数入参名字一一对应可以. 2)这样写消费函数正确 def task_fun(**message):pass , **message 可以接受不定项的函数入参, 此时message就是消息字典,可以用 message["a"] 来获取a的值. 3)这样写消费函数不正确 def task_fun(message):pass ,json的一级keys和消费函数入参个数和名字压根不同, 肯定报错, 除非使用 _user_convert_msg_before_run 转化,把原始消息移到 message 这个一级key中.
4b.2.3 方式一: 使用 **kwargs 方式 消费随机keys (或者json的一级keys太多不想逐个定义消费函数入参的情况)
例如消息是json格式,但是消息一会儿是 {"a":1,"b":2},一会是 {"c":3,"d":4,"e":5}, 如果要消费这个消息,消费函数不能固定写死成 def task_fun(a,b):
那么可以定义成 def task_fun(**kwargs):
有时候,消息是已存在的,而且别的部门没有使用funboost,且消息中字段达到几十上百个,用户不希望一个个字段的来定义消费函数入参.
如果是funboost来发布不定项的入参(json键名字随机不确定),通过设置 should_check_publish_func_params=False,让 publisher 不再校验发布入参
代码如下:
"""
Funboost 消费任意 JSON 消息格式完整示例(兼容非 Funboost 发布)
Funboost 天然支持消费任意 JSON 消息,且不要求任务必须通过 Funboost 发布,具备极强的异构兼容性与消息格式容忍度,
这在实际系统中大大降低了对接成本与协作门槛。
相比之下,Celery 的格式封闭、消息结构复杂,使得跨语言对接几乎不可能,这一点 Funboost 完胜。
"""
import time
import redis
import json
from funboost import boost, BrokerEnum, BoosterParams, fct,ctrl_c_recv
@boost(boost_params=BoosterParams(queue_name="task_queue_name2c", qps=5,
broker_kind=BrokerEnum.REDIS,
log_level=10, should_check_publish_func_params=False
)) # 入参包括20种,运行控制方式非常多,想得到的控制都会有。
def task_fun(**kwargs):
print(kwargs)
print(fct.full_msg)
time.sleep(3) # 框架会自动并发绕开这个阻塞,无论函数内部随机耗时多久都能自动调节并发达到每秒运行 5 次 这个 task_fun 函数的目的。
if __name__ == "__main__":
redis_conn = redis.Redis(db=7) # 使用原生redis来发布消息,funboost照样能消费。
for i in range(10):
task_fun.publish(dict(x=i, y=i * 2, x3=6, x4=8, x5={'k1': i, 'k2': i * 2, 'k3': i * 3})) # 发布者发布任务
task_fun.publisher.send_msg(dict(y1=i, y2=i * 2, y3=6, y4=8, y5={'k1': i, 'k2': i * 2, 'k3': i * 3})) # send_msg是发送原始消息
# 用户和其他部门的java golang员工发送的自由格式任意消息,也能被funboost消费,也即是说无视是否使用funboost来发消息,funboost都能消费。
# funboost消费兼容性太强了,这一点完爆celery。
redis_conn.lpush('task_queue_name2c',json.dumps({"m":666,"n":777}))
task_fun.consume()
ctrl_c_recv()
运行如图:
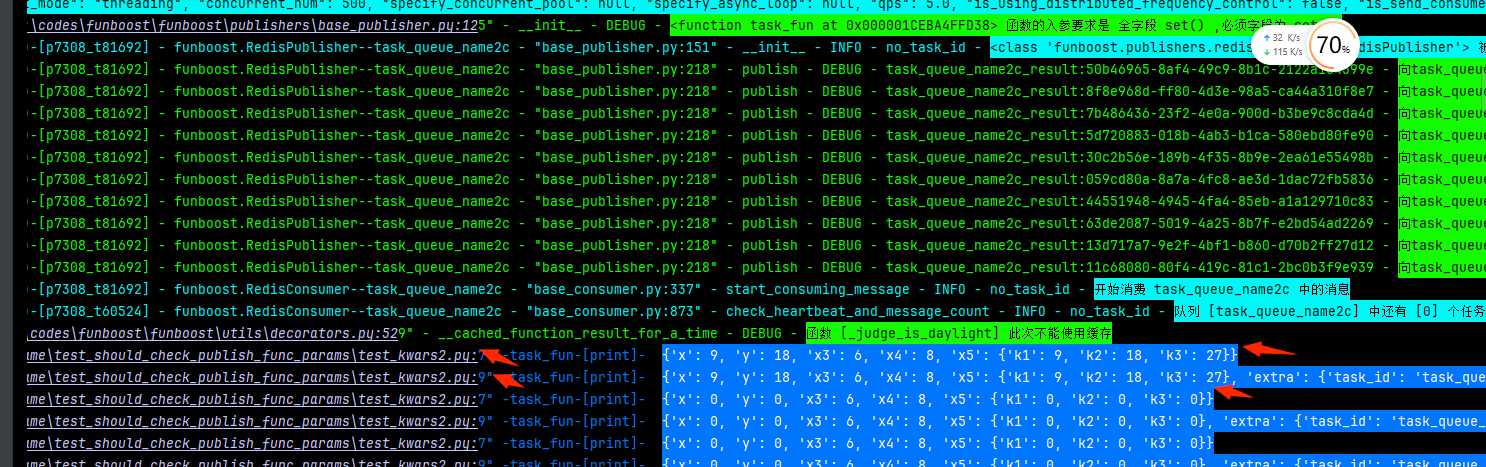
假设 task_queue_name2c 队列是别的部门发布的,或者你希望向 task_queue_name2c 队列中发布任意消息,那么可以使用send_msg
或者通过设置 should_check_publish_func_params=False 后使用 push或者publish来发布消息.
这样task_fun 支持消息任意消息,只要消息是json就行了.
4b.2.4 方式二: 使用 下面的 4b.2c 中章节的 强力灵活的 _user_convert_msg_before_run 方式,来消费随机keys或者keys太多的json
假如已存在的消息json是 {"a":1,"b":2,"c":3,""d":4,"e":5 ..........} ,有100多个keys.
如果funboost正常能消费情况下,需要
@boost(BoosterParams(....))
def task_fun(a,b,c,d,e .......): # 消费函数入参需要定义100多个,这太恐怖了.
方式一: 上面的消费函数入参定义成 **kwargs 来解决问题
方式二: 可以使用下面代码方式,将json重新放到一个函数入参中,函数只需要定义一个入参:
class MyTooManyKeysJsonConvetConsumer(AbstractConsumer):
def _user_convert_msg_before_run(self, msg) -> typing.Union[dict,str]:
# 这是核心关键,把整个很长的json放到一个my_msg字段中,因为消费函数签名是 task_fun(my_msg)
return {"my_msg":json.loads(msg)}
@BoosterParams(...,consumer_override_cls=MyTooManyKeysJsonConvetConsumer) # 指定你的自定义类
def task_fun(my_msg): # 函数只定义一个入参,例如 my_msg
print(my_msg) # 会打印出 {"a":1,"b":2,"c":3,""d":4,"e":5 ..........}
核心说明:
如果 task_fun(**{"a":1,"b":2,"c":3,""d":4,"e":5 ..........}) 来调用 task_fun(my_msg)的函数,
肯定会报错,函数名和个数都不正确,肯定报错,
所以使用 _user_convert_msg_before_run 把 这个超长的json放到 my_msg中,相当于是把消息清洗转化成了
{"my_msg":{"a":1,"b":2,"c":3,""d":4,"e":5 ..........}}
此时使用 task_fun(**{"my_msg":{"a":1,"b":2,"c":3,""d":4,"e":5 ..........}}) , 那就完全ok,
因为转化后的json消息一级keys只有一个 my_msg字段,task_fun(**{"my_msg":$任意东西}) 完全符合python语法.
4b.2c 更强力灵活的,funboost支持消费地球上一切任意格式的不规范消息(非json格式也能消费)
funboost 默认要求消息是JSON格式,因为内部需要通过 task_fun(**json.loads(json_str)) 的方式来调用消费函数。
即使消息队列中的消息不是从funboost发布的,也不是json,而是一个任意不规范内容的字符串,funboost也能消费.
celery 无法消费任意格式消息,funboost 能轻松做得到.
实现方式是:
继承并自定义 Consumer 类 (实际上也可以不继承,因为是mixin混入生成新类,继承是为了更好的ide中代码补全基类方法和属性)
重写
_user_convert_msg_before_run方法使用
consumer_override_cls参数
关于 consumer_override_cls 参数,用户可以看文档4.21章节详细介绍
4b.2c.1 例如funboost消费消息队列中已存在的消息 'a=1,b=2' 这种.
例如需求如下:
消费函数是 def task_fun(a: int, b: int)
但消息队列中消息是 'a=1,b=2' , 用户在函数运行前自定义转化消息格式,转换成字典或者json字符串.
因为funboost中实际需要使用 task_fun(**{"a":1,"b":2}) 来调用消费函数.
demo代码例子如下:
"""
此代码演示 funboost 强大的 消息格式兼容能力, 能消费一切任意队列中已存在的不规范格式的消息(消息格式不是json也能消费),
无论你是否使用funboost来发布消息,无视你的消息是不是json格式,funboost一样能消费.
通过用户自定义 _user_convert_msg_before_run 清洗转化消息成字典或者json字符串,funboost就能消费任意消息.
这是个小奇葩需求,但是funboost在消费任意消息的简单程度这方面能吊打celery
"""
import typing
import redis
from funboost import BrokerEnum, BoosterParams, AbstractConsumer
class MyAnyMsgConvetConsumer(AbstractConsumer):
def _user_convert_msg_before_run(self, msg) -> typing.Union[dict,str]:
# 'a=1,b=2' 例如从这个字符串,提取出键值对,返回新字典或者json字符串,以适配funboost消费函数的入参签名
new_msg = {}
msg_split_list = msg.split(',')
for item in msg_split_list:
key, value = item.split('=')
new_msg[key] = int(value)
self.logger.debug(f'原来消息是:{msg},转换成的新消息是:{new_msg}') # 例如 实际会打印 原来消息是:a=3,b=4,转换成的新消息是:{'a': 3, 'b': 4}
return new_msg
@BoosterParams(queue_name="task_queue_consume_any_msg", broker_kind=BrokerEnum.REDIS,
consumer_override_cls=MyAnyMsgConvetConsumer # 这行是关键,MyAnyMsgConvetConsumer类自定义了_user_convert_msg_before_run,这个方法里面,用户可以自由发挥清洗转化消息
)
def task_fun(a: int, b: int):
print(f'a:{a},b:{b}')
return a + b
if __name__ == "__main__":
redis_conn = redis.Redis(db=7) # 使用原生redis来发布消息,funboost照样能消费。
redis_conn.lpush('task_queue_consume_any_msg', 'a=1,b=2') # 模拟别的部门员工,手动发送了funboost框架无法识别的消息格式,原本funboost需要消息是json,但别的部门直接发字符串到消息队列中了.,
task_fun.publisher.send_msg('a=3,b=4') # 使用send_msg 而非push和publish方法,是故意发送不规范消息, 就是发送原始消息到消息队列里面,funboost不会去处理添加任何辅助字段发到消息队列里面,例如task_id 发布时间这些东西.
task_fun.consume() # funboost 现在可以消费消息队列里面的不规范消息了,因为用户在_user_convert_msg_before_run清洗了消息
4b.2c.2 例如,funboost消费队列中已存在的 "1000123"(假设是纯粹的用户id) 这种非json消息
funboost 默认要求消息是JSON格式,因为内部需要通过 task_fun(**json.loads(json_str)) 的方式来调用消费函数。但如果消息队列中已存在大量非JSON的简单字符串消息(例如,仅包含一个用户ID),funboost 同样可以轻松消费。
场景:
处理方式和 4b.2c.1 章节一样,用户可以自定义 _user_convert_msg_before_run 来清洗转化消息成字典或者json字符串,funboost就能消费这些消息.
class MyUserIDMsgConvetConsumer(AbstractConsumer):
def _user_convert_msg_before_run(self, msg)
"""返回新字典或者json字符串,以适配funboost消费函数的入参签名"""
# 这是关键核心,因为消费函数签名是 task_fun(user_id)
return {"user_id":int(msg)}
@BoosterParams(...,consumer_override_cls=MyUserIDMsgConvetConsumer) # 指定你的自定义类
def task_fun(user_id:int):
pass
这个例子清晰地展示了如何通过一小段定制代码,让 funboost 具备消费任意格式消息的能力,这在集成遗留系统或与第三方跨部门系统对接时尤其有用。
举一个`celery`无能为力的场景,`celery`无法消费`canal` 或者 `Debezium ` 或者 `Maxwell` 或者 `flink cdc` 发到`kafka`的`binlog`消息, 但funboost轻松做得到. `funboost`可以使用`def fun(**calnal_message)` 消费`canal`的json消息,不用一个个声明入参和`canal`的json消息keys 一一对应匹配. `funboost`也可以使用 `_user_convert_msg_before_run`来转换`canal`消息 你不可能要求运维人员改造 `canal` 适配 `celery` 的消息格式协议吧,这怎么可能?
4b.3 funboost + 全asyncio 编程生态演示
funboost 对 asyncio 编程生态的直接性支持远超 celery.
全套的asyncio生态,不仅包括了消费支持async def函数,也包括发布消息支持asyncio生态,获取rpc结果支持asyncio生态。
为了与asyncio编程生态更搭配,新介绍 aio_push/aio_publish 和 AioAsyncResult 这些方法和类型.
此代码例子在 :
https://github.com/ydf0509/funboost/tree/master/test_frame/full_asyncio_demo
4b.3.1 funboost 天然支持 async def 的消费函数,和支持 aio_push 来异步发布消息.
下面funboost代码包含了同步函数和异步函数的消费的演示,包含了同步发布和异步发布的演示
ps: funboost的 concurrent_mode=ConcurrentModeEnum.THREADING 和 ConcurrentModeEnum.ASYNC 都支持 async def 函数。
注意对asyncio编程生态更友好的 aio_push 用法
import asyncio
import time
from funboost import boost,BrokerEnum,ConcurrentModeEnum,BoosterParams
# funboost 直接方便性支持 async def 函数逇消费,远超 celery对async 函数的支持
@boost(BoosterParams(queue_name='aio_long_time_fun_queue',is_using_rpc_mode=True,concurrent_mode))
async def aio_long_time_fun(x):
await asyncio.sleep(10)
print(f'aio_long_time_fun {x}')
return f'aio_long_time_fun {x}'
@boost(BoosterParams(queue_name='long_time_fun_queue',is_using_rpc_mode=True))
def long_time_fun(x):
time.sleep(5)
print(f'long_time_fun {x}')
return f'long_time_fun {x}'
if __name__ == '__main__':
async def aio_push_msg():
for i in range(10):
await aio_long_time_fun.aio_push(i)
asyncio.run(aio_push_msg()) # asyncio 发布消息到中间件演示
for j in range(10): # 同步发布消息到中间件演示
long_time_fun.push(j)
aio_long_time_fun.consume() # 启动消费,funboost 能直接性支持async def 的函数作为消费函数,这点上的方便性完爆celery对asycn def的支持.
long_time_fun.consume() # 启动消费
4b.3.2 演示fastapi 中aio_push来发布消息,和 AioAsyncResult asyncio方式 等待获取结果.
下面fastapi web代码是在 流行的 fastapi 中,演示aio_push发布和rpc
注意 AioAsyncResult 类的使用
千万别在fastapi接口中使用同步的AsyncResult.result,异步函数中调用同步且耗时大的函数,整个程序会阻塞产生灭顶之灾.
from fastapi import FastAPI
from funboost import AioAsyncResult
from consume_fun import aio_long_time_fun, long_time_fun
app = FastAPI()
@app.get("/")
async def root():
return {"Hello": "World"}
# 演示push同步发布, 并且aio rpc获取消费结果
@app.get("/url1/{name}")
async def api1(name: str):
async_result = long_time_fun.push(name) # 通常发布消息时间比较小,局域网内一般少于0.3毫秒,所以在asyncio的异步方法中调用同步io方法一般不会产生过于严重的灾难
return {"result": await AioAsyncResult(async_result.task_id).status_and_result} # 一般情况下不需要请求时候立即使用rpc模式获取消费结果,直接吧消息发到中间件后就不用管了.前端使用ajx轮训或者mqtt
# return {"result": async_result.result} # 如果你直接这样写代码,会产生所有协程全局阻塞灭顶之灾.
# 演示aio_push 异步发布, 并且aio rpc获取消费结果
@app.get("/url2/{name}")
async def api2(name: str):
asio_async_result = await aio_long_time_fun.aio_push(name) # 如果你用的是asyncio编程生态,那还是建议这种,尤其是对外网发布消息会耗时大的情况下.
return {"result": await asio_async_result.result} # 一般情况下不需要请求时候立即使用rpc模式获取消费结果,直接吧消息发到中间件后就不用管了.前端使用ajx轮训或者mqtt
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
运行web服务,浏览器中输入 http://127.0.0.1:8000/url1/name_xxx1
就能请求接口并发布消息,并获得消费结果.
4b.3.3 关于funboost的asyncio生态支持实现原理的答疑
消费是怎么支持async def 函数并发的?
funboost的 concurrent_mode=ConcurrentModeEnum.THREADING 和 ConcurrentModeEnum.ASYNC 都支持 async def 函数。
ConcurrentModeEnum.THREADING 相当于在线程池的每个线程内部,每个线程有一个单独loop,每个线程里面 loop.run_until_complete 来运行协程的。
使用的并发池是 funboost/concurrent_pool/flexible_thread_pool.py 的FlexibleThreadPool, 这个线程池不仅能支持同步函数,还能顺带兼容支持运行异步函数。
这是作者亲自开发的可变线程池(可自动缩小)
ConcurrentModeEnum.ASYNC 并发模式,是真正的让每个消费队列的函数协程任务运行在同一个单独的 loop 中。
使用的并发池是 funboost/concurrent_pool/async_pool_executor.py 的 AsyncPoolExecutor ,这个是 专用的asyncio并发池,
这个并发池只能用于执行async 异步函数,不支持运行同步函数。
这是作者开发的准用asyncio协程池。
从消息队列中间件获取消息是io的,为什么源码的各种消息队列三方包都是同步的包?
因为获取消息,是每个队列在一个进程里面,有且只有一个单独的独立的线程中去消息队列中间件获取消息,所以不存在并发的去拉取消息,在单个进程同个队列名,拉取消息不存在并发。
所以这个无需异步包。
await funxx.aio_push 发布消息是咋实现的?为什么源码的各种消息队列三方包都是同步的包?
一般内网中发布一个消息少于1毫秒,即使在你的asyncio项目生态中使用同步的funxx.push来发布消息,也不会造成长时间严重的阻塞,
但是funboost仍然开发了独立的 funxx.aio_push 来更好的搭配asyncio生态,这样你就不用担心发布消息耗时大阻塞loop了。
funboost没有使用各种异步消息队列包,咋搞定异步发布消息的?
funboost使用万能的同步函数转异步函数的loop.run_in_executor实现,大大节约了使用各种异步包来重新开发一遍。这个用户看async def aio_push()方法源码即可。
AioAsyncResult 异步生态中获取rpc,避免使用同步方式来获取结果阻塞loop,如何实现的?
因为funboost 的不管任何中间件,如果用户要使用rpc获取结果功能,就需要用到redis,所以作者工作量不大,实现时候使用 redis5.asyncio.Redis 这个异步redis操作类就可以了。
async_result = add.push(i, i * 2)
aio_async_result = AioAsyncResult(task_id=async_result.task_id) # 这里要使用asyncio语法的类,更方便的配合asyncio异步编程生态
print(await aio_async_result.result) # 注意这里有个await,如果不await就是打印一个协程对象,不会得到结果。这是asyncio的基本语法,需要用户精通asyncio。
print(await aio_async_result.status_and_result)
所以使用 await aio_async_result.result 来获取结果,避免使用同步防暑来等待结果耗时长导致loop阻塞。
综上所述funboost亲自搞定asyncio是为了方便用户原有的asyncio编程项目中直接使用
funboost 内置搞定了asyncio生态中的用户函数并发,消息拉取,消息发布,rpc获取消息结果,所以可以直接天衣无缝搭配用户的asyncio编程项目。
4b.3.4 劝退不懂asyncio的loop是什么的小白,使用funboost + asyncio 来编程
非常的不建议普通python码农使用asyncio来装逼写代码。特别是打死都不愿意专门花费或者没有一周以上时间系统学习和测试 asyncio编程的pythoner。
有的人写的asyncio代码一看就太搞笑了,而且运行出了非常显而易见的低级asyncio问题他就很蒙蔽,这种情况下,真心的不建议再用asyncio来装逼写代码了。asyncio异步编程比同步编程难了2个数量级。
funboost的默认并发模式的线程池,是作者自己开发的超强效率的线程池,不是使用官方的 concurrnt.futures.ThreadpoolExecutor 那种通用线程池。用户用funboost的线程并发模式足以超级高效。
只有一种情况下,建议用户使用 funboost + asyncio来编程,那就是用户的工具包中所有可复用函数已经是asyncio写法,而且正在用的就是例如fastapi异步web框架,只有这种情况下才需要使用async def 来写funboost的消费函数,否则没有卵的必要用async来写消费函数。
特别是业余的 python 爱好者而非专业码农,真的不要在asyncio 生态下凑热闹了,用同步编程是真心的 省时间 省脑子 省bug。
不知道 funboost的用户是不是因为害怕celery的复杂api,才使用funboost框架,导致能了解到funboost框架的过滤出的都是害怕复杂python用法的非专业python用户,反正我强烈感觉到这些用户非常不熟悉asyncio,还强行要用asyncio,这种感觉尤为明显。 用户因为怕复杂才选择funboost,却又要强行使用比Celery概念更复杂得多的asyncio来写代码,有一丝丝矛盾
async def 的函数,定义协程函数本身不难,难的是如果要并发起来执行,要搞懂以下这些概念,
以下这些概念非常多十分之复杂,asyncio的并发玩法与同步函数 + 线程池并发写法区别很大,asyncio的并发写法难度大太多。
异步要想玩的溜,用户必须精通的常用方法和对象的概念包括以下:
asyncio.get_event_loop 方法
asyncio.new_event_loop 方法
asyncio.set_event_loop 方法
asyncio.ensure_future 方法
asyncio.create_task 方法
asyncio.wait 方法
asyncio.wait_for 方法
asyncio.gather 方法
asyncio.run_coroutine_threadsafe 方法
asyncio.run 方法
loop.run_in_executor 方法
run_until_complete 方法
run_forever 方法
loop 对象
future 对象
task 对象
corotinue 对象
以上这些方法和对象还只是asyncio的冰山一角,实际需要掌握的常见api达到30多个,只有掌握了这些才能在同步上下文和异步上下文切换自如。
例如在同步场景下怎么调用一个async的函数,在异步场景下怎么调用一个普通def的同步函数且不阻塞整个loop,并且对 loop 和协程对象的概念非常精通。
asyncio的API比threading复杂得多主要有以下原因:
执行模型的根本区别:
threading基于操作系统线程,执行切换由OS控制,概念简单直接
asyncio基于事件循环和协程的协作式多任务,需要显式管理事件循环和任务状态
显式切换点要求:
threading中线程切换对开发者透明
asyncio需要使用await显式标记可能的切换点,增加了编程复杂度
全新的语法结构:
asyncio引入了async/await语法,创建了同步与异步两套平行世界
需要学习两套上下文及其转换方法(run_in_executor等)
事件循环管理:
asyncio需要显式创建、运行、停止事件循环
需要了解不同运行模式(run_forever, run_until_complete等)
异步原语与同步替代:
需要提供几乎所有同步操作的异步替代品(异步文件IO、网络IO等)
引入了Future、Task、Coroutine等多种抽象概念
兼容性考虑:
asyncio是后期添加到Python的,需要与现有生态系统兼容
不能破坏原有代码,导致设计上更为复杂
threading的API简单是因为它将复杂性下放给了操作系统,而asyncio则需要在Python层面实现和管理整个并发模型。
综上所述,虽然在funboost中是能方便支持async def函数的消费,对asyncio的直接内置支持远超celery,但是不鼓励非专业资深码农使用async def来定义消费函数。
4b.3.4.2 想在funboost中玩的溜asyncio实际比例如fastapi这种框架中使用asyncio 更难。
因为 FastAPI完全隐藏了事件循环管理 ,是在主线程中运行 loop和协程,基本上只在主线程中去运行loop和协程对象,管理和运行起来简单多得多。
funboost 是在很多个子线程中运行不同的loop ,难度比主线程中管理大多了;
这种线程与协程混合使用的场景确实是asyncio最复杂的应用场景之一,即使有经验的Python开发者也容易在此栽跟头和无法理解。
特别是例如一个全局变量对象 async_obj 绑定了一个loop,而你想在funboost的消费函数中去运行 async_obj 的方法,
实际上已经属于跨线程去使用这个async_obj了,这需要你有非常高超的精通asyncio概念的知识储备。
这种async_obj 经常是一个异步的httpclient或者 数据库连接,他实际上不能很简单的随意在多个线程中去跨线程使用这个对象。
在主线程中常见的异步数据库连接,实际上不能很简单的直接就在其他线程中使用这个对象执行查询数据的方法;
在主线程中常见的异步http连接,实际上不能很简单的直接就在其他线程中使用这个对象执行发送http请求;
我说的这只有经常在这种情况下实践排查过bug的人才能懂,一般人都不知道我现在在讲的是什么。
所以 有的人对 funboost装饰器的 specify_async_loop完全不懂,
specify_async_loop: typing.Optional[asyncio.AbstractEventLoop] = None # 指定的async的loop循环,设置并发模式为async才能起作用。
有些包例如aiohttp,发送请求和httpclient的实例化不能处在两个不同的loop中,可以把loop传过来,使得运行消费函数的线程在使用的loop和这个全局变量的loop是同一个。
默认情况下,不同的线程是不会去运行同一个loop的。
Python的asyncio设计中,事件循环(event loop)默认与创建它的线程绑定,不能简单地跨线程共享使用。这导致:
主线程创建的异步对象(如aiohttp客户端)绑定了主线程的loop
funboost的消费函数在工作线程中运行,有自己的loop
当尝试在工作线程中使用主线程创建的异步对象时会出现冲突
这就是为什么需要specify_async_loop参数 - 它允许不同的工作线程使用同一个loop,解决了这个跨线程asyncio对象共享的复杂问题。
这种问题即使对有经验的Python开发者也非常棘手,因为它涉及asyncio内部实现细节和线程安全问题,不是简单阅读文档就能理解的。
就是想劝退小白使用asyncio + funboost 编程。
4b.3.5 演示funboost解决 ,async并发模式,由于跨线程loop 操作任何socket连接池 的报错,
使用指定的 specify_async_loop 即可解决.
这个放在自问自答 6.26 章节有源码注释演示,太多人不看文档,不看boost装饰器的入参解释说明.不看 specify_async_loop 入参解释造成的.
asyncio的经典报错 attached to a different loop 和 context manager should be used inside a task
attached to a different loop 报错原因:
这个错误通常发生在 对象(如 Future、Task、协程)在一个事件循环中创建,却在另一个事件循环中被使用。
RuntimeError: Timeout context manager should be used inside a task 报错原因:
异步上下文管理器(如timeout)不在Task中运行
很多人在async def消费函数中去操作http连接池 发请求,操作数据库连接池查询数据,在funboost中报错.
根本原因是用户不传递指定 specify_async_loop, 如果不传递,funboost是独立线程中启动了一个新的loop,
用户的连接池绑定的是主线程的loop,如果使用子线程的新loop去使用这个连接池查询数据库,那就会导致报错.
只在主线程中操作asyncio协程的pythoner,永远无法理解这个知识点,需要用户多练习在子线程去操作数据库连接池或者http连接池,才能踩坑积累经验.
用户需要始终知道 ASYNC 并发模式 第一性原理,才知道怎么根本解决问题
切记切记,funboost 的 ASYNC 并发模式的核心底层原理, funboost,当用户使用 ASYNC 并发模式时候,是自动使用 AsyncPoolExecutor 来执行用户函数, AsyncPoolExecutor 源码在 funboost/concurrent_pool/async_pool_executor.py AsyncPoolExecutor 原理是启动了一个线程,这个线程会使用传递的specify_async_loop,如果不传递就会新创建1个loop, 这个loop会运行指定的 concurrent_num 个cron 协程,去运行用户的消费函数逻辑 也就是说AsyncPoolExecutor线程只有一个,loop只有一个,真正的一个loop并发运行cron协程 用 loop2 去运行 loop1 创建的协程,不报错才怪
即使是funboost 的 thereding 并发模式也可以直接运行async def 函数,funboost对async的支持完爆celery
funboost 的 thereding 并发模式也可以直接@boost装饰加到async def 函数,
因为funboost是特制的神级别线程池,能自动运行async def 函数.
但这个模式下简单粗暴,会开启 concurrent_num 个线程,每个线程有自己的loop,去运行用户的async函数,
相当于是每个loop只并发运行一个cron协程,不是真asyncio级别并发
相当于是有无数线程,每个线程一个loop,去运行用户的async函数
funboost的 thereding 并发模式运行async,就是celery 任务中强行使用 asyncio.new_event_loop().run_until_complete(async函数)
但是funboost是特制的神级别线程池 FlexibleThreadPool,这个线程池自动可以运行async def 函数,
无需用户为了运行async def 函数,去手写一个脱了裤子放屁的 同步def 函数,
也就是用户无需这种脱了裤子放屁的写法:
@boost(BoosterParams(queue_name='test_async_queue2', concurrent_mode=ConcurrentModeEnum.THREADING))
def 同步fun(x,y)
asyncio.new_event_loop().run_until_complete(async异步函数(x,y)) #同步里面调用异步函数
用户可以直接使用THREADING 并发模式加到 async def async异步函数:
@boost(BoosterParams(queue_name='test_async_queue2', concurrent_mode=ConcurrentModeEnum.THREADING))
async def async异步函数(x,y)
pass
celery的运行协程才需要脱落裤子放屁再加个同步函数里面run_until_complete调用异步函数,才能@app.task
4b.4 等待n个任务完成后,再做下一步操作(其实就是canvas任务编排)
之前在 4.17文档章节: 判断函数运行完所有任务,再执行后续操作,使用 wait_for_possible_has_finish_all_tasks来判断函数的消息队列是否已经运行完了。
但是有的人在问怎么实现n个任务完成后,再下一步操作。
这没有单独的语法方法,就是借助了rpc等待结果会阻塞的特性。
直接上代码:
# -*- coding: utf-8 -*-
import time
from funboost import BoosterParams, BrokerEnum
@BoosterParams(queue_name='test_rpc_queue_a1', is_using_rpc_mode=True, broker_kind=BrokerEnum.REDIS_ACK_ABLE, qps=2, max_retry_times=5)
def f1(x):
time.sleep(5)
async_result_list = [f2.push(x + i) for i in range(10)]
for async_result in async_result_list:
async_result.set_timeout(300)
print(async_result.task_id, async_result.status_and_result, async_result.result)
print('f2 10个任务都完成了,现在开始进行下一步,打印哈哈。')
print('哈哈')
@BoosterParams(queue_name='test_rpc_queue_a2',
is_using_rpc_mode=True, # f2必须支持rpc,必须写is_using_rpc_mode=True
broker_kind=BrokerEnum.REDIS_ACK_ABLE,
qps=5, max_retry_times=5)
def f2(y):
time.sleep(10)
return y * 10
if __name__ == '__main__':
f1.consume()
f2.consume()
for j in range(20):
f1.push(j)
例子解释:
f1 每个任务会分解10个子任务到f2中运行, 并且f1中要等待10个子任务全部完成后,才开始执行下一步,打印 "哈哈"
4b.5 funboost 原生任务编排(实现canvas功能)
tips: 用户可以对比 4b.8章节,funboost使用类似celery的声明式的任务编排语法
"""
此文件演示, funboost 使用 rpc获取结果阻塞的特性,来实现 canvas编排
可以把一个函数的结果作为下一个函数的入参,来实现 canvas编排
无需学习新的领域特定语言(DSL) 没有发明新的语法.funboost没有为工作流编排引入任何新的、专门的 API
整个编排过程就是调用 funboost 已有的 .push() / .aio_push() 和 .wait_rpc_data_or_raise() 方法。
开发者不需要去学习和记忆 chain, chord, group,header,body, s (signature), si,s(immutable=True), map,starmap
等特定的 Canvas 概念和语法,降低了学习成本。
这一切都是用户主动使用funboost的rpc特性来实现,用户可以自由灵活控制
"""
"""
此文件演示一个非常经典的canvas编排:
1.从url下载视频,并保存到本地 (download_video)
2.根据第1步下载的视频文件,转码视频,并发转换成3个分辨率的视频文件 (transform_video)
3.根据第2步转码的视频文件列表,更新数据库,并且发送微信通知 (send_finish_msg)
这个需求如果在celery的canvas编排是如下:
from celery import chain, chord, group
resolutions = ["360p", "720p", "1080p"]
# header: 并行转码;body: 汇总并发送完成消息
header = group(transform_video.s(resolution=r) for r in resolutions)
body = send_finish_msg.s(url=url)
# 先下载 -> 将下载结果(文件路径)作为额外参数传给 header 中每个 transform_video
work_flow = chain(
download_video.s(url),
chord(header, body)
)
"""
"""
celery发明了一套声明式canvas api,用户需要学习新的语法,
funboost是命令式,全部使用已有的rpc方法,没有一套声明式api
"""
import typing
import os
import sys
import time
from funboost import (boost, BoosterParams, BrokerEnum, ctrl_c_recv,
ConcurrentModeEnum, AsyncResult,FunctionResultStatus,
BoostersManager, AioAsyncResult, fct
)
class MyBoosterParams(BoosterParams):
is_using_rpc_mode: bool = True
broker_exclusive_config: dict = {'pull_msg_batch_size': 1}
broker_kind: str = BrokerEnum.REDIS_ACK_ABLE
max_retry_times: int = 0
@boost(MyBoosterParams(queue_name='download_video_queue'))
def download_video(url):
"""下载视频"""
# 1/0 # 这个是模拟 任务编排,其中某个环节报错
mock_need_time = 5
time.sleep(mock_need_time)
download_file = f'/dir/vd0/{url}'
fct.logger.info(f'下载视频 {url} 完成, 保存到 {download_file},耗时{mock_need_time}秒')
return download_file
@boost(MyBoosterParams(queue_name='transform_video_queue'))
def transform_video(video_file, resolution='360p'):
"""转码视频"""
mock_need_time = 10
time.sleep(mock_need_time)
transform_file = f'{video_file}_{resolution}'
fct.logger.info(f'转码视频 {video_file} 完成, 保存到 {transform_file},耗时{mock_need_time}秒')
return transform_file
@boost(MyBoosterParams(queue_name='send_finish_msg_queue'))
def send_finish_msg(transform_video_file_list: list, url):
"""3个清晰度的视频都转码完成后,汇总结果发送微信通知"""
mock_need_time = 2
time.sleep(mock_need_time)
fct.logger.info(f'更新数据库,并且发送微信通知 {url} 视频转码完成 {transform_video_file_list} ,耗时{mock_need_time}秒')
return f'ok! {url} 下载 -> 转码3个清晰度格式视频 {transform_video_file_list} -> 更新数据库,发送微信通知 完成'
@boost(MyBoosterParams(queue_name='canvas_task_queue',concurrent_num=500))
def canvas_task(url):
"""
funboost显式的把上一个函数交给或者结果列表传递给下一个函数,思路很清晰.用户可以在里面写各种if else判断,
以及上一个节点错误是否还调用下一个节点.
celery的canvas 自动把上一个函数的结果作为下一个函数的第一个入参,那里面的传递关系不清晰关系不明显不符合直觉,不透明.
如果涉及到非常复杂的编排,用户很难使用celery 的语法写出正确的canvas编排,还不如使用rpc清晰易懂.
"""
r1: AsyncResult = download_video.push(url).set_timeout(1000) # 用户可以设置rpc最大等待时间.
rpc_res_file:FunctionResultStatus = r1.wait_rpc_data_or_raise(raise_exception=True)
r2_list: typing.List[AsyncResult] = [transform_video.push(rpc_res_file.result, resolution=rel)
for rel in ['360p', '720p', '1080p']]
rpc_res_list = AsyncResult.batch_wait_rpc_data_or_raise(r2_list, raise_exception=True)
transform_video_file_list = [one.result for one in rpc_res_list]
r3 = send_finish_msg.push(transform_video_file_list, url)
return r3.wait_rpc_data_or_raise(raise_exception=True).result
@boost(MyBoosterParams(queue_name='aio_canvas_task_queue',
concurrent_mode=ConcurrentModeEnum.ASYNC, # 使用asyncio异步阻塞的方式来实现canvas编排
concurrent_num=500))
async def aio_canvas_task(url):
# 用户自己对比和canvas_task的相同点和差异.
"""演示 ,使用asyncio 来等待rpc结果, 减少系统线程占用数量"""
r1: AioAsyncResult = await download_video.aio_push(url)
rpc_res_file:FunctionResultStatus = await r1.wait_rpc_data_or_raise(raise_exception=True)
r2_list: typing.List[AioAsyncResult] = [(await transform_video.aio_push(rpc_res_file.result, resolution=rel)).set_timeout(2000)
for rel in ['360p', '720p', '1080p']]
rpc_res_list = await AioAsyncResult.batch_wait_rpc_data_or_raise(r2_list, raise_exception=True)
transform_video_file_list = [one.result for one in rpc_res_list]
r3 = await send_finish_msg.aio_push(transform_video_file_list, url)
return (await r3.wait_rpc_data_or_raise(raise_exception=True)).result
if __name__ == '__main__':
download_video.consume()
transform_video.consume()
send_finish_msg.consume()
canvas_task.consume() # 演示使用同步阻塞的方式来实现canvas编排
aio_canvas_task.consume() # 演示使用asyncio异步阻塞的方式来实现canvas编排
r4_a = canvas_task.push(f'funboost_url_video_a')
print(r4_a.wait_rpc_data_or_raise(raise_exception=False).to_pretty_json_str())
print('funboost_url_video_a 下载->转码->通知 耗时', r4_a.rpc_data.time_cost)
r4_b = aio_canvas_task.push(f'funboost_url_video_b')
print(r4_b.wait_rpc_data_or_raise(raise_exception=False).to_pretty_json_str())
print('funboost_url_video_b 下载->转码->通知 耗时', r4_b.rpc_data.time_cost)
ctrl_c_recv()
4b.6 @boost装饰器 user_options 入参的妙用
@boost装饰器 user_options 是用户域传参,用户可以自由发挥,存放任何设置.
有些用户想实现一些奇葩需求,但是框架没有提供,自己加入参,又要改 BoosterParams 源码来加装饰器参数,非常麻烦.
user_options 是一个字典,字典就非常灵活了,因为字典可以放任意传参.
user_options 是用户额外自定义的配置,高级用户或者奇葩需求可以用得到,用户可以自由发挥,存放任何设置.
user_options 提供了一个统一的、用户自定义的命名空间,让用户可以为自己的“奇葩需求”或“高级定制”传递配置,而无需等待框架开发者添加官方支持。
funboost 是自由框架不是奴役框架,不仅消费函数逻辑自由,目录层级结构自由,自定义奇葩扩展也要追求自由,用户不用改funboost BoosterParams 源码来加装饰器参数
例如场景1:
假设框架装饰器不内置提供 BoostersManager.consume_group(booster_group) ,用户想启动一组相关消费函数,
可以传递 user_options={'booster_group': 'group1'} 来实现,然后for循环判断所有boosters
if booster.boost_params.user_options['booster_group'] == 'group1' 来启动消费组
例如场景2:
funboost框架目前是只能消费一个kafka KAFKA_BOOTSTRAP_SERVERS,这个配置是在 funboost_config.py 定义的,但这也意味着项目只能使用一个全局的kafka集群.
用户可以按照文档4.21 自定义consumer和publisher,用户的类不读取funboost_config.py 的kafka KAFKA_BOOTSTRAP_SERVERS,
而是读取 user_options 中的kafka KAFKA_BOOTSTRAP_SERVERS,
在使用时候,装饰器传递不同的 user_options={'kafka_bootstrap_servers': '192.168.1.10x'} ,
达到消费几十个不同的kafka集群的目的.
4b.6.1场景一: user_options “反向实现” consume_group**
这是一个绝佳的例子,证明了 user_options 的强大赋能作用。假设我当初没有开发 BoostersManager.consume_group 功能,一个聪明的用户完全可以利用 user_options 自己实现一个类似的功能:
# 在消费者定义中
@boost(BoosterParams(queue_name="q1", user_options={'module': 'billing'}))
def process_payment(payment_id): ...
@boost(BoosterParams(queue_name="q2", user_options={'module': 'billing'}))
def generate_invoice(invoice_id): ...
# 在启动脚本中
if __name__ == '__main__':
for queue_name in BoostersManager.get_all_queues():
booster = BoostersManager.get_booster(queue_name)
# 通过 user_options 自己实现按组启动
if booster.boost_params.user_options.get('module') == 'billing':
booster.consume()
ctrl_c_recv()
场景二: user_options 多租户与覆盖全局配置(以Kafka集群做例子)
这是 user_options 的一个杀手级应用。funboost_config.py 中通常定义一个全局的 Kafka 集群地址, 如果用户需要操作几十个kafka 集群, 而 funboost_config.py 中的 kafka_bootstrap_servers 只能是某1个集群地址,一个项目怎么操作消费几十个kafka集群? 这个场景在大数据消费是 非常普遍的,通常有十几个不同的kafka集群.
没有 user_options,用户可以使用不同的配置文件或者环境变量,对不同的kafka集群分多次启动消费函数。有了它,解决方案变得异常清晰:
这部分代码演示,使用了consumer_override_cls,可以看文档4.21章节 :
在消费者定义时,通过
user_options传入特殊配置:
@boost(BoosterParams(
queue_name='special_auditing_task',
consumer_override_cls=CustomKafkaConsumer, # 使用一个自定义的消费者
user_options={'kafka_bootstrap_servers': '10.0.0.100:9092,10.0.0.101:9092'}
# 通过 user_options 对不同的消费函数可以传递不同的kafka集群地址,而不是只能固定全部使用funboost_config.py 中的kafka集群地址,
# 轻松操作几十个kafka集群
))
def auditing_task(data): ...
在自定义消费者
CustomKafkaConsumer中,优先读取user_options的配置:
class CustomKafkaConsumer(KafkaConsumerManuallyCommit):
def _dispatch_task(self):
# 优先从 user_options 读取 kafka 地址,如果不存在,则回退到 funboost_config.py 的全局配置
bootstrap_servers = self.consumer_params.user_options.get(
'kafka_bootstrap_servers',
BrokerConnConfig.KAFKA_BOOTSTRAP_SERVERS
)
self._confluent_consumer = ConfluentConsumer({
'bootstrap.servers': ','.join(bootstrap_servers),
# ... 其他配置 ...
})
# ... 剩余的调度逻辑 ...
这种方式实现了**“配置与任务定义 co-located(配置与任务定义 co-located)”**,使得特殊配置清晰可见,且与对应的任务绑定,极大地提高了代码的可读性和可维护性。
4b.7 opentelemetry 全链路任务追踪,funboost生产级别的重要战略级功能 (高级功能)
使用方式: 使用方式,就是可以直接使用
OtelBoosterParams
或者你在你的BoosterParams中指定consumer_override_cls和publisher_override_cls为OtelConsumerMixin和OtelPublisherMixin。
from funboost.contrib.override_publisher_consumer_cls.funboost_otel_mixin import (
OtelBoosterParams
)
@boost(OtelBoosterParams(
queue_name='otel_demo_task_process',
))
def fun(x,y):
return x+y
opentelemetry这个是可选功能,funboost默认是不开启的。毫无疑问。OpenTelemetry (OTel) 全链路追踪不仅是 Funboost 的战略级功能,更是它迈向“生产级、云原生架构”的里程碑。
实现方式: funboost不是在消息中去增加 只有funboost自身才能识别的额外字段,去实现独特的全链路任务追踪。 funboost是使用国际w3c的规范协议,采用基于最最知名的
opentelemetry实现全链路任务追踪。
全链路任务追踪包括,跨项目 跨语言 跨http服务,不限于只追踪funboost框架自身的发布和消费。
代码位置:
代码实现: funboost/contrib/override_publisher_consumer_cls/funboost_otel_mixin.py
使用demo: test_frame/test_otel
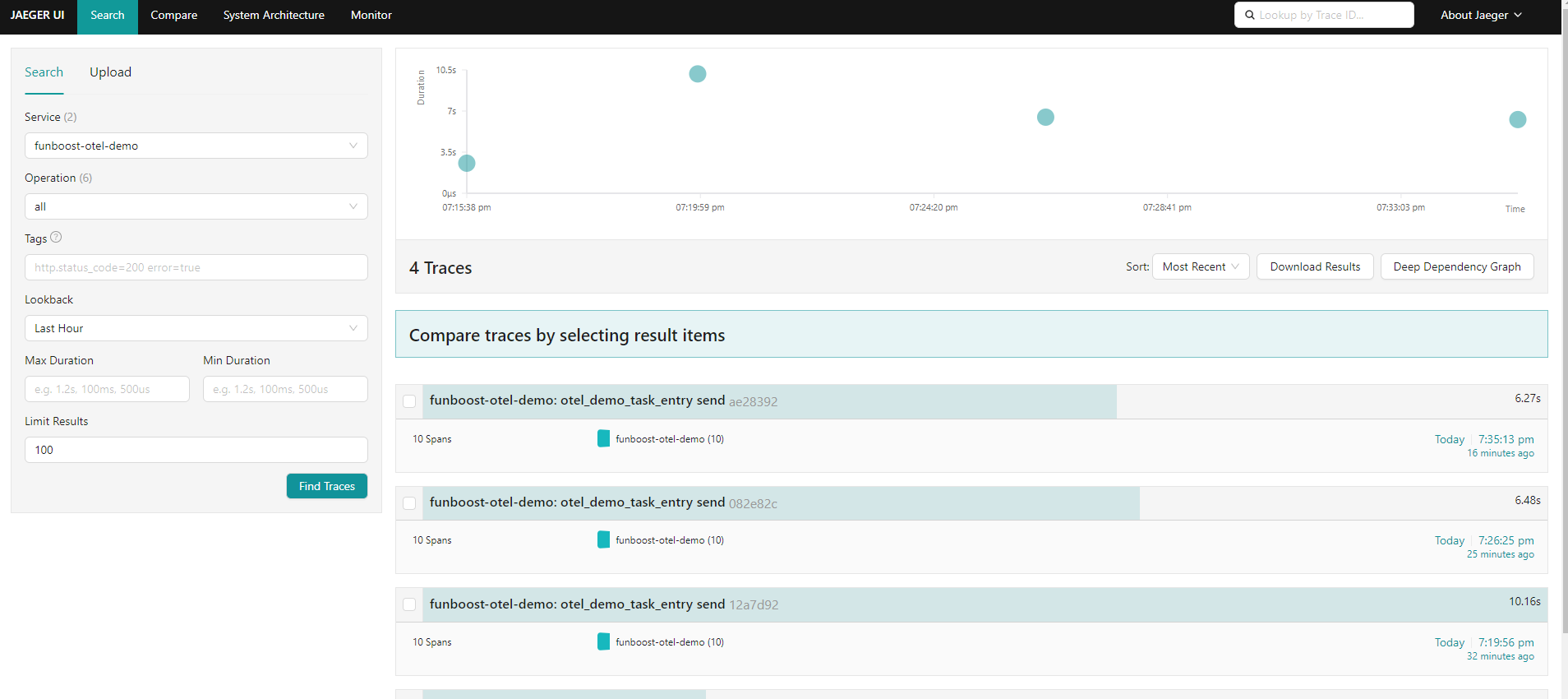
4b.7.1 安装 jaeger ,可视化展示 opentelemetry 的全链路追踪
jaeger 是收集和展示 opentelemetry 的分布式链路追踪的工具之一。你可以用docker 安装 jaeger。 也有很多其他工具,比如 skyWalking 等,因为 opentelemetry 是国际w3c的通用链路追踪规范协议,有无数工具能支持。
docker run -d --name jaeger \
-e COLLECTOR_OTLP_ENABLED=true \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 4317:4317 \
-p 4318:4318 \
-p 14250:14250 \
-p 14268:14268 \
-p 14269:14269 \
-p 9411:9411 \
jaegertracing/all-in-one:latest
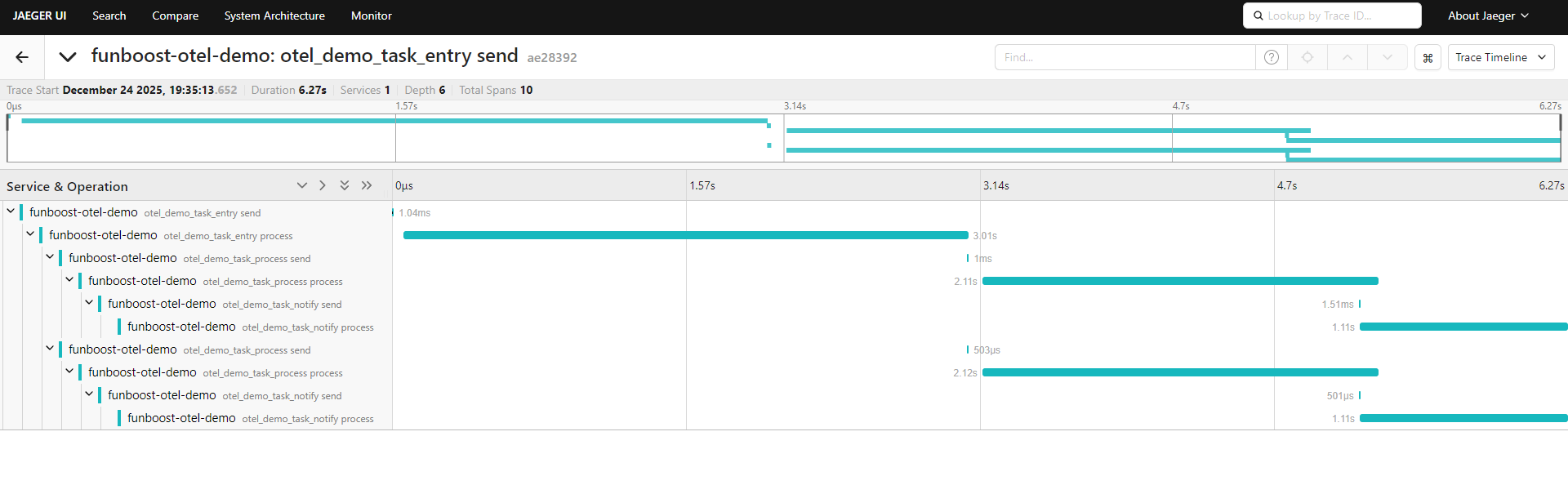
jaeger 分布式全链路追踪系统的截图:
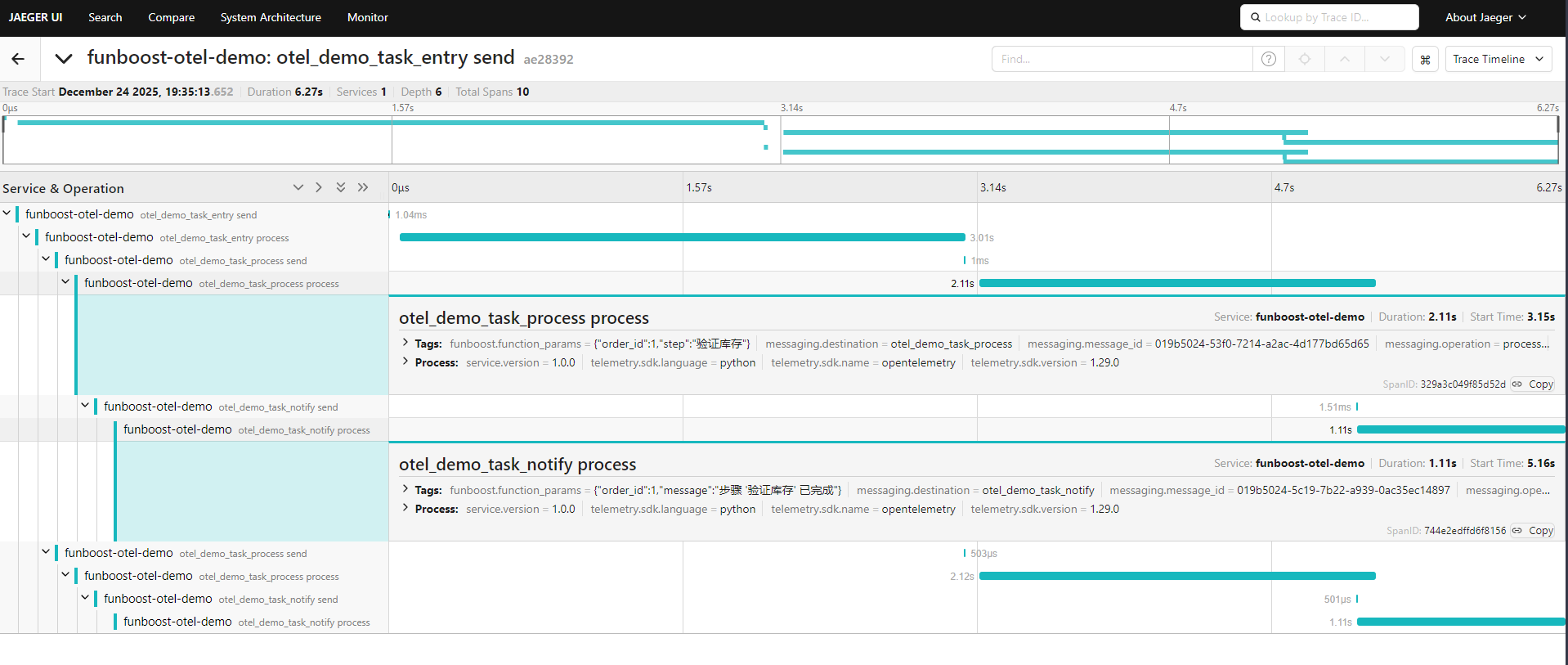
4b.7.2 opentelemetry 全链路任务追踪 和计入 logger日志 + task_id 的排查区别
opentelemetry + jaeger 排查全链路 比 logger + task_id + elk 更直观方便强大。
一句话总结:logger + task_id 是“线性叙事”,是侦探的笔记;而 OpenTelemetry 是“上帝视角”,是战场的全息沙盘。
在 funboost 中,两者并不冲突,而是互补。但在排查复杂分布式问题时,OTel 提供了 降维打击 般的可观测性。
4b.7.2.1. 传统的 Logger + task_id:一维线性的“流水账”
这是大家最熟悉的方式。funboost 的 TaskIdLogger 会自动在每条日志中注入 task_id。
排查方式:你复制一个
task_id,去 ELK 或日志文件中 grep 搜索。看到的景象:你得到的是按时间排序的一堆文本行。
[INFO] 2025-12-29 10:00:01 - task_id: A123 - 函数A 开始运行
[INFO] 2025-12-29 10:00:01 - task_id: A123 - 函数A 计算中...
[INFO] 2025-12-29 10:00:02 - task_id: A123 - 函数A 发布子任务 B (task_id: B456)
[INFO] 2025-12-29 10:00:03 - task_id: B456 - 函数B 开始运行
[INFO] 2025-12-29 10:00:04 - task_id: A123 - 函数A 结束
[INFO] 2025-12-29 10:00:05 - task_id: B456 - 函数B 结束
痛点:
割裂感:如果你不搜索
B456,你根本不知道 A 和 B 有关系。脑补拓扑:你需要在大脑中通过阅读日志,辛苦地构建“A 调用了 B,B 又调用了 C”的调用链。如果调用链很深(A->B->C->D),大脑内存不够用。
时间黑洞:你很难直观看出“A 发布消息”到“B 收到消息”中间的网络延迟和队列排队时间是多少。
4b.7.2.2. OpenTelemetry (OTel):二维/三维的“树状结构”
OTel 不仅记录了“发生了什么”,还记录了“父子关系”和“时间跨度”。
排查方式:在 Jaeger/SkyWalking 界面点击 Trace,或者使用
funboost的TreeSpanExporter在控制台查看。看到的景象:你看到的是一棵树,或者一个甘特图。
📍 Trace ID: f50f...ae2 (整个调用链共用一个 TraceID)
------------------------------------------------------------
└── 📤 A_Queue send (生产者) 10ms
└── 📥 A_Queue process (消费者:函数A) 3000ms
│ (A 的业务逻辑...)
│
├── 📤 B_Queue send (生产者:A发布给B) 5ms
│ └── 📥 B_Queue process (消费者:函数B) 1000ms <-- 自动关联,一目了然
│ └── 📤 C_Queue send ...
│
└── 📤 D_Queue send (生产者:A发布给D) 5ms
└── 📥 D_Queue process (消费者:函数D) 500ms
降维打击的优势:
因果关系 (Causality):不需要搜索,直接看到 A 触发了 B 和 D。
性能瓶颈可视化:一眼就能看到哪根“柱子”最长(耗时最久)。是函数 A 算慢了?还是 Redis 队列积压导致 A 发出后 B 很久才收到?
跨越边界:它能串联起
java/go外部服务->HTTP 请求 (python Web)->Funboost 生产者->RabbitMQ->Funboost 消费者->MySQL的完整链路。
Funboost 的优点之处在于:它同时内置了这两种能力。
TaskIdLogger让你在日志里不迷路。OtelBoosterParams让你拥有上帝视角。
4b.7.3 从opentelemetry功能集成, 侧面证明 funboost 对普通用户扩展性吊打celery10倍。
funboost通过按照教程4.21扩展,在 funboost_otel_mixin.py 中增加AutoOtelPublisherMixin和AutoOtelConsumerMixin实现了对opentelemetry的自动集成。funboost_otel_mixin.py这个文件说明 funboost具有超高的自定义扩展性,他就是基于文档4.21介绍的对普通用户公开的扩展功能,通过consumer_override_cls和publisher_override_cls指定特定的生产者 消费者逻辑。funboost 使用最经典的oop来直观扩展
4b.7.3.1 你如果在celery就没那么简单能自定义实现这个功能了
如果在 Celery 中实现同等级别的全链路追踪,你需要手动“魔改”或者利用复杂的信号机制 (Signals)。
这比 Funboost 的 OOP 继承要繁琐得多。
你需要:
from celery.signals import before_task_publish
from celery.signals import task_prerun, task_postrun, task_failure
把这些加到多个孤立的函数上,而且函数入参签名一定不能乱写,而且毫无ide自动补全功能
你需要对发布端
@before_task_publish.connect
def inject_otel_header(sender=None, headers=None, body=None, **kwargs):
@after_task_publish.connect
def after_task_publish(sender=None, headers=None, body=None, **kwargs):
你需要对消费端
@task_prerun.connect
def start_otel_span(task_id=None, task=None, **kwargs):
@task_postrun.connect
def stop_otel_span(task_id=None, **kwargs):
@task_failure.connect
def handle_failure(task_id=None, exception=None, **kwargs):
。。。。。。。总共要连接12个celery的钩子挂点。因为before和after是破碎的,无法使用 opentelemetry 的 with 语法。
celery这种扩展方式,完全是令人丈二和尚摸不着头脑,你不知道为什么要这样写,也不知道这样写为什么能生效,用户自定义扩展代码和框架代码之间的思维链路是不连贯的。
最痛苦的是:你在 start_otel_span 创建了 span 对象,你必须想办法把它偷渡到 stop_otel_span 函数里去关闭它。你可能需要污染 task 对象实例(task.current_span = span)或者使用不安全的全局变量。而在 Funboost 中,这只是一个局部变量的事情。
4b.7.3.2 funboost的扩展比celery更容易更彻底:
funboost 虽然是函数调度框架,但是他的实现是真oop。
funboost使用经典oop,用户可以完全100%修改定制funboost任何细节,不需要我亲自提前预判预留暴露几百个用户可能需要用到的钩子。
funboost现在很少预留用户级钩子,唯一的就是 boost 装饰器 有个 user_custom_record_process_info_func 钩子,给用户提供记录函数结果状态的,但是这不是必需品,用户完全可以使用4.21介绍的扩展方式,通过consumer_override_cls重写父类的这个user_custom_record_process_info_func 空方法。
即使我不给你预留user_custom_record_process_info_func子类来实现模板方法, 你也可以直接重写父类的_run方法,你的_run 方法里调用 super()._run(kw) 然后使用fct.function_result_status就能记录结果了,这更oop,写法更一致。
funboost 扩展为什么爽,因为你的类重写时候,你可以使用self.xx访问任何属性,通过fct自动上下文你能访问当前任务消息的各种状态和结果。
celery的用户级自定义扩展就很麻烦很高难度了,必须依赖框架自身提前预留暴露了相关钩子或者信号机制,或者信号能连接函数预留的参数还不能满足你(比如 Worker 的某个底层状态),如果你有个奇葩的自定义需求你只能对celery的源码进行修改或者使用猴子补丁来动态替换源码了。
4b.7.3.3 celery 的 opentelemetry 代码在此,太难了:
这个源码证明 celery集成 opentelemetry 难度太大了,一般的普通用户甚至连架构师 思考几天几夜,抓破头皮,完全无法做得到,必须 opentelemetry 和celery官方开发两方人员通力合作攻坚开发,才搞得定,事实就是如此,确实是他们2个团队合作开发的源码,celery还把对opentelemetry的集成写到celery框架近5年的最重大的更新日志记录里面了。
4b.8 funboost 声明式任务编排 workfolw
tips: 用户可以对比 4b.5章节,funboost 使用命令式自由编程实现任务编排(实现canvas功能)
Funboost Workflow - 声明式任务编排
类似 Celery Canvas 的声明式任务编排 API,让工作流定义更简洁直观。
为什么funboost的任务编排要和celery的canvas API相似?
因为声明式任务编排要学习一套新的语法,用户学习成本太高,所以和celery一样,降低难度。
4b.8.1 🚀 快速开始
import time
from funboost import boost, BrokerEnum
from funboost.workflow import chain, group, chord, WorkflowBoosterParams
# 1. 使用 WorkflowBoosterParams 定义任务
@boost(WorkflowBoosterParams(queue_name='download_task',broker_kind=BrokerEnum.REDIS))
def download(url):
time.sleep(1)
return f'/downloads/{url}'
@boost(WorkflowBoosterParams(queue_name='process_task',broker_kind=BrokerEnum.REDIS))
def process(file_path, resolution='360p'):
time.sleep(2)
return f'{file_path}_{resolution}'
@boost(WorkflowBoosterParams(queue_name='notify_task',broker_kind=BrokerEnum.REDIS))
def notify(results, url):
time.sleep(1)
return f'完成: {url} -> {results}'
if __name__ == '__main__':
print('开始执行')
download.consume()
process.consume()
notify.consume()
# 2. 构建工作流(声明式)
workflow = chain(
download.s('video.mp4'),
chord(
group(process.s(resolution=r) for r in ['360p', '720p', '1080p']),
notify.s(url='video.mp4'),
)
)
# 3. 执行
result = workflow.apply()
print('工作流执行结果:', result) # 阻塞等待结果
4b.8.2 📦 核心概念
原语 |
说明 |
用法 |
|---|---|---|
Signature |
任务签名,表示待执行的任务 |
|
Chain |
链式执行,上游结果传给下游 |
|
Group |
并行执行,收集所有结果 |
|
Chord |
并行+汇总,header 并行后结果传给 body |
|
4b.8.3 🔧 API 详解
4b.8.3.1 Signature(任务签名)
# .s() - 创建可变签名(接收上游结果作为第一个参数)
sig = download.s(url)
# .si() - 创建不可变签名(忽略上游结果)
sig = notify.si(msg) # 不会接收 chain 中上游的结果
# | 运算符 - 创建 chain
workflow = download.s(url) | process.s() | notify.s()
4b.8.3.2 Chain(链式执行)
# (x + y) * 2
workflow = chain(
add.s(1, 2), # 返回 3
multiply.s(2) # 接收 3,返回 6
)
result = workflow.apply() # 返回 6
4b.8.3.3 Group(并行执行)
# 并行处理多个任务
g = group(
process.s(1),
process.s(2),
process.s(3)
)
results = g.apply() # 返回 [r1, r2, r3]
# 支持生成器
g = group(process.s(i) for i in range(10))
4b.8.3.4 Chord(并行+汇总)
# header 并行执行,结果列表传给 body
c = chord(
group(fetch.s(url) for url in urls), # 并行抓取
aggregate.s() # 接收 [r1, r2, ...] 汇总
)
result = c.apply()
4b.8.4 ⚙️ WorkflowBoosterParams
预配置的参数类,内置:
is_using_rpc_mode=True- 工作流需要 RPC 获取结果WorkflowPublisherMixin- 注入工作流上下文WorkflowConsumerMixin- 提取工作流上下文
from funboost.workflow import WorkflowBoosterParams
class MyParams(WorkflowBoosterParams):
broker_kind: str = BrokerEnum.REDIS_ACK_ABLE
max_retry_times: int = 3
4b.8.5 🆚 与 Celery Canvas 对比
功能 |
Celery |
Funboost Workflow |
|---|---|---|
链式 |
|
|
并行 |
|
|
汇总 |
|
|
Pipe |
|
|
不可变 |
|
|
优势:
无需学习 Celery 复杂配置
自动拥有
.s()/.si()方法(猴子补丁)与 funboost 其他功能无缝集成
4b.8.6 🆚 与 Funboost 命令式编排对比
Funboost 本身提供命令式编排
见 test_frame/test_funboost_moni_canvas/t_funboost_moni_canvas.py,
使用 RPC 阻塞等待结果。本模块提供声明式编排,两种方式各有优势:
4b.8.6.1 同一个视频处理流程的两种写法
命令式(原生 RPC):
@boost(MyParams(queue_name='canvas_task_queue'))
def canvas_task(url):
# 1. 下载
r1 = download_video.push(url)
file = r1.wait_rpc_data_or_raise(raise_exception=True).result
# 2. 并行转码
r2_list = [transform_video.push(file, resolution=r)
for r in ['360p', '720p', '1080p']]
results = AsyncResult.batch_wait_rpc_data_or_raise(r2_list, raise_exception=True)
video_list = [r.result for r in results]
# 3. 发送通知
r3 = send_finish_msg.push(video_list, url)
return r3.wait_rpc_data_or_raise(raise_exception=True).result
声明式(Workflow):
workflow = chain(
download_video.s(url),
chord(
group(transform_video.s(resolution=r) for r in ['360p', '720p', '1080p']),
send_finish_msg.s(url=url)
)
)
result = workflow.apply()
4b.8.6.2 对比总结
维度 |
命令式 (RPC) |
声明式 (Workflow) |
|---|---|---|
代码量 |
较多 |
更少 ✅ |
可读性 |
逻辑清晰,显式控制 |
结构简洁,一目了然 |
灵活性 |
更高 ✅ 可加 if/else |
固定模式 |
错误处理 |
精细控制每一步 |
统一异常传播 |
调试 |
可分步打断点 |
需要理解执行流程 |
适用场景 |
复杂条件逻辑 |
标准化流水线 |
选择建议:
🔧 复杂逻辑(条件分支、动态决策)→ 用命令式
📋 标准流程(固定步骤、清晰流水线)→ 用声明式
4b.8.7 📁 文件结构
funboost/workflow/
├── __init__.py # 入口 + 猴子补丁
├── signature.py # Signature 类
├── primitives.py # Chain/Group/Chord
├── workflow_mixin.py # Publisher/Consumer Mixin
├── params.py # WorkflowBoosterParams
└── examples/
└── video_pipeline.py # 完整示例
4b.8.8 📖 完整示例
见 examples/video_pipeline.py - 视频处理 Pipeline 演示:
先根据url下载视频,然后并行转码成3个分辨率,最后更新数据库发送通知。
4b.9 funboost 支持 prometheus 指标监控 (高级功能)
funboost自身也支持指标统计和上报
funboost自身内置了 MetricCalculation , 是自己实现的指标统计和上报,并且可以以曲线图的显示在funboost的web界面中。
但是现在 funboost 也同时支持知名的 prometheus 指标监控,以便更好的对接你们自己的grafana运维系统,因为 prometheus 的指标协议 更通用,
4b.9.0 Funboost Prometheus 监控指标 Mixin
提供 Prometheus 指标采集能力,自动上报任务执行状态、耗时等指标。
支持两种模式:
HTTP Server 模式(单进程)— Prometheus 主动拉取
Push Gateway 模式(多进程)— 主动推送到 Pushgateway
4b.9.1 用法1:HTTP Server 模式(单进程)
from funboost import boost
from funboost.contrib.override_publisher_consumer_cls.funboost_promethus_mixin import (
PrometheusBoosterParams,
start_prometheus_http_server
)
# 启动 Prometheus HTTP 服务(默认端口 8000)
start_prometheus_http_server(port=8000)
@boost(PrometheusBoosterParams(queue_name='my_task'))
def my_task(x):
return x * 2
my_task.consume()
4b.9.2 用法2:Push Gateway 模式(多进程推荐)
from funboost import boost
from funboost.contrib.override_publisher_consumer_cls.funboost_promethus_mixin import (
PrometheusPushGatewayBoosterParams,
)
@boost(PrometheusPushGatewayBoosterParams(
queue_name='my_task',
user_options={
'prometheus_pushgateway_url': 'localhost:9091', # Pushgateway 地址
'prometheus_push_interval': 10.0, # 推送间隔(秒)
'prometheus_job_name': 'my_app', # Prometheus job 名称
}
))
def my_task(x):
return x * 2
my_task.consume()
4b.9.3 指标说明
funboost_task_total: 任务计数 (labels: queue, status)
funboost_task_latency_seconds: 任务耗时直方图 (labels: queue)
funboost_task_retries_total: 重试次数计数 (labels: queue)
funboost_queue_msg_count: 队列剩余消息数量 (labels: queue)
funboost_publish_total: 发布消息计数 (labels: queue)
4b.10 funboost支持微批消费
微批的核心是:生产者是单个单个地提交任务,但是消费者自动将多个任务聚合起来,一次性消费。
微批消费者实现累积 N 条消息后批量处理的功能,适用于批量写入数据库、批量调用 API 等场景。
缓冲区累积: 重写
_submit_task方法,将消息累积到缓冲区触发条件: 达到
batch_size条消息或超过timeout秒后触发批量处理批量 ack/requeue: 成功则批量确认,失败则批量重回队列
函数签名: 消费函数的入参从单个对象变为
list[dict]
4b.10.1 funboost 微批消费用法
代码位置:
funboost/contrib/override_publisher_consumer_cls/funboost_micro_batch_mixin.py使用demo:
test_frame/test_micro_batch
# -*- coding: utf-8 -*-
# @Author : AI Assistan
"""
微批消费者测试
测试 MicroBatchConsumerMixin 的功能:
1. 基本功能测试:发布消息,验证批量处理
2. 超时触发测试:不足 batch_size 时超时触发
例如可以批量100条插入数据库,做数据库表同步性能好。
"""
from funboost import boost, BrokerEnum,ctrl_c_recv
from funboost.contrib.override_publisher_consumer_cls.funboost_micro_batch_mixin import (
MicroBatchConsumerMixin,MicroBatchBoosterParams
)
@boost(MicroBatchBoosterParams(
queue_name='test_micro_batch_queue',
broker_kind=BrokerEnum.MEMORY_QUEUE,
user_options={
'micro_batch_size': 10, # 每批10条强制触发用户函数
'micro_batch_timeout': 3.0, # 如果不足n条,3秒超时强制触发用户函数
},
))
def batch_insert_task(items: list):
"""
模拟批量插入任务
:param items: 消息列表,每个元素是一个字典(函数参数)
items是例如 [{'x': 10, 'y': 20}, {'x': 11, 'y': 22}, {'x': 12, 'y': 24}, ...]
"""
print(f"✅ 批量处理 {len(items)} 条消息: {items}")
return len(items)
if __name__ == '__main__':
# 运行基本测试
# 启动消费
batch_insert_task.consume() # 消费是自动微批操作
print("发布 25 条消息,batch_size=10,预期触发 2 次完整批次 + 1 次超时批次")
print("=" * 60)
# 发布 25 条消息, 之所以是25条,是为了让 21 - 25条消息触发 micro_batch_timeout 这个条件
for i in range(25):
batch_insert_task.push(x=i, y=i * 2) # 发布还是按照单条消息发布,消费是自动微批操作
print(f"发布消息: x={i}, y={i * 2}")
ctrl_c_recv()
4b.10.2 如果每次临时手写微批操作,会怎么样?
如果不使用funboost,用户每次临时自己手写微批操作,需要考虑缓冲聚合、超时检测、线程安全等问题。
如果写得不好会出现:
最尾部没被批量条数n整除的数据丢失
无超时机制
线程不安全
就算写得好,每次也要临时罗里吧嗦写一大堆代码,为了一个微批功能,最起码要写80行代码, 因为微批消费为了超时强制触发,100%需要有一个独立的后台检查机制(通常是单独的线程,或者异步协程)。
4b.12 funboost的周期额度功能
什么是周期额度
功能:在指定周期内限制执行次数,周期结束后配额自动重置。这个超越了celery 的 rate_limit 概念。
例如假设chatgpt允许你每天使用24次,不代表你每使用一次然后需要间隔1小时才能再次使用chatgpt,
你可以一口气把一天额度快速的用完,然后当天或24小时内不用chatgpt就好了,所以周期额度和运行频率是两码事,
周期额度不代表你要把额度次数除以周期时长,然后匀速执行频率。
如果每次使用chtgpt要等1个小时,你愿意刚好掐点每隔1小时去用一次chatgpt吗,太抓狂了这样;
肯定是能自由随意啥时候用完24次这种更爽,不用一直看手表掐点。
例如csdn每天能允许你评论24次,不代表你评论了一条内容后,要再等1小时才能评论下一条,这样太耽误及时回复了。
周期额度功能可以和qps参数结合起来使用,一个控制间隔频率,一个控制周期额度。
funboost的周期额度完虐 celery的rate_limit概念
celery的 rate_limit 被 funboost的周期额度功能完虐,
celery的 rate_limit = '24/d',每次运行消息需要间隔1小时,这不是有些场景下想要的。
celery的 rate_limit = '6/m' 代表每分钟运行6次,每次运行间隔10s
这等同于funboost的 qps = 6/60,也就是qps=0.1,每10秒运行一次
而funboost的周期额度 每分钟执行6次,用法是:
consumer_override_cls=PeriodicQuotaConsumerMixin,
user_options={
'quota_limit': 6, # 每周期最多6次
'quota_period': 'm', # 周期为分钟
'sliding_window': True, # 滑动窗口(默认,可省略);如果是固定窗口,那么是从整点开始计算次数
},
funboost这个周期额度不是强迫每隔10秒执行一次,而是一分钟内任意时间都可以用完6次额度。
4b.12.2 周期额度用法例子
from funboost import boost, BoosterParams, BrokerEnum
from funboost.contrib.override_publisher_consumer_cls.periodic_quota_mixin import PeriodicQuotaConsumerMixin
# 滑动窗口模式(默认):每秒1次,每分钟最多6次
@boost(BoosterParams(
queue_name='minute_quota_queue',
broker_kind=BrokerEnum.REDIS,
consumer_override_cls=PeriodicQuotaConsumerMixin,
user_options={
'quota_limit': 6, # 每周期最多6次
'quota_period': 'm', # 周期为分钟 (s/m/h/d)
'sliding_window': True, # 滑动窗口(默认,可省略);如果是固定窗口,那么是从整点开始计算次数
},
qps=1, # 每秒执行1次(间隔控制) # 周期额度可以和qps一起使用
))
def my_task(x):
print(f'Processing {x}')
4b.13 使用内存队列 broker_kind=BrokerEnum.MEMORY_QUEUE 时候,用 get_future 获取消费函数的运行结果
funboost 发布消息后,获取函数结果,专业术语叫做rpc。
funboost的rpc原理是无论使用何种消息队列作为broker,统一都使用redis作为rpc的载体。
考虑到内存模式在funboost中是最重要的sss级中间件,但为了要高性能获取函数结果,并为了支持获取不可pickle序列化的函数结果,
funboost单独对内存队列的 publisher 增加了 get_future 方法,返回一个 concurrent.futures.Future 对象
funboost单独对内存队列的 publisher 增加了 get_aio_future 方法,返回一个 asyncio.Future 对象
import time
import asyncio
import concurrent.futures
from funboost import boost, BoosterParams, BrokerEnum, ConcurrentModeEnum
@boost(BoosterParams(
queue_name="simple_demo_queue",
broker_kind=BrokerEnum.MEMORY_QUEUE,
qps=2,
concurrent_num=10
))
def simple_task(x, y):
print(f'计算: {x} + {y} = {x + y}')
time.sleep(1)
return x + y
@boost(BoosterParams(
queue_name="async_demo_queue",
broker_kind=BrokerEnum.MEMORY_QUEUE,
qps=2,
concurrent_mode=ConcurrentModeEnum.ASYNC,
concurrent_num=10
))
async def async_task(x, y):
print(f'异步计算: {x} + {y} = {x + y}')
await asyncio.sleep(1)
return x + y
def sync_rpc_demo():
print('--- 同步模式:使用 get_future 获取结果(不依赖 Redis) ---')
for i in range(3):
future: concurrent.futures.Future = simple_task.publisher.get_future(i, i * 2)
result_status = future.result(timeout=10)
print(f'任务 {i} 的结果: {result_status.result}, 成功: {result_status.success}')
async def async_rpc_demo():
print('\n--- 异步模式:并发发布并等待多个任务结果(不依赖 Redis) ---')
print('并发发布 3 个任务...')
futures: list[asyncio.Future] = []
for i in range(3, 6):
future: asyncio.Future = async_task.publisher.get_aio_future(i, i * 2)
futures.append(future)
print('并发等待 3 个任务的结果...')
for i, future in enumerate(futures, start=3):
result_status = await future
print(f'任务 {i} 的结果: {result_status.result}, 成功: {result_status.success}')
if __name__ == '__main__':
simple_task.consume()
async_task.consume()
sync_rpc_demo()
asyncio.run(async_rpc_demo())
print('\n--- 演示发布任务(不等待结果) ---')
for i in range(6, 10):
simple_task.push(i, i * 2)
time.sleep(5)
print('演示完成')
4b.14 funboost 支持自动熔断,智能自动熔断、半开、恢复 (高级功能)
Funboost 的熔断器的实现遵循了业界顶流熔断器框架的规范:
遵循业界通用三态状态机模型(Closed / Open / Half-Open)
支持两种触发策略(错误率阈值、连续错误数阈值)
提供完善的配置项和扩展钩子
额外支持分布式计数,非常适合构建高可用的分布式系统
配置方式清晰直观,开发者可以像使用 Hystrix 或 resilience4j 一样轻松驾驭它
4b.14.0 funboost 支持自动熔断管理和手动熔断管理
funboost 支持自动熔断管理和手动熔断管理两种方式:
4b.14.0.1 手动熔断管理
由开发者人工判断并手动操作暂停/恢复消费,适用于以下场景:
主动发现大规模报错
通过 Prometheus 告警发现异常
操作方式:
方式 |
操作说明 |
|---|---|
Redis 标志 |
对 |
FaaS 接口 |
调用 |
Web 管理界面 |
通过 Funboost Web Manager 网页操作 |
4b.14.0.2 自动熔断管理
通过 CircuitBreakerConsumerMixin 实现,智能自动进入三种状态:
CLOSED(正常)
OPEN(熔断)
HALF_OPEN(半开试探)
4b.14.1 funboost 自动熔断,CircuitBreakerConsumerMixin
自动熔断降级是属于生产环境服务的高可用的功能。
三态状态机:CLOSED(正常)→ OPEN(熔断)→ HALF_OPEN(半开试探)→ CLOSED 或回退到 OPEN。
实现源码在 funboost/contrib/override_publisher_consumer_cls/circuit_breaker_mixin.py
使用方式,在装饰器设置 consumer_override_cls=CircuitBreakerConsumerMixin ,然后在 user_options 中设置合理的值。
功能说明:当消费函数失败达到阈值时自动熔断,熔断期间阻塞等待恢复或执行 fallback 降级函数。
4b.14.1.1 三态状态机
┌─────────┐ 触发条件满足 ┌─────────┐
│ CLOSED │ ───────────────→ │ OPEN │
│ (正常) │ │ (熔断) │
└─────────┘ └────┬────┘
↑ │
│ recovery_timeout 秒 │
└────────────────────────────┘
↓
┌─────────────┐
│ HALF_OPEN │
│ (半开/试探) │
└──────┬──────┘
│
┌──────────────────────┼──────────────────────┐
│ │ │
连续成功 >= 任意一次失败 超过 half_open_ttl
half_open_max_calls │ │
│ │ │
↓ ↓ ↓
┌─────────┐ ┌─────────┐ ┌─────────┐
│ CLOSED │ │ OPEN │ │ OPEN │
└─────────┘ └─────────┘ └─────────┘
状态流转说明:
流转路径 |
触发条件 |
|---|---|
|
触发策略条件满足(连续失败或错误率超标) |
|
经过 |
|
连续成功次数 >= |
|
任意一次失败 或 超过 |
4b.14.1.2 两种触发策略
策略 |
说明 |
适用场景 |
|---|---|---|
|
连续失败 >= |
对偶发错误敏感,希望快速熔断 |
|
在 |
需要基于错误率统计,避免误伤 |
4b.14.1.3 两种计数后端
后端 |
说明 |
适用场景 |
|---|---|---|
|
单进程内有效,使用 |
单机部署 |
|
多进程/多机器共享熔断状态,同一队列的所有消费者共享计数 |
分布式部署 |
4b.14.1.4 两种熔断行为
模式 |
说明 |
配置方式 |
|---|---|---|
阻塞模式(默认) |
熔断期间阻塞 |
|
Fallback 模式 |
熔断期间用 fallback 函数替代原函数执行 |
指定 |
4b.14.1.5 user_options的 circuit_breaker_options 参数说明
策略相关:
参数 |
类型 |
默认值 |
说明 |
|---|---|---|---|
|
str |
|
触发策略: |
|
str |
|
计数后端: |
consecutive 策略参数:
参数 |
类型 |
默认值 |
说明 |
|---|---|---|---|
|
int |
|
连续失败次数阈值 |
rate 策略参数:
参数 |
类型 |
默认值 |
说明 |
|---|---|---|---|
|
float |
|
错误率阈值(0.0~1.0) |
|
float |
|
统计窗口秒数 |
|
int |
|
窗口内最少调用数才评估 |
状态机参数:
参数 |
类型 |
默认值 |
说明 |
|---|---|---|---|
|
float |
|
熔断后等待恢复秒数 |
|
int |
|
半开状态需连续成功次数 |
|
float / None |
|
半开状态超时秒数,超时后重新进入 OPEN |
其他参数:
参数 |
类型 |
默认值 |
说明 |
|---|---|---|---|
|
tuple / None |
|
要跟踪的异常类型元组, |
|
callable / None |
|
降级函数, |
4b.14.1.6 钩子方法(子类重写),用于你发送告警到 微信/钉钉/飞书/邮件等等
方法 |
触发时机 |
用途 |
|---|---|---|
|
熔断触发时 |
可发送微信/钉钉/邮件告警 |
|
熔断恢复时 |
可发送微信/钉钉/邮件恢复通知 |
4b.14.1.7 用法示例
from funboost import boost, BoosterParams, BrokerEnum
from funboost.contrib.override_publisher_consumer_cls.circuit_breaker_mixin import (
CircuitBreakerConsumerMixin,
CircuitBreakerBoosterParams,
)
# ========================================
# 方式1:连续失败策略 + 本地计数(最简用法)
# ========================================
@boost(CircuitBreakerBoosterParams(
queue_name='my_task',
broker_kind=BrokerEnum.REDIS,
user_options={
'circuit_breaker_options': {
'failure_threshold': 5, # 连续失败5次触发熔断
'recovery_timeout': 60, # 熔断后等待60秒恢复
}
},
))
def my_task(x):
return call_external_api(x)
# ========================================
# 方式2:错误率策略 + Redis 分布式计数
# ========================================
@boost(BoosterParams(
queue_name='my_task_rate',
broker_kind=BrokerEnum.REDIS,
consumer_override_cls=CircuitBreakerConsumerMixin,
user_options={
'circuit_breaker_options': {
'strategy': 'rate', # 使用错误率策略
'counter_backend': 'redis', # Redis分布式计数
'errors_rate': 0.5, # 错误率阈值50%
'period': 60, # 统计窗口60秒
'min_calls': 10, # 最少调用10次才评估
'recovery_timeout': 30, # 熔断后等待30秒恢复
'exceptions': (ConnectionError, TimeoutError), # 只跟踪这些异常
}
},
))
def my_task_rate(x):
return call_external_api(x)
# ========================================
# 方式3:Fallback 降级模式
# ========================================
def my_fallback(x):
"""熔断期间的降级函数"""
return {'status': 'degraded', 'x': x}
@boost(BoosterParams(
queue_name='my_task_fb',
broker_kind=BrokerEnum.REDIS,
consumer_override_cls=CircuitBreakerConsumerMixin,
user_options={
'circuit_breaker_options': {
'failure_threshold': 3, # 连续失败3次触发熔断
'recovery_timeout': 30, # 熔断后等待30秒恢复
'circuit_breaker_fallback': my_fallback, # 指定降级函数
}
},
))
def my_task_fb(x):
return call_external_api(x)
4b.15 funboost 配置失败告警的多种方式
见文档 6.30 章节
## 6.30 funboost 如何实配置触发失败告警和恢复告警
funboost 提供了多种灵活的失败告警方式,满足从业务级即时通知到运维级聚合监控的不同需求。以下介绍5种常用方案。
好的,我已根据最新的类名 MemoryFunboostPool 和 FunboostPool 重写了 4b.16 章节。内容严格锚定在您提供的源码上,并修正了类名、继承关系和参数说明。