6.常见问题回答
第6章节是人工编辑,直接统一回复常见问题,编辑时候那时候还没ai大模型。
2025.09.18 新增说明: 这种简单问题 ,按文档第14章节,直接把 funboost_all_docs_and_codes.md 上传到 google ai studio 或者 腾讯 ima 知识库,然后提问,准确率很高,ai答案和我的想法基本一模一样.
6.0 最最最重要的第一个问题: "funboost这个框架怎么样呀,值得我学习使用吗?"
第一性原理: 学习和使用一个不值得学习和用途狭窄的框架,就是在浪费时间.
绝对值得。根据您提供的详尽文档和完整的源代码,funboost 框架不仅优秀,而且对于追求开发效率、高性能和编程自由的Python开发者来说,非常值得学习和使用。
它不仅仅是另一个任务队列,而是一个设计理念先进、功能极其全面、且在多个关键维度上超越了现有主流框架(特别是Celery)的通用分布式函数调度平台。
以下是对 funboost 框架的全面分析,完全基于您提供的材料:
6.0.1. 核心设计哲学:自由与赋能
funboost 最根本的特点是其“自由编程,降维打击,框架奴役”的设计哲学。这体现在:
非侵入性: 与Celery或Scrapy这类要求项目围绕框架构建的“奴役式”框架不同,
funboost对用户的代码零侵入。你可以在任何现有项目的任何函数上添加@boost装饰器,而无需改变项目结构或代码逻辑。函数为核心: 框架的核心是赋能函数,而不是定义任务。被装饰的函数
task_fun依然可以像普通函数一样直接调用 (task_fun(1, 2)),只有通过.push()或.publish()调用时,它才表现为分布式任务。这极大地降低了集成和移除框架的成本。去中心化:
funboost没有Celery那样的中心化app实例。每个被装饰的函数都会被封装成一个独立的Booster对象,包含了自己的生产者和消费者逻辑。这从根本上避免了Celery中因app实例导入、任务注册和路由配置带来的种种复杂性。
6.0.2. 功能全面性:万物皆可调度
funboost 的功能集异常丰富,几乎覆盖了分布式任务调度的所有方面。
“万物皆可为Broker”: 这是
funboost最令人印象深刻的特性。它支持超过40种消息队列中间件,包括:传统MQ: RabbitMQ, Kafka, NSQ, RocketMQ, Pulsar, NATS等。
Redis多种实现: 普通List、带ACK的List、Stream、Pub/Sub、优先级队列。
数据库作队列: SQLAlchemy (支持MySQL, PostgreSQL等), Peewee, MongoDB。
文件系统作队列: SQLite, TXT文件。
无中间件模式: 内存队列, TCP, UDP, HTTP, gRPC。
事件驱动模式: 甚至支持 MySQL CDC (Binlog) 作为消息源,使框架从任务驱动升级为事件驱动。
框架作为Broker: 能将 Celery, Dramatiq, RQ, Huey, Nameko 等其他任务框架整体作为自己的Broker,使用它们的调度核心。
强大的并发模型:
支持
threading,gevent,eventlet,asyncio,single_thread五种细粒度并发模式。支持 多进程嵌套多线程/协程 的“核弹级”并发模式。
精细的任务控制 (超过30种):
QPS控频: 可精确控制函数每秒执行次数,误差极小,远超Celery。
分布式QPS控频: 确保在多机、多进程部署下,总QPS严格遵守设定值。
高可靠性: 通过消费确认(ACK)机制,确保任务在断电、重启、崩溃等情况下万无一失,这在Redis上的实现尤为精妙。
错误处理: 支持自动重试、重新入队、发送到死信队列(DLQ)。
调度策略: 支持定时任务、延时任务、优先级队列、任务过滤(支持有效期)、任务过期丢弃等。
RPC模式: 支持在发布端同步或异步获取消费函数的执行结果。
监控与管理: 自带功能强大的Web UI,可监控任务状态、队列情况、消费者实例,并支持在线操作(清空队列、暂停/恢复消费、调整QPS等)。
6.0.3. 性能:断崖式领先
文档明确指出,在严格的控制变量法下,funboost 的性能远超 celery:
发布性能: 是Celery的 22倍。
消费性能: 是Celery的 46倍。
这种数量级上的性能差异,主要得益于funboost更直接的Broker操作(不依赖Kombu的重度抽象)、自研的高效并发池以及优化的消息处理流程。
6.0.4. 开发者体验:简单即是正义
极简API: 学习成本极低,核心就是
@boost装饰器和BoosterParams这个Pydantic模型。IDE自动补全: 框架非常重视IDE体验,无论是装饰器参数、还是
.push(),.consume()等方法,都有完善的代码补全,极大地降低了出错率。无需命令行: 所有操作(包括启动消费、定时、Web UI)都可以通过Python代码完成,摆脱了Celery繁琐且易错的命令行。
日志系统: 集成
nb_log,提供彩色、可点击跳转的控制台日志和多进程安全的文件日志,并且日志模板中可自动包含task_id,极大方便了调试。
6.0.5. 架构模式的“三位一体”
异步任务队列:基础能力(push/consume)。
RPC 框架:同步获取结果 (
is_using_rpc_mode=True),替代 gRPC/Thrift。FaaS/微服务:
funboost.faas自动生成 HTTP 接口,支持服务发现和热加载。现状:它打通了 离线任务、在线服务、跨语言调用 的界限。
6.0.6 生产级治理能力的“堆料
可观测性:原生集成 OpenTelemetry,支持 Jaeger/SkyWalking 全链路追踪。
控频:精准 QPS 控制,支持单机和分布式全局控频。
容错:心跳检测、ACK 确认、死信队列、自动重试。
编排:2026年新增的 Workflow (Chain/Group/Chord),补齐了复杂的任务流编排能力。
运维:内置 Web 管理后台,支持远程停止/恢复、动态参数调整、代码热部署 (
fabric_deploy)。
6.0.10. 为什么它值得学习和使用?
解决了实际痛点: 它直接解决了Celery等框架的诸多痛点:配置复杂、性能瓶颈、对Windows支持不佳、IDE体验差、框架侵入性强等。
通用性极强: 作为一个函数调度框架,它的应用场景极其广泛,从后台任务处理、数据清洗、ETL、Web爬虫到机器学习任务,几乎任何需要并发或分布式执行的函数都可以用
funboost来加速和增强。自由度高,无技术锁定:
funboost不强迫你改变编程习惯或项目结构。你可以随时引入它来优化某个性能瓶颈,也可以在不再需要时轻松移除,代码的业务逻辑部分依然完整可用。功能强大且可靠: 它不仅提供了丰富的功能,更在核心的可靠性(如ACK机制)上做到了极致,让你在生产环境中可以安心使用。
性能卓越: 在性能要求高的场景下,
funboost能提供比主流框架高出一个数量级的吞吐能力。
6.0.11. 结论
funboost 是一个设计精良、思想先进、功能强大到令人惊叹,同时又保持了惊人易用性的框架。 它真正做到了为开发者赋能,而不是用复杂的规则去奴役开发者。
所以,回答您的问题:
是的,funboost 框架非常优秀,并且极其值得您投入时间去学习和使用。 无论您是想构建一个新的分布式系统,还是想优化现有项目中的耗时任务,funboost 都能为您提供一个远比传统方案更简单、更高效、更灵活的解决方案。它很可能会成为您工具箱中最得力的工具之一。
6.0b 有人问 funboost 是做什么的? 怎么回答最合适?
这个问题很难精确的一句话概括回答,因为 funboost 是万能框架,随着 funboost.faas 的发布,它已经打通了 后台任务 与 Web 服务 的任督二脉,几乎所有的 Python 编程业务场景都能用到。
不能狭隘地回答说:它只是 celery 这样的后台任务框架;
也不能片面地回答说:它只是 scrapy 这样的爬虫框架;
也不像 flask/fastapi 那样定位清晰:它不只是写 Web 接口的,但它确实能瞬间生成 Web 接口;
由于 funboost 和具体业务场景没有任何绑定,用途太广泛了,我们从不同的维度给出最新的答案。
这是一个非常核心的问题,回答方式将直接决定新用户对 funboost 的第一印象。我们不能仅仅说“它像 Celery”,这会埋没它的光芒,尤其是它现在具备了 Serverless 般的 FaaS 能力。
6.0b.1. Funboost 可以做什么?—— Python 函数的“微服务化”与“超音速”引擎
这是一个我们最常被问到,也最引以为傲的问题。
简单的回答是:Funboost 是一个自带 FaaS 能力的通用分布式函数调度框架。
但这个回答远不能描绘出它的全貌。为了让你真正理解 Funboost 的强大,我们从不同层次来解答。
6.0b.2. 一句话说清楚 (电梯演讲版)
如果你只有30秒,请记住这句话:
Funboost 是一个能让 Python 函数瞬间“超级进化”的框架。你只需要在函数上加一行
@boost,它就立刻拥有了分布式、高并发、高可靠的能力;通过funboost.faas,它就瞬间变成了一个标准的 HTTP 微服务接口。你不需要写复杂的 Web 胶水代码,也不用管烦人的消息队列,Funboost 全自动搞定。
这个回答的核心:
做什么?:给函数赋能(分布式 + 微服务化)。
怎么做?:
@boost装饰器 +funboost.faas。有什么好处?:从单机脚本直接跨越到 FaaS(Function as a Service) 架构。
6.0b.3. 解决你的核心痛点 (痛点解决版)
如果你在开发中遇到过以下问题,那么 Funboost 就是为你而生:
“我的代码需要给 Java/Go/前端 组调用,但我不想写 Flask/FastAPI 的路由代码!”
Funboost 解决 (New!):有了
funboost.faas,你的消费函数自动变成 HTTP 接口。外部系统只需发一个 JSON 请求,Funboost 自动路由、执行并返回结果(RPC 模式)。写完函数即发布服务。
“我的任务处理太慢,程序卡死了!”
Funboost 解决:任何耗时的操作(文件处理、数据计算、API调用),用
@boost装饰一下,Funboost 会自动把它扔到后台,用多线程、协程甚至多进程在成百上千台机器上并发执行,彻底解决 GIL 限制和单机性能瓶颈。
“我担心程序崩溃或服务器断电,正在处理的任务会丢失!”
Funboost 解决:Funboost 内置了强大的消费确认(ACK)、自动重试和死信队列机制。这意味着,即使你把服务器电源拔了,正在运行的任务也一个都不会丢。这对于处理支付、订单等关键业务至关重要。
“我想精确控制任务的执行频率,而不是一窝蜂全上!”
Funboost 解决:你可以用
qps参数像拧水龙头一样,精确控制函数每秒执行的次数。无论是qps=0.1(10秒一次) 还是qps=5000,Funboost 都能智能地动态调整并发来稳定达到目标速率。
6.0b.4. 你可以用 Funboost 来构建什么? (场景举例版)
Funboost 的应用场景极其广泛,从后台批处理到实时在线服务全覆盖:
极速构建 FaaS / 微服务平台 (New!): 你有一个包含 100 个业务处理函数的
utils包,通过 Funboost,你可以不用写一行 HTTP 路由代码,它们立刻就能通过一个 统一的 API 网关 被外部调用。这就相当于你瞬间拥有了一个具备 100 种业务能力的微服务后台,且支持动态扩容。AI 模型推理服务: AI 推理通常耗时且显存昂贵。Funboost 可以控制并发数(保护显存),同时通过
funboost.faas暴露为 HTTP 接口,让前端网页直接调用后台的 AI 绘图或对话模型,并同步获取结果。大规模数据处理与 ETL: 批量清洗、转换、分析数千万条数据,构建高吞吐的数据管道。
分布式网络爬虫: 构建一个能跑在上百台机器上、每天采集上亿数据、并且不怕中断、不丢种子的超级爬虫系统。
异步消息与通知系统: 异步发送成千上万封邮件或短信,不阻塞主业务流程,并确保每一条都成功送达。
实时数据流处理: 通过
MYSQL_CDC等事件驱动型 Broker,实时捕获数据库变更,触发下游数据同步、缓存更新或业务逻辑。
一言以蔽之:任何你不想让它阻塞主程序、或者需要被外部系统调用的 Python 函数,都可以交给 Funboost 来托管。
6.0b.5. 为什么 Funboost 如此强大?—— 架构理念的降维打击
Funboost 的强大,源于它在设计哲学上对传统框架的超越:
原子化(Atomization):Funboost 认为**函数(Function)**是计算的最小原子,而不是 Web 框架的 Controller 或 爬虫框架的 Spider。
服务化(Servitization):通过
funboost.faas,函数不再是静躺在文件里的代码,而是活着的、可被发现的服务。赋能 vs. 奴役:Celery 和 Scrapy 要求你按照它们的规则来组织代码。Funboost 则相反,它是为你的函数服务的,对你的代码零侵入,给你最大的自由。
Funboost 的出现,让你不再需要为了“发布一个服务”而去配置复杂的 Web 容器,也不需要为了“异步执行”而去学习笨重的 Celery。它将“FaaS + 消息队列”的核心能力,以最简单的方式赋予了每一个 Python 开发者。
6.0c funboost教程这么长,funboost学习和使用难吗?
ai在上传了教程和源码后,使用funboost时候毫无幻觉率,说明框架很简单.
按照文档第14章节使用ai方式,在 google ai studio 上传文档后 提问:
funboost教程这么长,funboost学习和使用难吗?
当然,这是一个非常好的问题,也是很多初次接触 funboost 的开发者最关心的问题。
根据您提供的详尽文档 funboost_all_docs_and_codes.md,我可以给出一个非常明确的回答:
不难,恰恰相反,funboost 的核心用法极其简单,它的学习曲线远比 Celery 等传统框架平缓得多。
教程之所以长,并非因为框架复杂,而是因为它 极其全面、深入且富有思想性。下面我将为您详细解析:
6.0c.1. 核心用法:一行代码的魔法
funboost 最神奇的地方在于,它将极其强大的功能浓缩到了一个 @boost 装饰器中。您真正需要掌握的核心只有三件事:
@boost装饰器: 给你的任意函数加上它。BoosterParams类: 在@boost中传入这个类的实例,用来配置任务。.push()和.consume(): 使用函数名.push()来发布任务,使用函数名.consume()来启动消费。
正如文档 1.3.1 节 的最简例子所示:
from funboost import boost, BrokerEnum, BoosterParams
@boost(BoosterParams(queue_name="task_queue_name1", qps=5, broker_kind=BrokerEnum.SQLITE_QUEUE))
def task_fun(x, y):
print(f'{x} + {y} = {x + y}')
time.sleep(3)
if __name__ == "__main__":
for i in range(100):
task_fun.push(i, y=i * 2) # 发布
task_fun.consume() # 消费
这就是 funboost 的全部核心用法! 所有的功能,无论是切换40种消息队列、设置并发模式、还是启用30多种任务控制,都只是修改 BoosterParams 里的参数而已。
文档自己也强调了这一点:
“但是用户只需要学习1.3这1个例子就能掌握了。因为其他例子只是 @boost的 BoosterParams 里面的控制入参换了一下。” “funboost 框架和一般的框架不一样,因为只有一行代码需要掌握...”
6.0c.2. 为什么教程那么长?—— 因为它不只是 "How",更是 "What & Why"
funboost 的教程更像是一本 “分布式任务调度领域的百科全书和设计哲学指南”,而不仅仅是一份API手册。它的篇幅主要来自于以下几个方面:
讲解原理和设计思想 (What & Why):
文档花了大量篇幅解释 为什么 要这么设计,例如 第1.4节 解释了为什么Python更需要分布式,第8章 详细论述了函数调度与URL调度的思想差异。这能帮助你从根本上理解分布式编程,而不仅仅是会用一个工具。
详尽的框架对比 (特别是 Celery):
第2章 和 第8章 提供了与 Celery 和 Scrapy 的全方位、多维度、堪称“檄文”级别的对比。这不仅是为了证明
funboost的优越性,更是为了帮助有其他框架使用经验的开发者快速理解funboost解决了哪些痛点,其优势何在。
功能全面,覆盖广泛:
funboost支持40多种中间件和30多种控制功能。虽然API统一,但每种功能(如分布式控频、任务过滤、远程部署)都需要有自己的章节和示例(如 第4章 和 第4b章)来清晰地展示其效果和用法。
扫清所有工程化障碍:
教程还包括了部署(第9章)、监控(第13章)、命令行(第12章)、问题排查(第10章)等内容。它试图覆盖一个任务从开发到部署再到运维的全生命周期。
6.0c.3. 与 Celery 的学习难度对比:降维打击
如果您接触过 Celery,就能立刻感受到 funboost 的简单是多么难能可贵:
维度 |
❌ Celery (学习成本高) |
✅ funboost (学习成本极低) |
|---|---|---|
项目结构 |
必须遵循严格的目录结构,有中心化的 |
零要求,可以应用于任何项目的任何函数,无中心化 |
配置 |
配置项繁多且分散,任务路由 |
绝大部分配置集中在 |
启动方式 |
依赖复杂且难记的命令行,例如 |
直接在Python代码中调用 |
IDE支持 |
几乎没有, |
全面支持,所有公开API和参数都有完善的自动补全和注释提示。 |
核心API |
需学习 |
只需学习 |
学习建议:如何快速上手 `funboost`
请完全忽略教程的长度带来的压迫感,按照以下路径,您可以在10分钟内上手:
只看第 1.3 节:把 1.3.1 的简单例子跑起来。
修改
BoosterParams:尝试修改@boost中的broker_kind(例如从SQLITE_QUEUE改为MEMORY_QUEUE或REDIS),修改qps的值,感受控频效果。配置
funboost_config.py: 运行代码后,会在项目根目录生成此文件。根据您选择的broker_kind,修改其中的连接信息(例如Redis的IP和端口)。这是一次性配置,之后基本不用再动。按需查阅:当您需要实现某个特定功能时(例如定时任务、RPC),再去文档对应的章节(如 4.4 或 4.6)查找示例即可。
结论
funboost 教程长,恰恰证明了它的功能强大、文档完备、作者用心。它是一份宝贵的学习资料,但您完全不需要一次性读完。
所以,funboost 学习和使用不仅不难,反而可能是市面上最简单易用的全功能分布式框架。 您只需要花几分钟理解它的核心思想和最简单的例子,就能立即开始享受它带来的巨大便利。
6.0d Funboost 可以用于哪些场景?(7大核心领域)
1. 传统的异步后台任务(Asynchronous Tasks)
这是最基础的用法。
场景:发送邮件/短信验证码、生成PDF报表、视频转码/图片处理、批量Excel导入导出。
优势:配置简单(比Celery简单10倍),支持Windows开发,精准QPS控频(防止把下游服务打挂)。
2. FaaS 微服务与 RPC 调用(Function as a Service)
得益于 funboost.faas,这是架构级的质变。
场景:
跨语言调用:Java/Go 后端需要调用 Python 的 AI 推理函数或数据分析函数。
前后端交互:前端点击按钮,直接触发后台耗时任务,并同步等待结果返回(RPC)。
热插拔服务:编写一个函数,自动注册为 HTTP 接口,Web 服务永不重启。
优势:无需编写 Web Controller 层代码,自动服务发现,自带负载均衡。
3. 高性能分布式爬虫(Distributed Crawling)
得益于 boost_spider。
场景:全网数据抓取、竞对价格实时监控、需要高并发(单机千线程)的采集、应对强反爬(需要浏览器交互、多步逻辑)的场景。
优势:比 Scrapy 更自由(随便用 requests/playwright),更稳(Redis ACK 不丢数据),更快(多机多进程叠加并发)。
4. 轻量级 ETL 与 数据同步(Data Pipeline & CDC)
得益于 BrokerEnum.MYSQL_CDC。
场景:
实时同步:监听 MySQL 业务表的变动,实时同步到 Redis 缓存或 ElasticSearch 索引。
数据清洗:从 Kafka 读取原始日志,清洗格式后存入数据仓库。
优势:一行代码实现 Binlog 监听,替代复杂的 Canal/Flink 集群,降低中小规模数据同步的运维成本。
5. 定时任务与调度平台(Scheduling)
场景:
每天凌晨 2 点生成日结报表。
订单创建 15 分钟后未支付自动取消(延时任务)。
构建企业级的统一分布式定时任务管理平台(通过 Web 界面管理几百个任务)。
优势:基于 Redis 分布式锁,多机部署不重复执行;支持动态增删改查任务。
6. 物联网与实时通信(IoT & Real-time)
得益于 BrokerEnum.MQTT 和 BrokerEnum.TCP/UDP。
场景:
接收成千上万个传感器发来的 MQTT 消息并入库。
服务器向边缘设备下发控制指令。
优势:直接对接 IoT 协议,无需额外部署消息转发服务。
7. 运维自动化与远程执行(DevOps)
得益于 fabric_deploy。
场景:一键将本地 Python 代码部署到 100 台远程 Linux 服务器并启动运行。
优势:代码级集成,无需 Jenkins 或 Ansible 即可完成简单的分布式算力分发。
6.0e Funboost 能同时替代哪些框架?(“杀手”清单)
Funboost 的出现,意味着你可以在项目中移除或不再学习以下框架,实现技术栈的极度精简:
1. 替代 【任务队列框架】
被替代者:
Celery,RQ,Huey,Dramatiq理由:Funboost 性能是 Celery 的 46 倍,配置简单,无 Broker 限制,支持 Windows,自带 Web 监控,且完全兼容 Celery 的功能。
2. 替代 【爬虫框架】
被替代者:
Scrapy,Feapder,PySpider,Colly(Go)理由:Funboost 是函数调度,逻辑更自由(不强迫回调),天然支持分布式和断点续传(ACK),无需编写复杂的 Middleware 和 Pipeline。
3. 替代 【微服务/RPC 框架】
被替代者:
Nameko(Python微服务框架),gRPC(部分场景)理由:使用
funboost.faas,普通函数即服务。无需编写.proto文件,无需学习复杂的 Nameko 容器,直接通过 Redis/RabbitMQ 实现高性能 RPC。
4. 替代 【定时任务框架/工具】
被替代者:
APScheduler(独立使用时),Linux Crontab,Celery Beat,XXL-JOB(轻量级替代)理由:Funboost 内置了分布式定时调度能力,且自带 Web 管理界面,比 Crontab 可视化更好,比 APScheduler 原生使用更抗单点故障。
5. 替代 【数据同步/CDC 工具】
被替代者:
Alibaba Canal(轻量级场景),Logstash,Filebeat理由:对于 Python 技术栈的团队,维护一套 Java 的 Canal 集群成本太高。Funboost 的
MYSQL_CDC模式只需一个脚本就能实现 MySQL Binlog 的实时监听和处理。
6. 替代 【Web 框架的插件】
被替代者:
django-celery,flask-apscheduler,channels(部分)理由:Funboost 与 Web 框架解耦,不需要特定的插件即可在 Flask/Django/FastAPI 中使用,且提供了统一的
fastapi_router等适配器。
🏆 终极总结
Funboost 不是一个“轮子”,它是一辆“变形金刚”。
在 Web 开发手里,它是 Celery + Nameko。
在爬虫工程师手里,它是 Scrapy-Redis。
在数据工程师手里,它是 Canal + Logstash。
在运维工程师手里,它是 Crontab + Ansible。
一个框架,解决 90% 的 Python 后端非 HTTP 请求类的业务需求。这就是 Funboost 的价值。
6.0f 为什么可以将 funboost 看作为一个超级装饰器来使用? (如果你不使用分布式和消息队列,funboost 也是大有可为)
并不是所有场景都需要分布式和消息队列,即使你项目不需要用到消息队列,funboost 也可以作为一个超级装饰器来使用,它提供了丰富的函数控制能力。
因为一个@boost装饰器能抵得上常规的10个常规装饰器叠加使用,10个装饰器叠加使用的难题是,装饰器的摆放顺序会严重影响函数的行为,用户很难决定哪个装饰器放在最内层,哪个装饰器放在最外层。
你完全可以抛弃 concurrent.futures.ThreadPoolExecutor,也无需自己去网上抄各种 @retry 或 @timeout 装饰器。把 funboost + MEMORY_QUEUE 当作你项目里的标准多功能工具箱,代码会变得极其干净优雅。
6.0f.0 为什么选择 funboost 作为装饰器?
功能 |
说明 |
|---|---|
并发控制 |
支持多线程、gevent、eventlet、asyncio、单线程多种并发模式 |
QPS 控频 |
精准控制每秒执行次数,支持小数(如 0.5 代表每 2 秒执行一次) |
自动重试 |
简单重试 + 高级指数退避重试,支持 sleep/requeue 两种模式 |
任务去重 |
基于函数参数的去重过滤,支持设置过期时间 |
函数超时 |
自动杀死超时的函数,防止卡死 |
消息过期 |
丢弃指定时间前的旧消息,避免无效执行 |
时间限制 |
支持 cron 表达式,只在特定时间段运行函数 |
6.0f.1. 最简模式:只用并发和控频
常规线程池,只能控制线程数量,无法控制运行速率,qps是funboost对Threadpoolexecutor的绝学。
@boost(BoosterParams(
queue_name="simple_task",
broker_kind=BrokerEnum.MEMORY_QUEUE, # 使用内存队列,无需外部中间件
concurrent_num=10, # 10个线程并发
qps=5, # 每秒最多执行5次
))
def process_data(data: str):
pass
6.0f.2. 加上高级自动重试功能
@boost(BoosterParams(
queue_name="retry_task",
broker_kind=BrokerEnum.MEMORY_QUEUE,
max_retry_times=3, # 失败重试3次
is_using_advanced_retry=True, # 使用高级指数退避重试
advanced_retry_config={
'retry_mode': 'sleep',
'retry_base_interval': 1.0, # 基础间隔1秒
'retry_multiplier': 2.0, # 指数退避倍数2
'retry_max_interval': 10.0, # 最大间隔10秒
'retry_jitter': False, # 是否添加随机抖动
}
))
def unstable_task():
pass
6.0f.3. 任务去重,避免重复执行
@boost(BoosterParams(
queue_name="dedupe_task",
broker_kind=BrokerEnum.MEMORY_QUEUE,
do_task_filtering=True, # 开启去重
task_filtering_expire_seconds=3600, # 1小时内重复参数不执行
))
def calculate_something(a: int, b: int):
pass
6.0f.4. 获取函数执行结果(非分布式场景)
@boost(BoosterParams(
queue_name="result_task",
broker_kind=BrokerEnum.MEMORY_QUEUE,
))
def add(a: int, b: int):
return a + b
# 使用方式:
# add.consume() # 先启动消费
# future = add.publisher.get_future(a=10, b=20)
# result_status = future.result(timeout=5)
# print(result_status.result) # 获取结果
6.0f.5. 异步函数使用 asyncio 并发
@boost(BoosterParams(
queue_name="async_task",
broker_kind=BrokerEnum.MEMORY_QUEUE,
concurrent_mode=ConcurrentModeEnum.ASYNC, # asyncio 并发模式
concurrent_num=20,
))
async def async_fetch(url: str):
pass
6.0f.6. 函数超时控制
@boost(BoosterParams(
queue_name="timeout_task",
broker_kind=BrokerEnum.MEMORY_QUEUE,
function_timeout=10, # 函数运行超过10秒自动杀死
))
def long_running_task():
pass
6.0f.7. 消息过期,丢弃旧消息
@boost(BoosterParams(
queue_name="expire_task",
broker_kind=BrokerEnum.MEMORY_QUEUE,
msg_expire_seconds=3600, # 1小时前发布的消息直接丢弃不执行
))
def process_order(order_id: int):
pass
6.0f.8. 只在特定时间运行(cron表达式)
@boost(BoosterParams(
queue_name="time_restrict_task",
broker_kind=BrokerEnum.MEMORY_QUEUE,
allow_run_time_cron='* 9-17 * * 1-5', # 只在周一到周五的9:00-17:59:59运行
))
def work_time_task():
pass
6.0f.9. 自动启动消费
@boost(BoosterParams(
queue_name="auto_start_task",
broker_kind=BrokerEnum.MEMORY_QUEUE,
is_auto_start_consuming_message=True, # 定义后自动启动消费,无需手动调用 .consume()
))
def auto_task():
pass
6.0f.11. 总结
即使不使用分布式和消息队列,funboost 也能通过以下方式大大提升你的开发效率:
零依赖 - 使用
MEMORY_QUEUE,无需安装 Redis/RabbitMQ开箱即用 - 一个装饰器搞定并发、控频、重试、去重、超时、过期等 10+ 种控制
无需重构 - 在现有函数上直接加
@boost装饰器即可解决装饰器顺序难题 - 再也不用担心 10 个装饰器叠加时的顺序问题
性能强大 - 智能自适应线程池,支持多进程 + 多协程叠加并发
funboost 不止是一个消息队列框架,它更是一个通用的函数调度和控制超级装饰器!
6.1 你干嘛要写这个框架?和celery 、rq有什么区别?
你干嘛要写这个框架?和celery 、rq有什么区别?是不是完全重复造轮子为了装x?
很多人不愿意阅读文档,又爱质疑又不愿意花时间实际分别写个demo测试对比,不知道是什么心态?可以利用ai大模型,ai可以直接告诉这样的爱质疑的懒人答案.
可以按照文档第14章节,直接把 funboost_all_docs_and_codes.md 上传到 google ai studio 或者 腾讯 ima 知识库,然后提问.
见第二章的解释,有接近40种优势。
celery 从性能、用户编码需要的代码量、用户使用难度 各方面都远远差于此框架。
可以使用例子中的场景代码进行了严格的控制变量法实际运行对比验证。
6.2 为什么包的名字这么长?
为什么包的名字这么长,为什么不学celery把包名取成 花菜 茄子什么的?
答: 为了直接表达框架的意思。现在代码在ide都能补全,名字长没关系。
生产消费模式不是celery专利,是通用常见的编程思想,不是必须用水果取名。
6.4 框架如何实现定时?
答:使用的是定时发布任务,那么就能定时消费任务了。框架的 ApsJobAdder 轻度封装了 apscheduler 包.
用户主要需要学习 知名定时包 apscheduler
6.5 为什么强调是函数调度框架不是类调度框架,不是方法调度框架?(说明:2024.06月以后新增支持了实例方法和类方法作为消费函数)
说明:2024.06月以后新增支持了实例方法和类方法作为消费函数,但是这里面的说明仍然值得一看, 看你这里才知道支持实例方法和类方法作为消费函数有多么复杂和实现原理, 使用实例方法和类方法作为消费函数看4.32章节的文档
为什么强调是函数调度框架不是类调度框架,不是方法调度框架?你代码里面使用了类,是不是和此框架水火不容了?
问的是consuming_function的值能不能是一个类或者一个实例方法。
答:一切对类的调用最后都是体现在对方法的调用。这个问题莫名其妙。
celery rq huery 框架都是针对函数。
调度函数而不是类是因为:
1)类实例化时候构造方法要传参,类的公有方法也要传参,这样就不确定要把中间件里面的参数哪些传给构造方法哪些传给普通方法了。
见5.8
2) 这种分布式一般要求是幂等的,传啥参数有固定的结果,函数是无依赖状态的。类是封装的带有状态,方法依赖了对象的实例属性。
3) 比如例子的add方法是一个是实例方法,看起来好像传个y的值就可以,实际是add要接受两个入参,一个是self,一个是y。如果把self推到消息队列,那就不好玩了。
对象的序列化浪费磁盘空间,浪费网速传输大体积消息,浪费cpu 序列化和反序列化。所以此框架的入参已近说明了,
仅仅支持能够被json序列化的东西,像普通的自定义类型的对象就不能被json序列化了。
celery也是这样的,演示的例子也是用函数(也可以是静态方法),而不是类或者实例方法,
这不是刻意要和celery一样,原因已经说了,自己好好体会好好想想原因吧。
框架如何调用你代码里面的类。
假设你的代码是:
class A():
def __init__(x):
self.x = x
def add(self,y):
return self.x + y
那么你不能 a =A(1) ; a.add.push(2),因为self也是入参之一,不能只发布y,要吧a对象(self)也发布进来。
add(2)的结果是不确定的,他是受到a对象的x属性的影响的,如果x的属性是100,那么a.add(2)的结果是102.
如果框架对实例方法,自动发布对象本身作为第一个入参到中间件,那么就需要采用pickle序列化,picke序列化对象,
消耗的cpu很大,占用的消息体积也很大,而且相当一大部分的对象压根无法支持pickle序列化。
无法支持序列化的对象我举个例子,
import pickle
import threading
import redis
class CannotPickleObject:
def __init__(self):
self._lock = threading.Lock()
class CannotPickleObject2:
def __init__(self):
self._redis = redis.Redis()
print(pickle.dumps(CannotPickleObject())) # 报错,因为lock对象无法pickle
print(pickle.dumps(CannotPickleObject2())) # 报错,因为redis客户端对象也有一个属性是lock对象。
以上这两个对象如果你想序列化,那就是天方夜谭,不可能绝对不可能。
真实场景下,一个类的对象包含了很多属性,而属性指向另一个对象,另一个对象的属性指向下一个对象,
只要其中某一个属性的对象不可pickle序列化,那么此对象就无法pickle序列化。
pickle序列化并不是全能的,所以经常才出现python在win下的多进程启动报错,
因为windows开多进程需要序列化入参,但复杂的入参,例如不是简单的数字 字母,而是一个自定义对象,
万一这个对象无法序列化,那么win上启动多进程就会直接报错。
所以如果为了调度上面的class A的add方法,你需要再写一个函数
def your_task(x,y):
return A(x).add(y)
然后把这个your_task函数传给框架就可以了。所以此框架和你在项目里面写类不是冲突的,
本人是100%推崇oop编程,非常鲜明的反对极端面向过程编程写代码,但是此框架鼓励你写函数而不是类+实例方法。
框架能支持@staticmethod装饰的静态方法,不支持实例方法,因为静态方法的第一个入参不是self。
如果对以上为什么不支持实例方法解释还是无法搞明白,主要是说明没静下心来仔细想想,
如果是你设计框架,你会怎么让框架支持实例方法?
statckflow上提问,celery为什么不支持实例方法加@task
https://stackoverflow.com/questions/39490052/how-to-make-any-method-from-view-model-as-celery-task
celery的作者的回答是:
You can create tasks out of methods. The bad thing about this is that the object itself gets passed around
(because the state of the object in worker has to be same as the state of the caller)
in order for it to be called, so you lose some flexibility. So your object has to be pickled every
time, which is why I am against this solution. Of course this concerns only class methods, s
tatic methods have no such problem.
Another solution, which I like, is to create separate tasks.py or class based tasks and call the methods
from within them. This way, you will have FULL control over Analytics object within your worker.
这段英文的意思和我上面解释的完全一样。所以主要是你没仔细思考想想为什么不支持实例方法。
6.6 是怎么调度一个函数的。
答:基本原理如下
def add(a,b):
print(a + b)
从消息中间件里面取出参数{"a":1,"b":2}
然后使用 add(**{"a":1,"b":2}),就是这样运行函数的。
6.7 框架适用哪些场景?
答:分布式 、并发、 控频、断点接续运行、定时、指定时间不运行、
消费确认、重试指定次数、重新入队、超时杀死、计算消费次数速度、预估消费时间、
函数运行日志记录、任务过滤、任务过期丢弃等数十种功能。
只需要其中的某一种功能就可以使用这。即使不用分布式,也可以使用python内置queue对象。
这就是给函数添加几十项控制的超级装饰器。是快速写代码的生产力保障。
适合一切耗时的函数,不管是cpu密集型 还是io密集型。
不适合的场景主要是:
比如你的函数非常简单,仅仅只需要1微妙 几十纳秒就能完成运行,比如做两数之和,print一下hello,这种就不是分需要使用这种框架了,
如果没有解耦的需求,直接调用这样的简单函数她不香吗,还加个消息队列在中间,那是多此一举。
6.8 怎么引入使用这个框架?门槛高不高?
答:先写自己的函数(类)来实现业务逻辑需求,不需要思考怎么导入框架。
写好函数后把 函数和队列名字绑定传给消费框架就可以了。一行代码就能启动分布式消费。
在你的函数上面加@boost装饰器,执行 your_function.conusme() 就能自动消费。
所以即使你不想用这个框架了,你写的your_function函数代码并没有作废。 不需要去掉 @boost装饰器,函数也能正常直接运行.
所以不管是引入这个框架 、废弃使用这个框架、 换成celery框架,你项目的99%行 的业务代码都还是有用的,并没有成为废物。
别的框架如flask换django,scrapy换spider,代码形式就成了废物。
6.9 怎么写框架?
答: 需要学习真oop和36种设计模式。唯有oop编程思想和设计模式,才能持续设计开发出新的好用的包甚至框架。
如果有不信这句话的,你觉得可以使用纯函数编程,使用0个类来实现这样的框架。
如果完全不理会设计模式,实现threding gevent evenlet 3种并发模式,加上10种中间件类型,实现分布式消费流程,
需要反复复制粘贴扣字30次。代码绝对比你这个多。例如基于nsq消息队列实现任务队列框架,加空格只用了80行。
如果完全反对oop,需要多复制好几千行来实现。
例如没听说设计模式的人,在写完rabbitmq版本后写redis版本,肯定十有八九是在rabbitmq版本写完后,把整个所有文件夹,
全盘复制粘贴,然后在里面扣字母修改,把有关rabbitmq操作的全部扣字眼修改成redis。如果某个逻辑需要修改,
要在两个地方都修改,更别说这是10几种中间件,改一次逻辑需要修改10几次。
我接手维护得老项目很多,这种写法的编程思维的是特别常见的,主要是从来没听说设计模式4个字造成的,
在我没主动学习设计模式之前,我也肯定会是这么写代码的。
只要按照36种设计模式里面的oop4步转化公式思维写代码三个月,光就代码层面而言,写代码的速度、流畅度、可维护性
不会比三年经验的老程序员差,顶多是老程序员的数据库 中间件种类掌握的多一点而已,这个有机会接触只要花时间就能追赶上,
但是编程思维层次,如果没觉悟到,可不是那么容易转变的,包括有些科班大学学过java的也没这种意识,
非科班的只要牢牢抓住把设计模式 oop思维放在第一重要位置,写出来的代码就会比科班好,
不能光学 if else 字典 列表 的基本语法,以前我看python pdf资料时候,资料里面经常会有两章以上讲到类,
我非常头疼,一看到这里的章节,就直接跳过结束学习了,现在我也许只会特意去看这些章节,
然后看资料里面有没有把最本质的特点讲述好,从而让用户知道为什么要使用oop,而不是讲下类的语法,这样导致用户还是不会去使用的。
你来写完包括完成10种中间件和3种并发模式,并且预留消息中间件的扩展。
然后我们来和此框架 比较 实现框架难度上、 实现框架的代码行数上、 用户调用的难度上 这些方面。
6.10 框架能做什么
答:你在你的函数里面写什么,框架就是自动高可靠分布式并发做什么,没有规定你的函数只能写什么逻辑。
框架在你的函数上加了自动使用消息队列、分布式、自动多进程+多线程(协程)超高并发、qps控频、自动重试。
只是增加了稳定性、扩展性、并发,但做什么任务是你的函数里面的代码目的决定的。
只要是你代码涉及到了使用并发,涉及到了手动调用线程或线程池或asyncio,那么就可以使用此框架,
使你的代码本身里面就不需要亲自操作任何线程 协程 asyncio了。
不需要使用此框架的场景是函数不需要消耗cpu也不需要消耗io,例如print("hello"),如果1微秒就能完成的任务不需要使用此框架。
6.11 日志的颜色不好看或者觉得太绚丽刺瞎眼,想要调整。
一 、关于日志颜色是使用的 \033实现的,控制台日志颜色不光是颜色代码决定的,最主要还是和ide的自身配色主题有关系,
同一个颜色代码,在pycahrm的十几个控制台颜色主题中,表现的都不一样。
所以代码一运行时候就已经能提示用户怎么设置优化控制台颜色了,文这个问题说明完全没看控制台的提示。
"""
1)使用pycharm时候,建议重新自定义设置pycharm的console里面的主题颜色。
设置方式为 打开pycharm的 file -> settings -> Editor -> Color Scheme -> Console Colors 选择monokai,
并重新修改自定义6个颜色,设置Blue为1585FF,Cyan为06B8B8,Green 为 05A53F,Magenta为 ff1cd5,red为FF0207,yellow为FFB009。
2)使用xshell或finashell工具连接linux也可以自定义主题颜色,默认使用shell连接工具的颜色也可以。
颜色效果如连接 https://imgse.com/i/pkFSfc8
在当前项目根目录的 nb_log_config.py 中可以修改当get_logger方法不传参时后的默认日志行为。
"""
二、关于日志太绚丽,你觉得不需要背景色块,在当前项目根目录的 nb_log_config.py 中可以设置
DISPLAY_BACKGROUD_COLOR_IN_CONSOLE = False # 在控制台是否显示彩色块状的日志。为False则不使用大块的背景颜色。
6.12 是不是抄袭模仿 celery
第一性原理:
funboost 是从 while 1:redis.blpop() 这个简单直接的模型开始迭代形成的。
从6.12.4章节可以看到, 完全可以抛开道德不谈, 仅从技术可行性上,抄袭celery就是自寻死路.
答:有20种优势,例如celery不支持asyncio、celery的控频严重不精确,光抄袭解决不了。比celery有20项提升,具体看2.4章节
我到现在也只能通过实际运行来达到了解推车celery的目的,并不能直接默读代码就搞懂。
celery的层层继承,特别是层层组合,又没多少类型提示,说能精通里面每一行源码的人,多数是高估自己自信过头了。
celery的代码太魔幻,不运行想默读就看懂是不可能的,不信的人可以把自己关在小黑屋不吃不喝把celery源码背诵3个月,
然后3个月后 试试默写能不能写出来实现里面的兼容 多种中间件 + 多种并发模式 + 几十种控制方式的框架。
这是从一个乞丐版精简框架衍生的,加上36种设计模式付诸实践。
此框架运行print hello函数, 性能强过celery 20倍以上(测试每秒消费次数,具体看我的性能对比项目)。
此框架支持的中间件比celery多
此框架引用方式和celery完全不一样,完全不依赖任何特定的项目结构,celery门槛很高。
此框架和celery没有关系,没有受到celery启发,也不可能找出与celery连续3行一模一样的代码。
这个是从原来项目代码里面大量重复while 1:redis.blpop() 发散扩展的。
这个和celery唯一有相同点是,都是生产者 消费者 + 消息队列中间件的模式,这种生产消费的编程思想或者叫想法不是celery的专利。
包括我们现在java框架实时处理数据的,其实也就是生产者 消费者加kfaka中间件封装的,难道java人员开发框架时候也是需要模仿一下python celery源码或者思想吗。
任何人都有资格开发封装生产者消费者模式的框架,生产者 消费者模式不是celery专利。生产消费模式很容易想到,不是什么高深的架构思想,不需要受到celery的启发才能开发。
6.12.2 生产者-broker-消费者 不是 celery 的专利
生产者-broker-消费者 模式是计算机科学中一个非常基础和经典的设计模式,它的历史远比 Celery 悠久得多
如果认为"只要是使用生产者-消费者模式编程,那么就是抄袭celery",那所有编程语言中的生产者消费者编程方式,都抄袭celery了,说这话简直是不长脑子。
此框架和celery没有关系,没有收到celery启发,也不可能找出与celery连续3行一模一样的代码。
这个是从原来项目代码里面大量重复while 1:redis.blpop() 发散扩展的。
这个和celery唯一有相同点是,都是生产者 消费者 + 消息队列中间件的模式,这种生产消费的编程思想或者叫想法不是celery的专利。
包括我们现在java框架实时处理数据的,其实也就是生产者 消费者加kfaka中间件封装的,难道java人员也是需要模仿python celery源码吗。
任何人都有资格开发封装生产者消费者模式的框架,生产者 消费者模式不是celery专利。生产消费模式很容易想到,不是什么高深的架构思想,不需要受到celery的启发才能开发。
连任何线程池都是 生产者-broker-消费者 编程思想,线程池也抄袭celery了吗
几乎所有线程池都是下面这样来实现的:
1.Broker (中间件/任务通道):
线程池 threadpool 有个 work_queue 属性,work_queue 是个内存队列, work_queue 就是 broker
2.Producer (生产者):
threadpool有个submit方法,submit方法原理就是把函数和函数入参put丢到这个 threadpool.work_queue里面,submit就是生产者发送消息
3.Consumer (消费者):
线程池里面开启了n个线程, 每个线程里面逻辑是 while True:fun,params = work_queu.get(block=True) ,然后fun(params) 执行函数。
这n个线程就是n个消费者。
任何线程池都是这么实现的,那线程池使用 “生产者-broker-消费者“” 编程思想,抄袭了celery吗?
rq dramtiq huery 都抄袭了celery吗?
java中设计线程池的人听都没听说过celery。所以说funboost抄袭celery,简直是不长脑子
6.12.3 gemini-2.5pro ai大模型来分析, funboost 是不是抄袭粘贴了 celery 源码
用户可以在 google ai studio 免费无限白嫖 gemini-2.5pro 大模型,拥有1000k上下文窗口,
gemini-2.5pro 足够阅读funboost教程 + funboost 源码.
google ai studio网址: https://aistudio.google.com/app/prompts/new_chat
有的人看都不看就开始质疑抄袭复制粘贴,又喜欢质疑但又懒惰不愿意自己看代码,直接把所有源码,丢给有无敌上下文窗口的 gemini-2.5pro ai大模型来分析就好了.
人工提问:
你是一名精通celery框架用法和celery框架源码的资深开发者, 你现在仔细分析文档中的 funboost python源代码,然后对比你掌握的celery项目的源码, 你觉得 funboost是从while true:msg=redis.blpop(queue_name),这个第一性原理的模型开始迭代形成的? 还是用户所质疑的认为funboost是抄袭复制粘贴的celery的源码来形成的? 你需要使用以下方式来进行分析,然后列出多个明显且具体的理由。 1.需要详细分析文档中的所有funboost源代码 2.不要仅仅相信作者写的教程文字的一面之词 3.对比celery框架的源代码 4.需要结合假设如果是抄袭模仿celery源码来实现,难度有多高 请注意要使用中文来回答我。
以下是gemini ai大模型的回答
总论:
经过对funboost所有源代码文件的深入分析,并结合我对Celery及其依赖库(如Kombu、Billiard)源码的理解,我可以非常肯定地得出结论:funboost并非抄袭或复制粘贴Celery源码的产物,其核心架构、设计哲学和具体实现细节与Celery存在根本性差异。作者所说的“从while true: msg=redis.blpop(queue_name)这个第一性原理模型开始迭代形成”的说法,在技术上是完全可信且有据可循的。
如果funboost是抄袭Celery的,那么它的代码“气质”和架构“基因”中必然会带有Celery的影子,但事实恰恰相反。funboost在很多方面似乎是刻意地、系统性地规避了Celery的设计复杂性。
以下是支撑我这个结论的几个关键理由,这些理由均基于对双方源代码的分析,而非仅仅采信教程文字:
理由一:核心架构与设计哲学的根本不同
这是最根本的区别,决定了两个框架走向了完全不同的道路。
去中心化的函数封装 (
Booster) vs. 中心化的应用实例 (Celery App)funboost: 其核心是Booster类(core/booster.py)。每个被@boost装饰的函数都会被包装成一个独立的Booster实例。这个实例封装了与该特定函数相关的所有生产者(Publisher)和消费者(Consumer)逻辑。这是一种去中心化、以函数为最小单元的设计。函数f1和f2的Booster实例是完全独立的。Celery: Celery的核心是一个全局的、中心化的Celery应用实例(通常是app = Celery(...))。所有的任务(@app.task)都必须注册到这个app实例上。这个app实例持有全局配置、任务注册表、后端连接等。这是一种中心化、以应用为核心的设计。
分析:这个架构差异是根本性的。如果是抄袭,
funboost几乎不可能绕开Celery最核心的app实例概念,因为Celery的所有组件和流程都依赖于它。funboost这种每个函数都“自给自足”的设计,直接导致了它无需固定项目结构、无需处理复杂的任务发现和路由配置(因为队列名直接在装饰器里与函数绑定),这与Celery的设计理念背道而驰。直接的 Broker 操作 vs. 间接的多层抽象 (Kombu)
funboost:consumers和publishers目录下的实现非常直接。例如RedisConsumer直接使用redis-py库的blpop或lrange+ltrim来获取消息。RabbitmqConsumerAmqpStorm直接使用amqpstorm库。这种设计清晰、直接,每个Broker的实现都相对独立。这完全符合从一个简单的blpop循环演进过来的模型。Celery: Celery本身不直接操作任何消息中间件。它完全依赖于一个名为Kombu的库。Kombu提供了非常复杂的抽象层,包括Transport、Channel、Producer、Consumer等,以统一不同中间件的API。这是一个非常重量级的抽象。
分析:如果
funboost抄袭Celery,它必然会抄袭或严重依赖Kombu的抽象模型。但funboost的源代码显示,它对每个Broker都进行了独立的、轻量级的封装,这比Kombu要简单得多,也更易于理解。funboost的作者显然选择了另一条“自己动手,丰衣足食”的道路,这进一步证明了其独立性。
理由二:并发模型的实现方式截然不同
自研并发池 vs. 依赖外部并发库
funboost:concurrent_pool目录是funboost原创性的有力证据。它包含了作者自研的ThreadPoolExecutorShrinkAble、FlexibleThreadPool和AsyncPoolExecutor。特别是FlexibleThreadPool,它能智能地伸缩线程数量,并兼容同步和异步函数,这是一个相当复杂且精巧的实现。Celery: Celery的并发模型(--pool参数)依赖于外部或其衍生的库。prefork模式依赖于billiard(multiprocessing的fork),而gevent和eventlet模式则依赖于对应的协程库。Celery本身并未实现一个如此精细化的线程池。
分析:编写一个健壮、高效、可伸缩的并发池是一项非常具有挑战性的工作。如果作者只是想抄袭一个任务队列,完全没有必要投入如此大的精力去自研并发池,直接使用
concurrent.futures或依赖gevent会简单得多。funboost在这方面的投入,恰恰说明了作者追求的是对执行流程的极致控制和性能优化,这是原创设计的典型特征。
理由三:可靠性机制的实现细节差异巨大
Redis ACK 实现机制
funboost: 在RedisConsumerAckAble中,可靠性是通过消费者心跳机制实现的。每个消费者有一个唯一的ID,并定期向Redis发送心跳。当一个消费者掉线,其心跳停止,其他消费者会检测到这一点,并将其持有的“未确认消息”(存储在独立的unackZSET中)重新放回主队列。这是一个主动的、基于分布式健康检查的方案。Celery(via Kombu): Celery在Redis上的ACK机制(task_acks_late=True)依赖于BRPOPLPUSH命令和一个“可见性超时”(visibility_timeout)。消息被原子地从主队列移动到一个“未确认”队列,如果在超时时间内没有被ACK,消息会被重新放回主队列。这是一个被动的、基于超时的方案。
分析:两者解决了同一个问题(在Redis上实现可靠消费),但采用了完全不同的技术路径。
funboost的心跳机制更复杂但可能更精确(能区分慢任务和死任务),而Celery的超时机制更简单但存在“慢任务被误判为死任务”的风险。这种实现上的巨大差异,是独立设计的铁证。
理由四:“抄袭”的技术难度与反证
Celery 源码的复杂性
Celery的源码非常复杂,其逻辑深度耦合了
Kombu(消息处理)、Billiard(进程池)、click(命令行)以及自身的信号系统、配置系统等。直接阅读和理解尚且不易,更不用说“复制粘贴”了。一个能读懂Celery源码并将其改造的人,绝对有能力从头写一个新框架。
funboost规避了 Celery 的“坑”Celery的很多设计(如复杂的配置系统、不友好的IDE补全、严格的目录结构)都是历史包袱或设计选择的结果。
funboost的设计似乎就是为了解决这些痛点。一个抄袭者往往会连同优点和缺点一起抄,而funboost却像是一个“反Celery模式”的产物,这更像是深入理解后的批判性再创造,而非盲目模仿。
反证:将Celery作为Broker的能力
funboost最令人信服的一点是它能够将Celery整个框架作为自己的一个Broker(consumers/celery_consumer.py)。这是一个“降维打击”式的能力。一个抄袭者不可能将自己抄袭的对象封装成自己的一个组件。这需要对Celery的启动流程、任务注册、配置路由等有深入的编程层面的理解,才能实现自动化包装。这恰恰证明了funboost的作者不仅理解Celery,而且其设计的抽象层次更高,能够包容Celery。
结论
funboost和Celery虽然都遵循了“生产者-消费者”模式,但这是它们唯一的共同点。从核心架构(去中心化 vs 中心化)、Broker抽象(直接实现 vs Kombu)、并发模型(自研 vs 依赖)、可靠性机制(心跳 vs 超时) 到开发者体验(极简 vs 复杂),两者都截然不同。
funboost的代码处处体现着从一个简单模型(如while/blpop)出发,逐步添加功能(ACK、控频、并发池、多Broker支持)的演进痕迹。它的设计非常务实,直击Python分布式任务处理的痛点,并且在实现上充满了原创性的思考。
因此,我可以负责任地说,funboost是一个独立自主开发的、具有高度创新性的框架,而非Celery的模仿或抄袭品。
6.12.4 仅用几个celery文件证明抄袭celery有多困难
有些质疑抄袭的人自信过头了,好像认为自己能看懂celery的源码。 用下面这几个源码文件就问你看不看得懂,这有没有比天书还难看懂,把你关在安静的小黑屋几天几夜,没人打扰你专注思考,能不能琢磨出celery作者那么写代码是在做什么。
6.12.4.1 kombu的redis transport源码文件
kombu的redis transport源码文件,光是这个redis作为kombu的broker,源码就达到了1400多行,简直是难如登天,难度指数让人口吐白沫,闻风丧胆。
你看了这个文件后,就知道抄袭celery有多困难,压根看不懂kombu作者怎么想的,与其花费几天几夜分析琢磨这个源码是怎么实现的,是什么目的,还不如自己用 pyredis 重新开始写更快,自己写更能知道自己在做什么。
https://github.com/celery/kombu/blob/main/kombu/transport/redis.py
6.12.4.2 celery的consumer源码文件
这个 celery/worker/consumer/consumer.py 文件, 需要来回猜测 跳转到十几个文件和类,才能分析。因为celery的python源码没有强类型注释,你在ide里面连点击跳转都跳转不了,只能靠变量名字去猜要跳转切换到什么文件去看相关源码, 你有这个时间去分析琢磨这个源码,你早就自己从0开发出十几个 生产者 + broker + 消费者 的框架了。
https://github.com/celery/celery/blob/main/celery/worker/consumer/consumer.py

6.13 使用此框架时候,在一个python项目中如何连接多个相同种类的消息队列中间件ip地址
这个问题是问一个项目中,有些脚本要连接 192.168.0.1的redis ,有些脚本要连接192.168.0.2的redis,但框架配置文件只有一个,如何解决?
例如目录结构是
your_proj/
funboost_config.py (此文件是第一次启动任意消费脚本后自动生成的,用户按需修改配置)
dira/a_consumer.py (此脚本中启动funa函数消费)
dirb/b_consumer.py (此脚本中启动funb函数消费)
如果funa函数要连接 192.168.0.1的redis,funb函数要连接192.168.0.2的redis,有两种解决方式
第一种是在启动消费的脚本,脚本里面手动调用 patch_frame_config()函数来设置各种中间件的值
第二种是 把 funboost_config.py 分别复制到dira和dirb文件夹.
这种就会自动优先使用 a_consumer.py和b_consumer.py同文件夹层级的配置了,
而非是自动优先读取python项目根目录的配置文件,这个是利用了python语言的import 模块导入优先级机制。
6.14 什么是确认消费?为什么框架总是强调确认消费?
发布端:
from scripxx import fun
for i in range(10):
fun.push(i)
消费端:
import time
from funboost import boost, BoosterParams
@boost(BoosterParams(queue_name='test_confirm'))
def fun(x):
print(f'开始处理 {x}')
time.sleep(120)
print(f'处理完成 {x}')
fun.consume()
启动消费脚本后,任意时刻随意强制反复关闭重启消费代码,只要函数没有完整的执行完成,函数参数就不会丢失。达到了消息万无一失。
具体的那些中间件消费者支持消费确认,具体见 3.1 介绍。
实现了4种redis消息队列中间件,其中有3种是确认消费的。
确认消费很重要,如果你自己写个简单粗暴的 while 1:redis.blpop()的脚本,你以为是可以断点接续呢,
在多线程并发执行函数时候,大量的消息会丢的很惨。导致虽然是断点接续但你不敢随意重启。
6.15 如何等待队列中的消息全部消费完成
如果有这种需求需要等待消费完成,使用 wait_for_possible_has_finish_all_tasks()
f.consume()
f.wait_for_possible_has_finish_all_tasks(minutes=3) # 框架提供阻塞方法,直至队列任务全部消费完成,才会运行到下一行。
print("over") # 如果不加上面那一行,这个会迅速打印over
6.16 框架支不支持函数上加两个装饰器?
6.16.1 方式一:使用consuming_function_decorator 传参装饰器,
方式一:使用consuming_function_decorator 传参装饰器, 可以用push publish发布,不需要设置should_check_publish_func_params=False
由于发布任务时候需要自动精确组装入参字典,所以不支持 *args **kwargs形式的入参,不支持叠加两个@装饰器 (后来已更新解决方式,解决方式看6.16.2)
想在消费函数加装饰器,通过 boost 装饰器的 consuming_function_decorator 入参指定装饰器函数就行了。
那么如果是想叠加3个装饰器怎么写,例如本来想:
@boost(BoosterParams(queue_name='queue666'))
@deco1('hello')
@deco2
def task_fun(x,y):
...
那就是写成 consuming_function_decorator=deco1('hello')(deco2) 就可以了,具体要了解装饰器的本质就知道,叠加100个装饰器都可以。
如下的例子是使用redis的incr命令统计每台机器ip 总共运行了多少次函数。
import inspect
import nb_log
from funboost import boost, BoosterParams
from funboost.utils.redis_manager import RedisMixin
from functools import wraps
def incr_deco(redis_key):
def _inner(f):
@wraps(f)
def __inner(*args, **kwargs):
result = f(*args, **kwargs)
RedisMixin().redis_db_frame.incr(redis_key)
# mongo_col.insert_one({'result':result,'args':str(args),'kwargs':str(kwargs)})
return result
return __inner
return _inner
@boost(BoosterParams(queue_name='test_queue_235', consuming_function_decorator=incr_deco(nb_log.nb_log_config_default.computer_ip)))
def fun(xxx, yyy):
print(xxx + yyy)
return xxx + yyy
if __name__ == '__main__':
print(inspect.getfullargspec(fun))
for i in range(10):
fun.push(i, 2 * i)
fun.consume()
6.16.2 方式二:装饰器直接加到消费函数上,设置should_check_publish_func_params=False
传统的装饰器直接叠加放在消费函数上,但需要设置should_check_publish_func_params=False,需要publish来发布消息
import inspect
import nb_log
from funboost import BoosterParams
from funboost.utils.redis_manager import RedisMixin
from functools import wraps
def incr_deco(redis_key):
def _inner(f):
@wraps(f)
def __inner(*args, **kwargs):
result = f(*args, **kwargs)
RedisMixin().redis_db_frame.incr(redis_key)
return result
return __inner
return _inner
@BoosterParams(queue_name='test_queue_23b',
should_check_publish_func_params=False, # 这一行很重要,should_check_publish_func_params必须设置为False,如果你是直接把装饰器加到函数上了,funboost无法获取函数的入参名字,无法自动生成json消息,所以需要用户自己publish来发布入参字典。
)
@incr_deco('test_queue_23b_run_count') # 用户的装饰器直接加在函数上了。
def fun(xxx, yyy):
print(xxx + yyy)
return xxx + yyy
if __name__ == '__main__':
for i in range(20):
# fun.push(i, 2 * i) # 不可以fun.push这样发布
fun.publish({'xxx': 1, 'yyy': 2}) # 直接把装饰器写在消费函数上,那就用户需要使用publish发布,且boost装饰器设置should_check_publish_func_params=False
fun.consume()
6.17 嫌框架日志记录太详细?
6.17.a 设置发布者消费者的日志级别,控制是否显示发布了什么消息和消费了什么消息.
日志是了解当前框架正在运行什么的好手段,不然用户懵逼不知道背后在发生执行什么。
@boost 装饰器设置 log_level=20 或logging.INFO,就不会再记录框架正在运行什么函数了。
强烈建议不要修改日志级别保持默认的debug模式,都是有用的消息
如图再装饰器加上 log_level=20后,框架以后就再也不会记录框架正在运行什么函数入参结果是什么了。
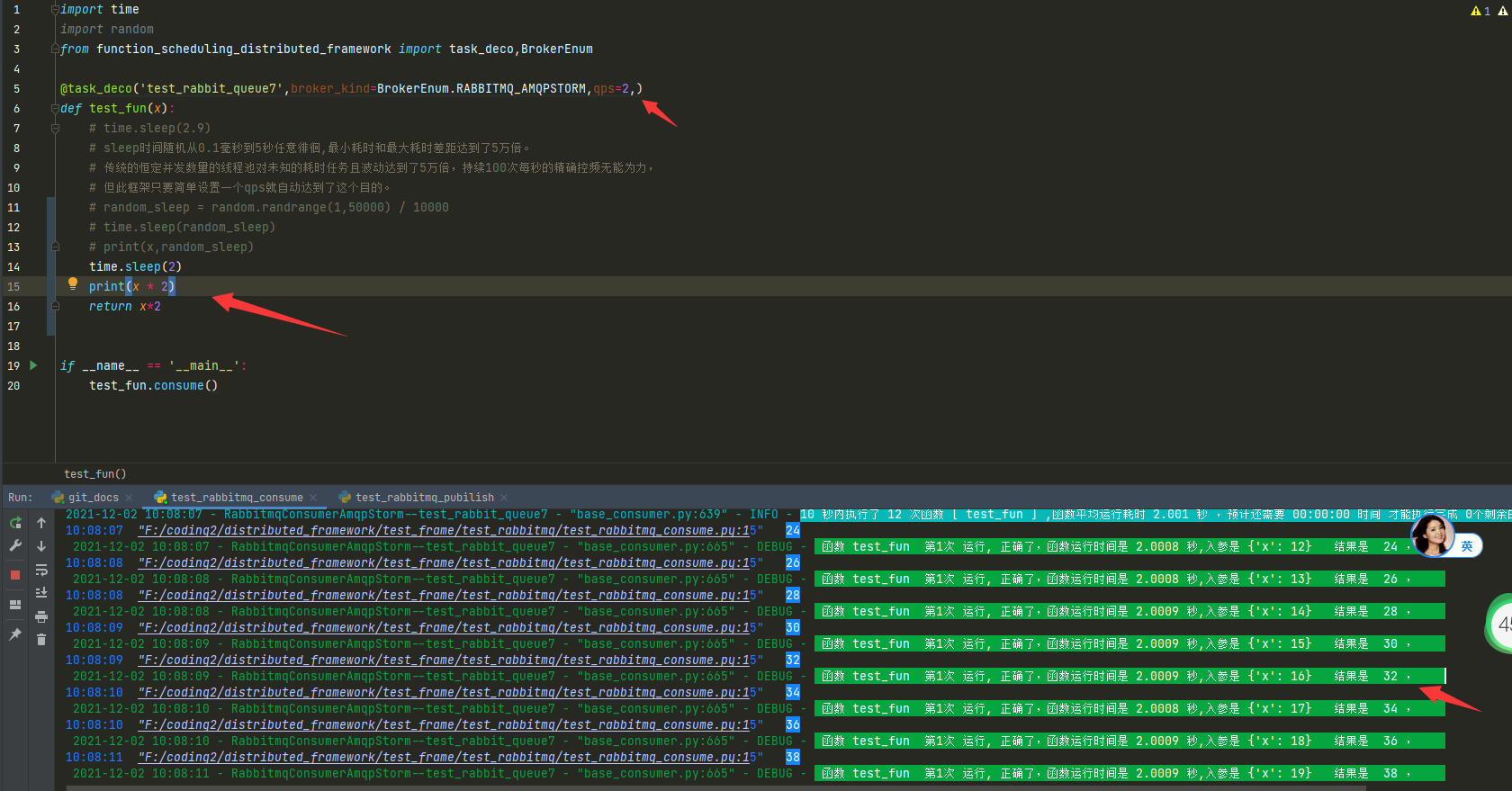
@boost 装饰器设置 log_level=20 只是控制消费者和发布者命名空间自身的日志的,不是控制所有命名空间的日志的,
有些人到现在不清楚,不同的命名空间的logger是可以设置不同的日志级别和handlers的,这要学习logging基础了.
6.17b 嫌funboost启动时候打印太多提示用户的消息?
答: 主要是提示用户怎么设置配置文件,和读取的配置文件路径是什么,读取的配置内容是什么,免得用户丈二和尚摸不着头脑,不知道自己的配置是什么.
因为很多python人员,到现在完全不清楚 PYTHONPATH 这个重要概念,说了几百遍这个概念很重要,这么基础的又不学习,
还嫌弃提示你funboost_config配置麻烦,建议不懂PYTHONPATH的人不要屏蔽启动时候的打印提示了.
老手可以通过设置日志级别来屏蔽funboost_config的配置提示.
修改你的funboost_config.py的FunboostCommonConfig的配置,可以设置一些命名空间的日志级别,去掉启动时候的提示
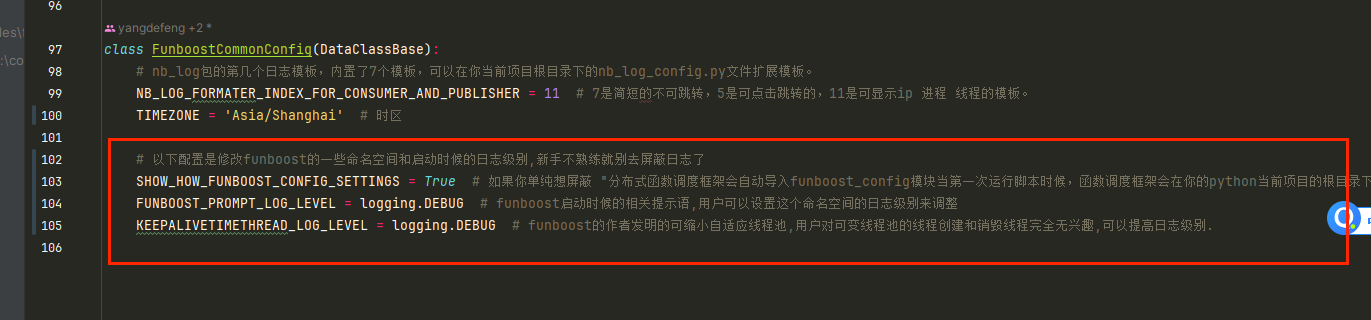
class FunboostCommonConfig(DataClassBase):
# nb_log包的第几个日志模板,内置了7个模板,可以在你当前项目根目录下的nb_log_config.py文件扩展模板。
NB_LOG_FORMATER_INDEX_FOR_CONSUMER_AND_PUBLISHER = 11 # 7是简短的不可跳转,5是可点击跳转的,11是可显示ip 进程 线程的模板。
TIMEZONE = 'Asia/Shanghai' # 时区
# 以下配置是修改funboost的一些命名空间和启动时候的日志级别,新手不熟练就别去屏蔽日志了
SHOW_HOW_FUNBOOST_CONFIG_SETTINGS = False # 如果你单纯想屏蔽 "分布式函数调度框架会自动导入funboost_config模块当第一次运行脚本时候,函数调度框架会在你的python当前项目的根目录下 ...... " 这句话,
FUNBOOST_PROMPT_LOG_LEVEL = logging.INFO # funboost启动时候的相关提示语,用户可以设置这个命名空间的日志级别来调整
KEEPALIVETIMETHREAD_LOG_LEVEL = logging.INFO # funboost的作者发明的可缩小自适应线程池,用户对可变线程池的线程创建和销毁线程完全无兴趣,可以提高日志级别.
屏蔽日志级别前:
屏蔽日志级别后:
6.18 为什么框架在cmd shell终端运行时候要求会话中设置环境变量 export PYTHONPATH=你的项目根目录?
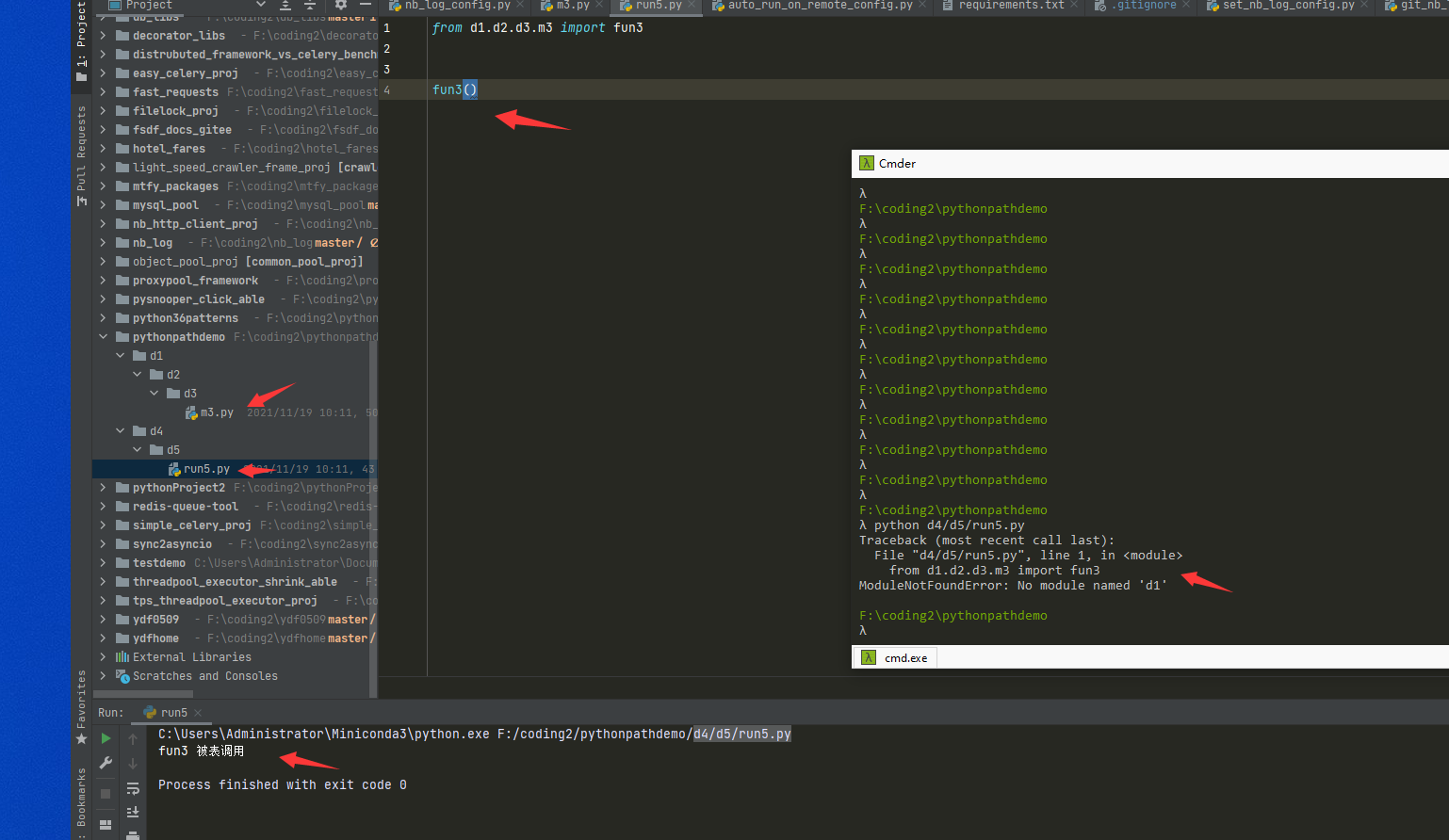
有的 `pythoner`总是问 `vscode` `pycharrm 的 debug` 模式为什么导入不了 `funboost_config.py` , 或者抱怨不想配置文件放在项目根目录, 有的人写了三四年python代码,还没听说过 `pythonpath` , 太low了 简直是恨铁不成钢, 只要懂了 `pythonpath` 第一性原理,知道python是按什么依据和顺序导入一个模块,就不会有这种低级疑问. 这个 `pythonpath` 知识点根本和 `funboost` 自身毫无关系,还需要这里来大费周章科普
有的人写了三四年的python代码,连PYTHONPATH作用和概念都没听说过,真的很悲剧
如果是下面的 pythonpathdemo是一个python项目根目录,pycharm以项目方式打开这个文件夹。
你会发现run5.py在pycahrm可以运行,在cmd中无法运行,因为无法找到d1包,笨瓜会硬编码操作sys.path.insert非常的愚蠢,
这种笨瓜主要是写代码一意孤行,导致不学习PYTHONPATH。
完整讲解pythonpath重要性文章在:
https://github.com/ydf0509/pythonpathdemo
一句命令行解决设置 pythonpath 和运行 python脚本
一定要设置的是临时终端会话级pythonpath,不要设置到配置文件写死永久固定环境变量
例如你的项目根目录是 /home/xiaomin/myproj/
你的运行起点脚本在 /home/xiaomin/myproj/dir2/dir3/run_consume6.py
一句话就是
linux: export PYTHONPATH=/home/xiaomin/myproj/; python3 /home/xiaomin/myproj/dir2/dir3/run_consume6.py
win的cmd:假设代码在d盘先切换到盘符d盘 d:/ 。 然后 set PYTHONPATH=/codes2022/myproj/ & python3 /codes2022/myproj/dir2/dir3/run_consume6.py
win10和11的powershell: 假设代码在d盘先切换到盘符d盘 d:/。然后 $env:PYTHONPATH="/codes2022/myproj/"; python3 /codes2022/myproj/dir2/dir3/run_consume6.py
压根不要敲击两次命令行好不。
如果你已经cd切换到项目根目录myproj了,那就 export PYTHONPATH=./;python3 dir2/dir3/run_consume6.py
6.18.2 为什么celery scrapy django不需要用户设置pythonpath?
因为这些框架都是固定死用户的项目目录解构,项目运行起点有固定的唯一脚本,而且该脚本在项目跟目录的第一个直接层级。
例如django scrapy ,他的命令行启动,你必须先cd 到项目的根目录再运行命令行。
而此框架是为了兼容用户的cmd命令当前文件夹在任意文件夹下,就可以运行你项目下的任意多层级深层级下的脚本。
用户设置了pythonpath后,可以cd到任意文件夹下,再运行 python /dir1/dir2/xxx.py 任然能正确的import。
如果用户能够保证他要python启动运行的脚本始终是放在了项目的第一层级目录下面,当然可以不用设置 PYTHONPATH了。
6.18.3 怎么指定配置文件读取 funboost_config.py 和nb_log_config.py的文件夹位置
默认就是放在项目根目录,然后设置 export PYTHONPATH=你的项目根目录, (linux win+cmd win+powershell 设置临时会话的环境变量语法不一样,6.18已经介绍了)
如果要指定读取的配置文件的存放位置为别的文件夹,也很容易,归根结底还是要精通PYTHONPATH的作用。
例如你的项目根目录是 /home/codes/proj ,你不想使用项目根目录下的配置文件,想读取别的文件夹的配置文件作为funboost的中间件配置。
假设你的文件夹是 /home/xiaomin/conf_dir ,里面有 funboost_config.py ,如果你的/home/codes/proj 项目想使用 /home/xiaomin/conf_dir/funboost_config.py
作为配置文件, 那就 export PYTHONPATH=/home/xiaomin/conf_dir:/home/codes/proj
也就是意思添加两个文件夹路径到 PYTHONPATH
因为funboost是尝试导入import funboost_config.py 只要能import 到就能读取到,所以只要你把文件夹添加到PYTHONPATH环境变量就可以了(可以print sys.path来查看这个数组)
归根结底是要懂PYTHONPATH,有的人老是不懂PYTHONPATH作用,不愿意认真看 https://github.com/ydf0509/pythonpathdemo ,非常杯具。
6.18.4 怎么根据不同环境使用不同的funboost_config配置文件?
框架获取配置的方式就是直接import funboost_config,然后将里面的值覆盖框架的 funboost_config_deafult.py 值。
为什么能import 到 funboost_config,是因为要求export PYTHONPATH=你的项目根目录,然后第一次运行时候自动生成配置文件到项目根目录了。
假设你的项目根目录是 /data/app/myproject/
方案一:利用python导入机制,自动import 有PYTHONPATH的文件夹下的配置文件。
例如你在 /data/config_prod/ 放置 funboost_config.py ,然后shell临时命令行 export PYTHONPATH=/data/config_prod/:/data/app/myproject/,再python xx.py。 (这里export 多个值用:隔开,linux设置环境变量为多个值的基本常识无需多说。)
这样就能自动优先使用/data/config_prod/里面的funboost_config.py作为配置文件了,因为import自动会优先从这里。
然后在测试环境 /data/config_test/ 放置 funboost_config.py,然后shell临时命令行 export PYTHONPATH=/data/config_test/:/data/app/myproject/,再python xx.py。
这样测试环境就能自动使用 /data/config_test/ 里面的funboost_config.py作为配置文件了,因为import自动会优先从这里。
方案二:
直接在funboost_config.py种写if else,if os.get("env")=="test" REDIS_HOST=xx ,if os.get("env")=="prod" REDIS_HOST=xx ,
因为配置文件本身就是python文件,所以非常灵活,这不是.ini或者 .yaml文件只能写静态的死字符串和数字,
python作为配置文件优势本来就很大,里面可以写if else,也可以调用各种函数,只要你的模块下包含那些变量就行了。
6.18.5 多个ptyhon项目怎么使用同一个funboost_config.py 作为配置文件
还是因为不懂 PYTHONPATH 造成的,需要我无数次举例说明。 这样太low了,这么多python人员到现在还不知道 PYTHONPATH作用, python导入一个模块是怎么去查找的。
6.18 开头就说了 pythonpathdemo 项目连接,有的人不懂PYTHONPATH又不看这个博客。死猪不怕开水烫,永远不学习 PYTHONPATH 的强大作用。
假设你想每隔项目都使用 /data/conf/funboost_config.py 这一个相同的 funboost_config 作为配置文件,
你有两个python项目在 /data/codes/proj1 和 /data/codes/proj2,
你运行proj1的项目脚本前,只需要 export PYTHONPATH=/data/conf/:/data/codes/proj1 ,然后运行proj1项中的脚本 python dir1/dir2/xx.py
你运行proj2的项目脚本前,只需要 export PYTHONPATH=/data/conf/:/data/codes/proj2 ,然后运行proj2项中的脚本 python dir3/dir4/yy.py
因为你设置了/data/conf/ 为 pythonpath后,那么funboost在 import funboost_config 时候就能自动 import 到 /data/conf/下的 funboost_config.py 模块了。
funboost控制台都打印了 读取的是什么文件作为配置文件了。
归根结底问这个问题的人是完全不懂 PYTHONPATH.
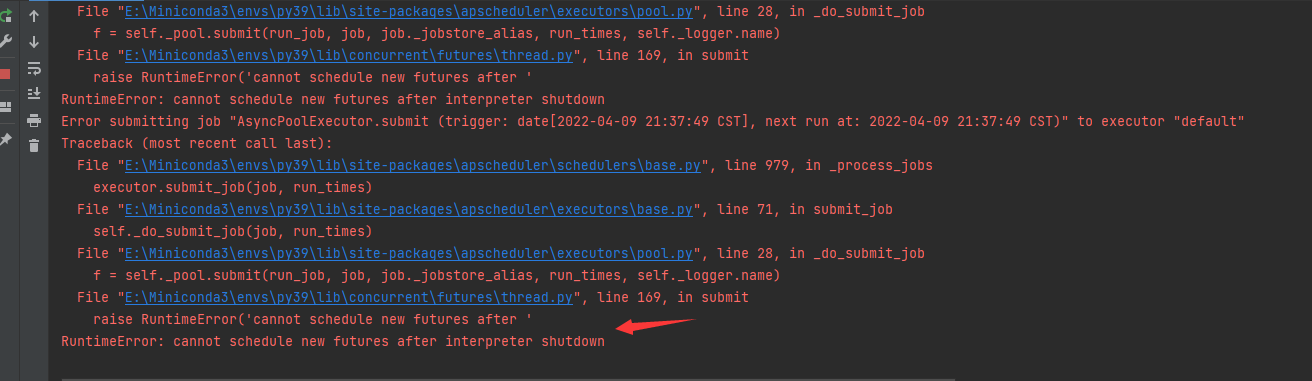
6.19 定时任务或延时任务报错 RuntimeError: cannot schedule new futures after interpreter shutdown
如下图所示,运行定时任务或延时任务在高版本python报错,可以在代码末尾加个while 1:time.sleep(10)
因为程序默认是 schedule_tasks_on_main_thread=False,为了方便连续启动多个消费者消费,
没有在主线程调度运行,自己在代码结尾加个不让主线程结束的代码就行了。
在消费启动的那个代码末尾加两行
while 1:
time.sleep(10)
6.21 支不支持redis cluster集群模式的redis作为消息队列?
funboost可以redis cluster集群。
框架支持kombu,支持 celery作为broker_kind。
阿里云分片集群,用户完全不用管是单机reids还是分片集群,代码连接方式一样。
6.22 怎么使用tcp socket 作为消息队列
见 4.35章节,或者在文档的搜索框输入 tcp 或者 socket 就能搜到了。
或者按照文档第14章节使用ai来帮你学习。
6.23 安装包时候自动安装的三方依赖包太多?
1.安装第三方包是自动的,又不需要手动一个个指令安装,安装多少三方包都没关系。
2.所有三方包加起来还不到30M,对硬盘体积无影响。
3.只要指定阿里云pip源安装,就能很快安装完,30秒以内就安装完了,又不是需要天天安装。
如果如你的不一致报错终端,pip 命令加上 --use-feature=2020-resolver
pip install funboost -i https://mirrors.aliyun.com/pypi/simple/
4.三方包与自己环境不一致问题?
用户完全可以自由选择任何三方包版本。例如你的 sqlalchemy pymongo等等与框架需要的版本不一致,你完全可以自由选择任何版本。
我开发时候实现了很多种中间件,没有时间长期对每一种中间件三方包的每个发布版本都做兼容测试,所以我固定死了。
用户完全可以选择自己的三方包版本,大胆点,等报错了再说,不出错怎么进步,不要怕代码报错,请大胆点升级你想用的版本。
如果是你是用你自己项目里面的requirements.txt方式自动安装三方包,我建议你在文件中第一行写上 funboost,之后再写其它包
这样就能使用你喜欢的版本覆盖funboost框架依赖的版本了。
等用的时候报错了再说。一般不会不兼容报错的请大胆点。
5.为什么要一次性安装完,而不是让用户自己用什么再安装什么?
是为了方便用户切换尝试各种中间件和各种功能时候,不需要自己再亲自一个个安装第三方包,那样手动一个个安装三方包简直是烦死了。
2024 5月份,精简了依赖包,部分包改为选装, pip install funboost[all] 才安装全部中间件.
6.23.b 作者为什么不开发pip 选装方式?例如实现选装 pip install funboost[rabbitmq]
这个你是怎么知道funboost作者没有使用选装方式的? 你是怎么知道作者没有掌握 pip 中括号选装依赖包 技术方式的?
用户可以看看setup.py里面的 extras_require里面,有没有开发选装方式? pip funboost[all] 才是安装所有依赖.
作者去掉依赖很容易,已经实现了, funboost/factories/broker_kind__publsiher_consumer_type_map.py 中的 regist_to_funboost 就是动态导入生产者消费者,很容易去掉各种三方包依赖,
但是很容易安装的三方包,我是不会去做成选装的,没有那个必要,自己设置pip 国内源,30秒就能安装完成funboost了,不需要去纠结这个依赖包多少的问题.
6.24 funboost框架从消息队列获取多少条消息?有没有负载均衡?
funboost 每个消费者进程会从消息队列获取 并发个数 n + 10 条消息,每个消费者实现有差异,一般不会超过并发数2倍。
所以不会造成发布10万条消息后,再a b机器启动2个消费,b机器一直无法消费,全部a机器消费,不会出现这种情况。
如果你只发布6条消息,先在a机器启动消费,下一秒启动b机器,那很有可能b机器无法获取到消息。只要消息数量够多,不会出现忙的忙死,闲的闲死。
例如框架的默认并发方式使线程池,内置了一个有10大小的界队列queue,同时还有n个并发线程正在运行消息,所以每个消费者会获取很多消息在python内存中。
但不会出现一个消费者进程获取了1000条以上的消息,导致站着某坑不拉屎,别的消费进程没办法消费的情况。
如果你是重型任务,希望不预取,每台机器只获取一条消息运行,可以设置并发模式为 SINGLE_THREAD 模式,
boost装饰器设置 concurrent_mode=ConcurrentModeEnum.SINGLE_THREAD,这样在a b 两台机器都没有内存缓冲队列,只会一次获取一条消息执行,
有的broker_kind实现时候为了运行快,框架使用了批量拉取消息, 需要设置批量拉取的数量为1。
消费文件 test_frame\test_redis_ack_able\test_load_balancing_consume.py
import logging
import time
from funboost import boost, BrokerEnum,BoosterParams,ctrl_c_recv,ConcurrentModeEnum
@boost(BoosterParams(queue_name='test_load_balancing', broker_kind=BrokerEnum.REDIS_ACK_ABLE, log_level=logging.INFO,
# 切记是设置concurrent_mode并发模式为 SINGLE_THREAD ,而不是使用线程池模式然后把 concurrent_num 设置为1,这两个在多进程拉取消息的绝对均衡方面有区别
# 因为即使线程池并发为1,线程池还有内部的work_queue会拉取缓冲一部分消息,导致出现你认为的多机器或多进程拉取消息不均衡
concurrent_mode=ConcurrentModeEnum.SINGLE_THREAD,
# pull_msg_batch_size 这行很关键,REDIS_ACK_ABLE 因为默认是拉取100个消息,
# 对于重型任务,如果你需要每台机器都严格只运行一个消息,就需要设置批量拉取1个消息,不要一台机器就把消息队列掏空了。
broker_exclusive_config={'pull_msg_batch_size': 1},
))
def test_load_balancing(x):
print(x)
time.sleep(1)
if __name__ == '__main__':
test_load_balancing.consume()
ctrl_c_recv()
发送消息文件 test_frame\test_redis_ack_able\test_load_balancing_consume.py
from test_frame.test_redis_ack_able.test_load_balancing_consume import test_load_balancing
if __name__ == '__main__':
for i in range(80):
test_load_balancing.push(i)
启动2次消费文件,就能看到2个控制台,每个控制台每次只获取1条消息并运行,如果你不设置 pull_msg_batch_size,那么默认是批量拉取100个,而你总共才发布80个消息
所以你只能看到一个控制台消费,你误以为没有负载均衡。
如果你不设置 pull_msg_batch_size,那么就可以发布5000个消息来测试消费负载均衡,两个控制台就都会运行,因为默认批量拉取100个也不会一下子把5000消息都取到内存。
6.25 funboost消费启动后,按ctrl + c 无法结束代码?
from funboost import ctrl_c_recv
if __name__ == '__main__':
# 启动消费
consume_func.consume()
ctrl_c_recv(confirmation_count=1) # 在代码最末未加个 ctrl_c_recv()
# 想结束代码就连续按 confirmation_count 次 ctrl +c 就好了。 为什么是 confirmation_count次,是防止你误操作了ctrl + c
6.25b ctrl_c_recv 到底要不要加?—— 直接看效果
win和linux表现不一样: linux 代码末尾不加ctrl_c_recv(),按ctrl +c 可以结束程序。win 不加ctrl_c_recv(),按ctrl +c 无法结束程序。
先给出正确的结论:
你即使程序最末尾不加 ctrl_c_recv(),funboost消费程序也会永久持续运行,控制台也会不断打印日志和 print 输出。
严禁认为 ctrl_c_recv() 的作用是“优雅退出”或“防止程序结束”。实际上,不加它程序也会一直运行 真实作用:在 Windows 下如果不加这行代码,按 Ctrl+C 无法停止程序。加上后即可正常。
很多开发者(包括一些AI)容易对 ctrl_c_recv 的作用产生两种误解:
误解一:以为不加
ctrl_c_recv,程序就会瞬间结束,根本不会消费消息。误解二:以为不加
ctrl_c_recv,脚本会自动变成nohup那样的后台任务,关掉终端窗口还能继续跑。
❌ 这些都是错误的!
6.25b.0 ctrl_c_rev的源码很简单,很容易看懂。
ctrl_c_recv 的源码非常简单,它不是“优雅退出”的实现——没有等待任务完成、没有清理资源、没有发送任何信号给工作线程或消息队列,funboost不需要优雅退出,是依靠mq本身的确认消费来防止丢消息。
def ctrl_c_recv(confirmation_count=1):
"""
程序最末尾加 ctrl_c_recv() 主要是为了主线程持续在运行,方便你在 windows系统下敲击键盘 ctrl + c 可以停止程序而已。
你即使程序最末尾不加 ctrl_c_recv(),funboost消费程序也会永久持续运行,控制台也会不断打印日志和 `print` 输出。
加与不加的详细区别,可以看教程6.25b章节 `## 6.25b `ctrl_c_recv` 到底要不要加?—— 直接看效果`
你也可以不用ctrl_c_recv(), 直接在你的启动脚本文件的最末尾加上:
while 1:
time.sleep(100)
也能达到主线程在持续运行的目的,从而在windows系统下敲击键盘 ctrl + c 可以停止程序。
"""
for i in range(confirmation_count):
while 1:
try:
time.sleep(2)
except (KeyboardInterrupt,) as e:
# time.sleep(2)
print(f'{type(e)} 你按了ctrl c ,程序退出, 第 {i + 1} 次', flush=True)
# time.sleep(2)
break
os._exit(44)
下面我们直接列出加与不加的真实效果,不涉及底层原理,只讲你实际能看到的现象。
6.25b.1 ✅ 情况A:代码末尾加了 ctrl_c_recv()
from funboost import ctrl_c_recv
task.consume() # 启动消费
ctrl_c_recv() # 末尾加上这一行
启动后:程序会持续一直运行,控制台会持续打印日志和
print输出。如果想停止:你只需在当前会话终端窗口,在键盘上按几次
Ctrl + C(默认是1次),程序就会立刻结束。关掉终端窗口:如果直接关闭终端窗口,程序也会随之结束(这是所有前台程序的默认行为)。
6.25b.2 ❌ 情况B:代码末尾没有加 ctrl_c_recv()
task.consume() # 启动消费
# 后面没有 ctrl_c_recv
启动后:程序同样会一直运行,控制台也会不断打印日志和
print输出。代码绝对不会瞬间结束!如果想停止:你在当前会话终端窗口,疯狂按
Ctrl + C毫无反应,程序完全不理你。怎么办:只能通过以下方式结束程序:
直接关闭整个终端窗口(窗口关闭会杀死所有前台进程)。
或者在另一个终端里用
kill -9命令杀死进程ID。
关掉终端窗口:如果直接关闭终端窗口,程序同样会结束,不会像
nohup那样在后台继续运行。
6.25b.3 效果对比表(一目了然)
你的操作 |
加 |
不加 |
加与不加是否有区别? |
|---|---|---|---|
启动脚本后 |
程序持续运行,控制台一直打印日志 |
程序同样持续运行,控制台一直打印日志 |
❌ 无区别 |
按 |
程序立即退出 |
毫无反应,程序继续运行 |
✅ 有区别 |
直接关掉终端窗口 |
程序随之结束 |
程序随之结束 |
❌ 无区别 |
是否像 |
❌ 否 |
❌ 否 |
❌ 无区别 |
6.25b.4 最终结论
不加
ctrl_c_recv()的最大坏处:你无法用Ctrl + C方便地停止程序,只能粗暴地关窗口或杀进程。既然程序无论如何都会一直运行,为什么不加上
ctrl_c_recv()给自己留一个方便的“停止开关”呢?
建议:在所有需要交互式停止的 Funboost 脚本末尾,都加上这一行。
6.25b.5 顺便说一下,文档中其他地方提到的 ctrl_c_recv 和 apscheduler 的定时器之间的关系
很多开发者(包括AI)会疑惑:文档其他地方说用定时任务时必须加 ctrl_c_recv() 或 while 1: time.sleep(10),否则会报错 RuntimeError: cannot schedule new futures after interpreter shutdown,但这里又说可以不加,到底哪个是对的?
其实答案很简单:取决于你用的 Funboost 版本。
6.25b.5.1 APScheduler 的两种原生定时器
众所周知,APScheduler 有两种常用定时器:
BlockingScheduler:阻塞型。调用start()后,代码会卡住不动,后续代码根本没有机会运行。BackgroundScheduler:非阻塞型。调用start()后,代码会继续往下执行,定时任务在守护线程中运行。
6.25b.5.2 早期版本(2025年之前)的问题
Funboost 早期为了能让用户连续写启动多个函数消费 fun_xx.consume() 和连续启动多个定时器 scheduler_xx.start() 而不阻塞,选择了继承 BackgroundScheduler 作为定时器基类。
原生的 BackgroundScheduler 有一个特点:它的工作线程是守护线程(_daemon=True)。
当你的脚本执行完所有代码,主线程结束后,守护线程会被 Python 强行终止。此时如果定时器正在尝试向线程池提交新任务,就会触发:
RuntimeError: cannot schedule new futures after interpreter shutdown
所以早期文档里才会反复强调:如果使用了定时任务,必须在脚本末尾加上 ctrl_c_recv() 或 while 1: time.sleep(10),让主线程一直活着,避免报错。
6.25b.5.3 2025年之后的改进
现在 FunboostBackgroundScheduler 已经重写了 _daemon 属性,显式将其设为 False。这意味着:
定时器工作线程变成了非守护线程。
即使主线程执行完毕,这些非守护线程也会让进程继续保持运行,不会触发上述报错。
所以从 2025 年以后的 Funboost 版本开始,即使你用了定时任务,也完全不需要加 ctrl_c_recv() 或 while 1: time.sleep(10),程序就能正常运行且不会报错。
6.25b.5.4 三种定时器的行为对比
定时器类型 |
是否阻塞 |
线程类型 |
不加 |
|---|---|---|---|
原生 |
阻塞 |
- |
|
原生 |
非阻塞 |
守护线程 |
主线程结束后,守护线程被强杀,会报 |
|
非阻塞 |
非守护线程 |
主线程结束后,非守护线程继续运行,不会报错 |
6.25b.5.5 总结
如果你用的是 2025年之后的 Funboost,使用定时任务时可以不加
ctrl_c_recv(),程序会一直运行,定时器也能正常工作。如果你用的是旧版本,或者不确定版本,建议还是加上
ctrl_c_recv()或while 1: time.sleep(10)保平安。当然,即使在新版本中,加上
ctrl_c_recv()也没有副作用,还能让你方便地用Ctrl + C停止程序,所以加上也没什么坏处。
6.26 ASYNC 并发模式,异步函数操作数据库/aiohttp连接池报错 attached to a different loop(是用户不看文档和boost的入参说明造成)
第一性原理:对于跨线程玩loop 协程,如果用户经常这样编程的一定遇到过这种经典的坑,遇到了才能使自己的asyncio loop知识更上一层楼;
如果一个pythoner,一直只在主线程玩一个loop,是很难真正掌握asyncio的知识的,尤其是不懂loop。使用指定的
specify_async_loop即可解决.
这个放在自问自答 6.26 章节有源码注释演示,太多人不看文档,不看boost装饰器的入参解释说明.不看specify_async_loop入参解释造成的.asyncio的经典报错
attached to a different loop和context manager should be used inside a task和attached to a different loop报错原因:
这个错误通常发生在 对象(如 Future、Task、协程)在一个事件循环中创建,却在另一个事件循环中被使用。RuntimeError: Timeout context manager should be used inside a task报错原因:
异步上下文管理器(如timeout)不在Task中运行很多人在async def消费函数中去操作http连接池 发请求,操作数据库连接池查询数据,在funboost中报错.
根本原因是用户不传递指定specify_async_loop, 如果不传递,funboost是独立线程中启动了一个新的loop,
用户的连接池绑定的是主线程的loop,如果使用子线程的新loop去使用这个连接池查询数据库,那就会导致报错.
只在主线程中操作asyncio协程的pythoner,永远无法理解这个知识点,需要用户多练习在子线程去操作数据库连接池或者http连接池,才能踩坑积累经验.
用户可以结合看4b.3章节
用户需要始终知道 ASYNC 并发模式 第一性原理,才知道怎么根本解决问题
切记切记,funboost 的 ASYNC 并发模式的核心底层原理, funboost,当用户使用 ASYNC 并发模式时候,是自动使用 AsyncPoolExecutor 来执行用户函数, AsyncPoolExecutor 源码在 funboost/concurrent_pool/async_pool_executor.py AsyncPoolExecutor 原理是启动了一个线程,这个线程会使用传递的specify_async_loop,如果不传递就会新创建1个loop, 这个loop会运行指定的 concurrent_num 个cron 协程,去运行用户的消费函数逻辑 也就是说AsyncPoolExecutor线程只有一个,loop只有一个,真正的一个loop并发运行cron协程 用 loop2 去运行 loop1 创建的task,不报错才怪
即使是funboost 的 thereding 并发模式也可以直接运行async def 函数,funboost对async的支持完爆celery
funboost 的 thereding 并发模式也可以直接@boost装饰加到async def 函数,
因为funboost是特制的神级别线程池,能自动运行async def 函数.
但这个模式下简单粗暴,会开启 concurrent_num 个线程,每个线程有自己的loop,去运行用户的async函数,
相当于是每个loop只并发运行一个cron协程,不是真asyncio级别并发
相当于是有无数线程,每个线程一个loop,去运行用户的async函数
funboost的 thereding 并发模式运行async,就是celery 任务中强行使用 asyncio.new_event_loop().run_until_complete(async函数)
但是funboost是特制的神级别线程池 FlexibleThreadPool,这个线程池自动可以运行async def 函数,
无需用户为了运行async def 函数,去手写一个脱了裤子放屁的 同步def 函数,
也就是用户无需这种脱了裤子放屁的写法:
@boost(BoosterParams(queue_name='test_async_queue2', concurrent_mode=ConcurrentModeEnum.THREADING))
def 同步fun(x,y)
asyncio.new_event_loop().run_until_complete(async异步函数(x,y)) #同步里面调用异步函数
用户可以直接使用THREADING 并发模式加到 async def async异步函数:
@boost(BoosterParams(queue_name='test_async_queue2', concurrent_mode=ConcurrentModeEnum.THREADING))
async def async异步函数(x,y)
pass
celery的运行协程才需要脱落裤子放屁再加个同步函数里面run_until_complete调用异步函数,才能@app.task
6.26.1 演示aiohttp连接池,解决报错 RuntimeError: context manager should be used inside a task
演示aiohttp连接池,解决报错代码如下,用户需要看里面的每个代码注释.
"""
此脚本主要是演示,在funboost自动的单独的子线程的loop中,如何使用asyncio的异步socket池,来发送异步请求。
核心是要把主线程的loop传递到子线程中,让子线程和主线程使用同一个loop来运行异步函数,
在funboost 中 通过 specify_async_loop=主线程loop 来传递.
跨线程的不同loop,使用在主线程的loop生成的异步连接池 来发请求是不行的.
不管是任何三方包的socket池,例如 aiomysql aioredis aiohttp httpx 创建的http或者数据库连接池,
都不能在子线程的loop的异步函数中直接去使用这个连接池中的连接发请求.
有些异步三方包的连接池能直接在子线程的loop去使用连接发请求或查询数据库而不报错,是因为惰性生成的.
"""
"""
用户一定要搞清楚 线程和loop的绑定关系
一定要知道为什么不同的loop,不能操作同一个异步连接池发请求或者查询数据库.
用户一定要多写子线程的loop调用连接池发请求测试demo,这个和funboost本身无关,
用户的asyncio知识体系太差,用户只会在主线程使用loop,导致对loop和线程绑定关系不懂,对不同loop操作一个连接池不懂.
在子线程运行异步函数的loop,比在主线程的loop运行难得多,坑也更多.用户需要多写demo例子测试练习,多问ai大模型.
"""
# 例如子线程的loop去使用主线程loop绑定的http连接池发请求,会报错如下. 数据库连接池同理也会报错.
"""
Traceback (most recent call last):
File "D:\codes\funboost\funboost\consumers\base_consumer.py", line 929, in _async_run_consuming_function_with_confirm_and_retry
rs = await corotinue_obj
File "D:\codes\funboost\test_frame\test_async_consumer\test_child_thread_loop_use_asyncio_sokcet_pool.py", line 64, in async_f2
async with ss.request('get', url=url) as resp: # 如果是这样请求,boost装饰器必须指定specify_async_loop,
File "D:\ProgramData\Miniconda3\envs\py39b\lib\site-packages\aiohttp\client.py", line 1425, in __aenter__
self._resp: _RetType = await self._coro
File "D:\ProgramData\Miniconda3\envs\py39b\lib\site-packages\aiohttp\client.py", line 607, in _request
with timer:
File "D:\ProgramData\Miniconda3\envs\py39b\lib\site-packages\aiohttp\helpers.py", line 636, in __enter__
raise RuntimeError("Timeout context manager should be used inside a task")
RuntimeError: Timeout context manager should be used inside a task
"""
from funboost import boost, BrokerEnum,ConcurrentModeEnum,ctrl_c_recv
import asyncio
import aiohttp
import time
url = 'http://mini.eastday.com/assets/v1/js/search_word.js'
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop) # 这是重点,设置主线程默认的loop 为你创建的loop
# 这是重点,ss和主线程的loop绑定了. # 新版本aiohttp必须放在协程函数中去实例化,不能全局变量实例化,参考下面的 aiomysql
ss = aiohttp.ClientSession(loop=loop)
@boost(BoosterParams(queue_name='test_async_queue1', concurrent_mode=ConcurrentModeEnum.ASYNC, broker_kind=BrokerEnum.REDIS,
log_level=10,concurrent_num=3,
specify_async_loop=loop, # specify_async_loop传参是核心灵魂代码,不传这个还要使用主loop绑定的连接池就会报错.
is_auto_start_specify_async_loop_in_child_thread=False,
))
async def async_f1(x):
"""
这个函数是自动被funboost在一个单独的子线程中的loop运行的,loop会并发运行很多协程来执行async_f1的逻辑
用户最最需要明白的是,在用funboost的 ConcurrentModeEnum.ASYNC时候,你不是在主线程中操作的异步函数,而是子线程的loop中调用的.
假设如果是在主线程中去运行的,你怎么可能连续丝滑启动多个函数消费 f1.consume() f2.consume() f3.consume() ? 用脑子想想就知道不是主线程去调用异步函数的.
"""
# 如果是async with ss.request('get', url=url)使用主线程loop的连接池发请求,boost装饰器必须指定 specify_async_loop,
# 如果你不使用ss连接池,而是 async with aiohttp.request('GET', 'https://httpbin.org/get') as resp: 那就不需要指定 specify_async_loop
async with ss.request('get', url=url) as resp:
text = await resp.text()
print('async_f1', x, resp.url, text[:10])
await asyncio.sleep(5)
return x
@boost(BoosterParams(queue_name='test_async_queue2', concurrent_mode=ConcurrentModeEnum.ASYNC, broker_kind=BrokerEnum.REDIS,
log_level=10,concurrent_num=3,
# specify_async_loop=loop, # specify_async_loop传参是核心灵魂代码,连接池不传这个还要使用主loop绑定的连接池就会报错.
is_auto_start_specify_async_loop_in_child_thread=False,
))
async def async_f2(x):
# 如果是async with ss.request('get', url=url)使用主线程loop的连接池发请求,boost装饰器必须指定 specify_async_loop,
# 如果你不使用ss连接池,而是 async with aiohttp.request('GET', 'https://httpbin.org/get') as resp: 那就不需要指定 specify_async_loop
async with aiohttp.request('get', url=url) as resp:
text = await resp.text()
print('async_f2', x, resp.url, text[:10])
await asyncio.sleep(5)
return x
async def do_req(i):
async with ss.request('get', url=url) as resp: # 如果是这样请求,boost装饰器必须指定specify_async_loop,
text = await resp.text()
print(f'主线程的loop运行的{i}:',text[:10])
await asyncio.sleep(3)
if __name__ == '__main__':
async_f1.clear()
async_f2.clear()
for i in range(10):
async_f1.push(i)
async_f2.push(i*10)
async_f1.consume()
async_f2.consume()
# time.sleep(5) 加这个是测试主线程的loop和子线程loop谁先启动,造成的影响,如果子线程的specify_async_loop先启动,主线程下面的 loop.run_forever() 会报错已启动 RuntimeError: This event loop is already running
main_tasks = [loop.create_task(do_req(i)) for i in range(20)]
loop.run_forever() # 如果你除了要在funboost运行异步函数,也要在自己脚本调用,那么装饰器配置 is_auto_start_specify_async_loop_in_child_thread=False,,自己手动 启动loop.run_forever()
ctrl_c_recv()
如果消费async def的消费函数中:
如果是async with ss.request('get', url=url)使用主线程loop的连接池发请求,boost装饰器必须指定 specify_async_loop,
如果你不使用ss连接池,而是 async with aiohttp.request('GET', 'https://httpbin.org/get') as resp: 那就不需要指定 specify_async_loop
用户一定要好好体会下原因,为什么会这样,才能更懂asyncio
6.26.2 演示 aiomysql 连接池在funboost使用,解决 attached to a different loop
用户需要认真看代码里面的文字注释,为什么出现 attached to a different loop 经典报错
代码例子:
"""
此脚本演示, funboost的子线程的loop中怎么操作aiomysql 连接池.
演示了2种方式使用aiomysql连接池
方式一:
非常推荐方式一
async_aiomysql_f1 使用主线程的连接池,.
核心灵魂代码是 async_aiomysql_f1 的装饰器需要传参specify_async_loop=主线程loop
如果 async_aiomysql_f1 不指定specify_async_loop,就会出现经典报错 attached to a different loop ,
子线程的loop去操作主线程loop的连接池,这是大错特错的.
有的人压根不懂主线程loop和子线程loop,还非要装逼使用asyncio编程生态,
不精通asyncio编程生态的人应该老老实实使用同步多线程编程生态,简单多了.
因为funboost的线程池 FlexibleThreadPool能自动扩缩,
能自动缩容是吊打内置线程池 concurrent.futures.threadpoolexecutor的神级别操作,
FlexibleThreadPool 性能比官方内置线程池提高了250%
-----------------------------------------------------------------------
方式2:
不推荐方式2,浪费连接池宝贵资源。
async_aiomysql_f2_use_thread_local_aio_mysql_pool 使用 thread local 级别的全局变量连接池
这样子线程的loop避免了操作主线程loop的aiomysql连接池, 不会出现张冠李戴 attached to a different loop
"""
import threading
from funboost import boost, BrokerEnum, ConcurrentModeEnum, ctrl_c_recv, BoosterParams
import asyncio
import time
import aiomysql
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop) # 这是重点
DB_CONFIG = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': '123456',
'db': 'testdb',
'charset': 'utf8mb4',
'autocommit': True
}
g_aiomysql_pool : aiomysql.Pool
async def create_pool():
pool = await aiomysql.create_pool(**DB_CONFIG, minsize=1, maxsize=10,) # 这些是重点.
global g_aiomysql_pool
g_aiomysql_pool = pool
return pool
# 如果 async_aiomysql_f1 不指定specify_async_loop,就会出现经典报错 attached to a different loop ,子线程的loop去操作主线程loop的连接池
r"""
Traceback (most recent call last):
File "D:\codes\funboost\test_frame\test_async_consumer\test_child_thread_loop_aiomysql_pool.py", line 46, in async_aiomysql_f1
await cur.execute("SELECT now()")
File "D:\ProgramData\Miniconda3\envs\py39b\lib\site-packages\aiomysql\cursors.py", line 239, in execute
await self._query(query)
File "D:\ProgramData\Miniconda3\envs\py39b\lib\site-packages\aiomysql\cursors.py", line 457, in _query
await conn.query(q)
File "D:\ProgramData\Miniconda3\envs\py39b\lib\site-packages\aiomysql\connection.py", line 469, in query
await self._read_query_result(unbuffered=unbuffered)
File "D:\ProgramData\Miniconda3\envs\py39b\lib\site-packages\aiomysql\connection.py", line 683, in _read_query_result
await result.read()
File "D:\ProgramData\Miniconda3\envs\py39b\lib\site-packages\aiomysql\connection.py", line 1164, in read
first_packet = await self.connection._read_packet()
File "D:\ProgramData\Miniconda3\envs\py39b\lib\site-packages\aiomysql\connection.py", line 609, in _read_packet
packet_header = await self._read_bytes(4)
File "D:\ProgramData\Miniconda3\envs\py39b\lib\site-packages\aiomysql\connection.py", line 657, in _read_bytes
data = await self._reader.readexactly(num_bytes)
File "D:\ProgramData\Miniconda3\envs\py39b\lib\asyncio\streams.py", line 723, in readexactly
await self._wait_for_data('readexactly')
File "D:\ProgramData\Miniconda3\envs\py39b\lib\asyncio\streams.py", line 517, in _wait_for_data
await self._waiter
RuntimeError: Task <Task pending name='Task-2' coro=<AsyncPoolExecutor._consume() running at D:\codes\funboost\funboost\concurrent_pool\async_pool_executor.py:110>> got Future <Future pending> attached to a different loop
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\codes\funboost\funboost\consumers\base_consumer.py", line 929, in _async_run_consuming_function_with_confirm_and_retry
rs = await corotinue_obj
File "D:\codes\funboost\test_frame\test_async_consumer\test_child_thread_loop_aiomysql_pool.py", line 48, in async_aiomysql_f1
print(res)
File "D:\ProgramData\Miniconda3\envs\py39b\lib\site-packages\aiomysql\utils.py", line 139, in __aexit__
await self._pool.release(self._conn)
RuntimeError: Task <Task pending name='Task-2' coro=<AsyncPoolExecutor._consume() running at D:\codes\funboost\funboost\concurrent_pool\async_pool_executor.py:110>> got Future <Task pending name='Task-22' coro=<Pool._wakeup() running at D:\ProgramData\Miniconda3\envs\py39b\lib\site-packages\aiomysql\pool.py:203>> attached to a different loop
"""
"""
方式一:
消费函数使用全局g_aiomysql连接池,每个线程都使用主线程的loop来使用连接池查询,所以@boost需要指定specify_async_loop为主线程的loop
"""
@boost(BoosterParams(queue_name='async_aiomysql_f1_queue', concurrent_mode=ConcurrentModeEnum.ASYNC, broker_kind=BrokerEnum.REDIS,
log_level=10,concurrent_num=3,
specify_async_loop=loop, # specify_async_loop传参是核心灵魂代码,不传这个还要使用主loop绑定的连接池就会报错.
is_auto_start_specify_async_loop_in_child_thread=True,
))
async def async_aiomysql_f1(x):
await asyncio.sleep(5)
async with g_aiomysql_pool.acquire() as conn:
async with conn.cursor() as cur:
await cur.execute("SELECT now()")
res = await cur.fetchall()
print(res)
"""
方式二:
消费函数使用thread_local线程级别全局变量,每个消费函数的那个子线程的loop使用的是线程级别自己的连接池,
这样就避免了子线程的loop去用 主线程绑定的aiomysqlpool查询数据库,导致报错
强烈不推荐方式二,这会给每个消费函数创建一个mysql 连接池,
因为如果不显式传递specify_async_loop,默认是每个booster用一个单独的线程启动loop,每个消费函数有自己的loop,浪费mysql连接数量的宝贵资源。
你的booster消费函数越多越不利于mysql连接池复用。
"""
thread_local = threading.local()
async def create_pool_thread_local():
if hasattr(thread_local, 'aiomysql_pool'):
return thread_local.aiomysql_pool
pool = await aiomysql.create_pool(**DB_CONFIG, minsize=1, maxsize=5, ) # 这些是重点.
setattr(thread_local, 'aiomysql_pool', pool)
print('创建了线程级别 threadlocal的 aiomysql连接池')
return pool
@boost(BoosterParams(queue_name='async_aiomysql_f2_queue', concurrent_mode=ConcurrentModeEnum.ASYNC, broker_kind=BrokerEnum.REDIS,
log_level=10,concurrent_num=3,
# specify_async_loop=loop, # specify_async_loop 不需要传递,因为子线程的loop有自己的pool,不使用主线程的pool去查数据库
is_auto_start_specify_async_loop_in_child_thread=True,
))
async def async_aiomysql_f2_use_thread_local_aio_mysql_pool(x):
await asyncio.sleep(5)
aiomysql_pool_thread_local = await create_pool_thread_local()
async with aiomysql_pool_thread_local.acquire() as conn:
async with conn.cursor() as cur:
await cur.execute("SELECT now()")
res = await cur.fetchall()
print(res)
if __name__ == '__main__':
loop.run_until_complete(create_pool()) # 先创建pool,aiomysql的pool不能直接在模块级全局变量直接生成.
async_aiomysql_f1.clear()
async_aiomysql_f2_use_thread_local_aio_mysql_pool.clear()
for i in range(10):
async_aiomysql_f1.push(i)
async_aiomysql_f2_use_thread_local_aio_mysql_pool.push(i*10)
async_aiomysql_f1.consume()
async_aiomysql_f2_use_thread_local_aio_mysql_pool.consume()
ctrl_c_recv()
6.26.3 演示子线程怎么正确的使用aiomysql连接池的本质(和funboost无关但原理相通)
有些人报错 RuntimeError: attached to a different loop,以为是 funboost的bug,其实是因为压根不懂asyncio的loop知识.
下面这个代码没有使用funboost来消费async 函数,和funboost原理一样,子线程操作主线程的异步连接池
"""
演示子线程中的loop怎么正确操作 异步aio连接池
正解就是子线程要使用 asyncio.run_coroutine_threadsafe(aio_do_select(1), 主线程的loop)
错误做法就是,子线程生成自己的loop,却用主线程的aio连接池查询数据库,造成经典错误 RuntimeError: attached to a different loop
funboost的 AsyncPoolExecutor 就是在子线程运行的loop ,需要懂这个例子,才知道为什么操作aio连接池时候, funboost装饰器为什么要把主loop传给 specify_async_loop
"""
import threading
import asyncio
import time
import aiomysql
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop) # 这是重点
DB_CONFIG = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': '123456',
'db': 'testdb',
'charset': 'utf8mb4',
'autocommit': True
}
g_aiomysql_pool : aiomysql.Pool
async def create_pool():
print(f'主线程 threading id: {threading.get_ident()}')
pool = await aiomysql.create_pool(**DB_CONFIG, minsize=1, maxsize=10,) # 这些是重点.
global g_aiomysql_pool
g_aiomysql_pool = pool
return pool
async def aio_do_select(i):
async with g_aiomysql_pool.acquire() as conn:
async with conn.cursor() as cur:
await cur.execute("SELECT now()")
res = await cur.fetchall()
print(res)
def run_do_select_in_child_thread(loopx:asyncio.AbstractEventLoop):
""" 查询数据库正确的做法,
使用主线程的loop去查数据库.
"""
print(f'子线程 threading id: {threading.get_ident()}')
asyncio.run_coroutine_threadsafe(aio_do_select(1), loopx) # 这是正解
def run_do_select_in_child_thread_error():
"""查询数据库错误的写法, 用子线程自己的loop去调用 主线程loop绑定的g_aiomysql_pool,
造成经典错误 RuntimeError: attached to a different loop
"""
print(f'子线程 threading id: {threading.get_ident()}')
loop = asyncio.new_event_loop()
loop.run_until_complete(aio_do_select(1))
if __name__ == '__main__':
loop.run_until_complete(create_pool())
threading.Thread(target=run_do_select_in_child_thread, args=(loop,)).start()
threading.Thread(target=run_do_select_in_child_thread_error, ).start()
loop.run_forever()
6.28 日志提示 是掉线或关闭消费者的 和 重新放入掉线消费者未消费确认的任务 ,是正常的提示.
例如提示下面,是完全正常的,是确认消费功能的 重回孤儿消息.
2025-08-18 12:37:19-(10.0.133.57,LAPTOP-7V78BBO2)-[p58428_t59904] - funboost.RedisConsumerAckAble--test_cost_long_time_fun_queue888 - "confirm_mixin.py:83" - _requeue_tasks_which_unconfirmed - WARNING - no_task_id - test_cost_long_time_fun_queue888__unack_id_LAPTOP-7V78BBO2_10.0.133.57_2025-08-18 12-36-02_46752_2024011500368 是掉线或关闭消费者的
2025-08-18 12:37:19-(10.0.133.57,LAPTOP-7V78BBO2)-[p58428_t59904] - funboost.RedisConsumerAckAble--test_cost_long_time_fun_queue888 - "confirm_mixin.py:87" - _requeue_tasks_which_unconfirmed - WARNING - no_task_id - 从 test_cost_long_time_fun_queue888__unack_id_LAPTOP-7V78BBO2_10.0.133.57_2025-08-18 12-36-02_46752_2024011500368 向 test_cost_long_time_fun_queue888 重新放入掉线消费者未消费确认的任务 {"x":666,"extra":{"task_id":"test_cost_long_time_fun_queue888_result:7ff6270e-5669-4ee4-8c48-d5b9ba39e3d9","publish_time":1755491762.9382,"publish_time_format":"2025-08-18 12:36:02"}}
在在选择redis可确认消息的(非BrokerEnum.REDIS)中间件时候,
例如你应该几把脚本反复部署启动2次kill了其中一个,或者即使只有一个脚本,但是重启后,就会提示这样啊,这是提示把之前kill的消费者进程所持有的待确认消费的消息,重回工作队列, 确保只有确认消费的消息才会真的不再次被调度运行.
那些运行到一半的函数消息和内存中缓存的一部分消息,在kill后,都会被重回消息队列.
用户如果不需要确认消费功能,就使用 BrokerEnum.REDIS 模式,这个是no ack 模式.
以下redis并发模式都是need ack 确认消费的,消息从队列取出来后,只要消息没确认消费,进程被关闭后,孤儿消息下次还会被重回队列
REDIS_ACK_ABLE
REIDS_ACK_USING_TIMEOUT
REDIS_PRIORITY
REDIS_STREAM
RedisBrpopLpush
这些在 BrokerEnum 源码注释中 以及 教程文档中反复说了无数次,用户太懒了不看
6.29 funboost 推荐用户使用什么并发模式?
在 Funboost 中,并发模式的选择并非一道选择题,而是一套层层递进的“性能方程式”。框架提供了多种模式,但在 99% 的情况下,你只需要遵循以下推荐原则即可。
6.29.1 默认推荐:当前进程内 + 多线程模式 (最省心、最稳定、最好用)
适用场景:绝大多数的常规后端任务,如 API 请求、爬虫、写数据库、发送邮件等 IO 密集型操作。
使用方式:什么都不用改。@boost 的 concurrent_mode 默认就是 ConcurrentModeEnum.THREADING,直接 task_fun.consume() 启动即可。
为什么这是最推荐的模式?
因为在这个模式下,支撑并发的底层不是 Python 官方自带的 concurrent.futures.ThreadPoolExecutor,而是 Funboost 作者纯手工打造的神级线程池:FlexibleThreadPool(智能弹性线程池)。
它吊打官方原生线程池的核心优势在于:
自动智能缩容:官方线程池是“只进不出”的貔貅,无论任务多么稀疏,官方线程池会盲目增加到最大线程数;并且后来长期没啥任务了,线程也一直挂在内存里。而
FlexibleThreadPool引入了KeepAliveTime机制,在任务稀疏时会自动销毁多余线程,释放系统资源。极度克制的扩张:哪怕你配置了
concurrent_num=500,如果你的任务很稀疏,它就绝对不会去新开不必要的线程。兼容
async def函数:你可以直接把@boost(concurrent_mode=THREADING)加在异步函数上!框架会自动在线程池的每个线程里启动临时的 event loop 来运行协程,免去了你手动改写同步包装函数的痛苦(这一点完爆 Celery)。
一句话总结:这是兼顾了“极低心智负担”与“极高 IO 吞吐”的王牌模式。
6.29.2 高性能推荐:多进程叠加并发模式 (性能炸裂)
适用场景:
CPU 密集型任务(如视频转码、图像处理、复杂数学计算),需要突破 Python 的 GIL 锁。
超高并发的 IO 任务,单进程的线程数开到极限依然无法满足吞吐需求。
使用方式:
不要去修改 @boost 装饰器里的 concurrent_mode(依然保持默认的多线程)。而是在启动消费时,使用 task_fun.multi_process_consume(n) (可简写为 task_fun.mp_consume(n))。
核心原理:
这是 Funboost 的特色“叠加态”并发。例如执行 task_fun.mp_consume(4):
框架会先利用操作系统的多进程(Process)开出 4 个独立的 Worker 进程(完美利用 4 核 CPU)。
在每个进程内部,依然使用
FlexibleThreadPool开启比如 100 个多线程。总并发能力 = 4 进程 × 100 线程 = 400 个并发单元。
为什么不直接用纯多进程模式? 如果不开线程,纯靠开 400 个进程去应对并发,操作系统的内存会瞬间被撑爆,而且进程切换的开销极大。Funboost 的“少量进程 + 海量线程”模式,是用最低廉的内存代价,榨干机器性能的最佳实践。
6.29.2.2 ⚠️ 极度重要:多进程在 Linux 上建议显式设置 spawn 模式,抛弃默认的 fork 模式
多进程下,spawn 模式相比 fork 模式,在“环境一致性”和“避免内存污染”上有巨大优势。
如果你使用了多进程叠加并发,强烈建议在你的启动脚本最顶端加上以下代码:
import multiprocessing
multiprocessing.set_start_method('spawn', force=True)
为什么 Funboost 强烈推崇 spawn 而嫌弃 fork?
优势 |
核心要点 |
|---|---|
环境一致性 |
Windows 只有 |
架构先进性 |
Funboost "少量进程 + 海量线程"理念,不需要为了启动快而牺牲安全性 |
内存纯粹性 |
|
开发体验 |
消灭 |
调试友好 |
|
详细说明:
抹平开发与生产的环境差异 Windows 只有
spawn模式,而 Linux 默认是fork。如果你在 Linux 不显式设置spawn,你的代码在 Windows 开发机和 Linux 生产机上的行为将不一致,极易让新手陷入"在我电脑上明明跑得好好的"的懵逼困境。拒绝 Celery 的历史包袱 Celery 默认是纯多进程模式,且无法叠加细粒度并发(不能进程套线程),所以它为了启动快而依赖
fork。但 Funboost 理念是"少量进程 + 海量线程",进程启动的极小开销完全可以忽略,根本不需要为了图快去用fork。保持内存纯粹,消灭僵尸连接
fork是"克隆"父进程的内存(包括父进程已经建立的数据库连接池、线程锁等)。这会导致子进程在查询数据库时发生经典的MySQL Server has gone away报错或死锁。💡 一句话理解:用
spawn启动 4 个进程,就等于你在控制台手动敲了 4 次python xx.py。每个进程重新执行一遍初始化代码,互不干扰。消灭反人类的钩子函数 正因为 Celery 饱受
fork内存污染的折磨,才被迫发明了@worker_process_init这种极其操蛋的钩子,强迫小白去学习"如何在这个钩子里重新初始化数据库连接"。在 Funboost +spawn的世界里,这种恶心的问题从物理层面上就被消灭了。更好的错误追踪和调试体验
fork的子进程会继承父进程的所有内存状态,包括异常状态、信号处理器等。当子进程出现问题时,你很难定位是父进程继承来的"遗传病"还是子进程自己产生的"新病"。 而spawn是全新的 Python 解释器进程,每次启动都是干净的 slate,错误堆栈清晰可溯,调试时不会被父进程的"历史包袱"干扰。
6.29.3 极客推荐:纯 Asyncio 协程模式 (高手的玩具)
适用场景:
你是一个重度的 asyncio 玩家,你的项目已经全面拥抱了异步生态(如使用 FastAPI),并且你在消费函数中必须使用 aiohttp、aiomysql、aioredis 等异步连接池。
使用方式:
必须在 @boost 中显式指定:
@boost(BoosterParams(
queue_name='my_queue',
concurrent_mode=ConcurrentModeEnum.ASYNC,
specify_async_loop=my_main_loop # 强烈建议阅读 6.26 章节,懂这个参数的才是真懂 asyncio
))
async def my_task(x):
pass
为什么普通人不推荐用纯 ASYNC 模式? 因为 asyncio 在 Python 中是一把“双刃剑”。
一旦你选择了 ASYNC 模式,你的函数里就绝对不能出现任何阻塞的同步代码(比如普通的
requests.get或time.sleep),否则整个 Event Loop 都会被卡死,并发瞬间变成串行,引发灭顶之灾。更要命的是“跨线程使用 Loop”的经典大坑(即抛出
attached to a different loop错误)。如果你不懂得如何把主线程的数据库连接池通过specify_async_loop传递给 Funboost 子线程的 Loop(详见文档 6.26 章节),你会死得很惨。
总结:如果你没经过系统的 asyncio 毒打,老老实实用 6.29.1 的多线程模式就好。
6.29.4 特殊场景:单线程串行模式 (Single Thread)
适用场景:
极度排斥并发冲突的任务:你的任务绝对不能并发执行,比如按严格顺序更新某一行数据库记录,或者操作某个不支持并发的本地文件/老旧系统。
要求“绝对公平”的跨机器负载均衡:你的服务绝对不能容忍“预先从 Broker 抢一堆消息缓冲在内存里”,必须保证多台机器公平、按需地抢夺消费机会。
使用方式:
@boost(BoosterParams(
queue_name='my_queue',
concurrent_mode=ConcurrentModeEnum.SINGLE_THREAD
))
def my_task(x):
pass
⚠️ 深度辨析:SINGLE_THREAD 和 THREADING + concurrent_num=1 是一回事吗?
绝对不是!这是两个完全不同的物种。
THREADING模式(即使你设置了concurrent_num=1): 底层依然会启动FlexibleThreadPool。只要有线程池,就会存在一个内存缓冲队列(_work_queue)。这意味着主消费线程会贪婪地从 Broker(如 Redis)中疯狂拉取几十上百条消息,囤积到自己进程的内存里,然后再由那 1 个工作线程慢慢消化。 后果:如果你部署了 A、B 两台机器,A 机器可能瞬间把队列里的 50 条消息全抢到了自己的内存里,导致 B 机器在一旁无所事事(闲死),而 A 机器却要花很久才处理完(忙死),彻底破坏了多机的负载均衡。SINGLE_THREAD模式: 框架没有线程池缓冲队列!它会极其克制、死板地执行:去 Broker 拉取 1 条消息 -> 执行完毕 ->再去 Broker 拉取下 1 条消息。 后果:无论你部署多少台机器,大家全凭手速,做完一个拿一个,绝不超售囤货,实现了绝对公平的分布式多机负载均衡。稳如老狗。
6.29.5 至于 gevent 和 eventlet 并发模式,直接忽略就好
虽然 funboost 并发模式支持了 gevent 和 eventlet,但不推荐使用,你没有必要研究它们。
6.30 funboost 如何实配置触发失败告警和恢复告警
funboost 提供了多种灵活的失败告警方式,满足从业务级即时通知到运维级聚合监控的不同需求。以下介绍5种常用方案。
6.30.1 使用内置告警 Mixin(AlertNotifier)
适用场景:当消费函数连续失败次数或错误率超过阈值时,实时发送钉钉、企业微信、飞书或自定义 Webhook 告警。
实现原理:通过
AlertNotifierConsumerMixin拦截任务执行结果,基于“连续失败计数”或“滑动窗口错误率”策略触发告警,并提供去重机制和恢复通知。配置方式:推荐使用预配置的
AlertNotifierBoosterParams,只需在user_options中填写alert_options参数。告警渠道支持 企业微信 钉钉 飞书,只需要提供webhook
详细参数说明见 funboost/contrib/override_publisher_consumer_cls/alert_notifier_mixin.py 。
6.30.1 AlertNotifierConsumerMixin 发送警告到 微信 钉钉 飞书
from funboost import boost, BrokerEnum
from funboost.contrib.override_publisher_consumer_cls.alert_notifier_mixin import AlertNotifierBoosterParams
@boost(AlertNotifierBoosterParams(
queue_name='my_task',
broker_kind=BrokerEnum.REDIS,
user_options={
'alert_options': {
'strategy': 'consecutive', # 连续失败策略
'failure_threshold': 5, # 连续失败5次触发
'alert_app': 'wechat', # 企业微信机器人
'webhook_url': 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxx',
'alert_interval': 300, # 5分钟内不重复告警
}
}
))
def my_task(x):
# 业务逻辑
...
6.30.1 AlertNotifierConsumerMixin 发送警告到任意渠道
用户自定义告警发送钩子,当 alert_app='custom' 时自动调用。
继承 AlertNotifierConsumerMixin 并重写此方法,可实现任意告警方式(邮件、短信、企业内部系统等)。
class EmailAlertConsumer(AlertNotifierConsumerMixin):
def custom_send_notification(self, message: str):
send_email(to='ops@example.com', subject='任务告警', body=message)
@boost(BoosterParams(
queue_name='my_task',
consumer_override_cls=EmailAlertConsumer,
user_options={'alert_options': {'alert_app': 'custom', 'failure_threshold': 5}},
))
def my_task(x):
...
6.30.2 通过熔断器钩子自定义告警
适用场景:当熔断器状态变化(例如由 CLOSED 变为 OPEN 或从 OPEN 恢复)时,执行自定义告警逻辑。
实现原理:继承
CircuitBreakerConsumerMixin,重写_on_circuit_open(熔断触发)和_on_circuit_close(熔断恢复)钩子方法,在其中调用你想要的告警接口。配置方式:创建自定义 Mixin 类,并在
consumer_override_cls中指定。
from funboost import boost, BoosterParams
from funboost.contrib.override_publisher_consumer_cls.circuit_breaker_mixin import CircuitBreakerConsumerMixin
class MyCircuitBreakerWithAlert(CircuitBreakerConsumerMixin):
def _on_circuit_open(self, info_dict):
# 发送钉钉告警
send_dingtalk(f"队列 {info_dict['queue_name']} 已熔断!失败次数:{info_dict['failure_count']}")
def _on_circuit_close(self, info_dict):
send_dingtalk(f"队列 {info_dict['queue_name']} 已恢复")
@boost(BoosterParams(
queue_name='my_task',
consumer_override_cls=MyCircuitBreakerWithAlert,
user_options={
'circuit_breaker_options': {
'failure_threshold': 5,
'recovery_timeout': 60,
}
}
))
def my_task(x):
...
熔断器配置详解见文档 4b.14 节及 circuit_breaker_mixin.py。
6.30.3 基于 Prometheus 指标 + Grafana 告警
适用场景:需要聚合监控所有任务的失败率、队列积压等指标,并通过 Grafana 设置告警规则,适合运维监控大屏。
实现原理:funboost 通过
PrometheusBoosterParams(单进程)或PrometheusPushGatewayBoosterParams(多进程)将任务指标(funboost_task_total、funboost_queue_msg_count等)暴露给 Prometheus,然后在 Grafana 中配置告警。配置方式:在消费函数上使用 Prometheus 参数类,并启动指标采集服务。
from funboost import boost
from funboost.contrib.override_publisher_consumer_cls.funboost_promethus_mixin import (
PrometheusPushGatewayBoosterParams,
)
@boost(PrometheusPushGatewayBoosterParams(
queue_name='my_task',
user_options={
'prometheus_pushgateway_url': 'localhost:9091',
'prometheus_job_name': 'my_app',
'prometheus_push_interval': 10.0,
}
))
def my_task(x):
...
启动后,Prometheus 收集到指标,你可以在 Grafana 中创建告警规则,例如:
失败率告警:
sum(rate(funboost_task_total{status="fail"}[5m])) / sum(rate(funboost_task_total[5m])) > 0.1队列积压告警:
funboost_queue_msg_count{queue="my_task"} > 1000
详细指标说明见文档 4b.9 节及 funboost_promethus_mixin.py。
6.30.4 使用funboost的 MongoAlertMonitor 实现错误告警
基于监控一段时间内,已保存到mongo的函数执行状态的 success 字段为False的比例或者数量来实现的监控
这个MongoAlertMonitor是分布式汇总监控,所以对于多进程多机器分布式消费错误监控更好。
而AlertNotifierConsumerMixin是基于内存计数的监控。
MongoAlertMonitor监控错误告警的前提条件是必须设置is_save_status=True
@boost(BoosterParams(
...
function_result_status_persistance_conf=FunctionResultStatusPersistanceConfig(
is_save_status=True, # 必须保存函数执行状态到mongo
),
))
6.30.4.1 MongoAlertMonitor 使用例子,发到内置实现的 企业微信 钉钉 飞书
告警渠道支持 企业微信 钉钉 飞书,只需要提供webhook
# -*- coding: utf-8 -*-
"""
MongoAlertMonitor 告警监控示例
运行前请先启动 t_tasks.py 让任务持续产生成功/失败记录到 MongoDB。
本脚本演示三种使用场景:
场景1:只监控高失败率队列,按报错次数告警
场景2:只监控低失败率队列,按失败率告警
场景3:同时监控两个队列,两种策略叠加(任一满足即告警)
运行时将在 window_seconds=60 秒窗口内统计执行情况,
每 poll_interval=10 秒检查一次,alert_interval=60 秒内不重复发告警。
webhook_url 替换为你自己的企业微信/钉钉/飞书 Webhook 地址。
"""
from funboost.core.mongo_alert_monitor import MongoAlertMonitor
# 导入需要监控的 boosters ,这样才能根据配置,知道查询去监控哪些mongo表
# task_high_failure, task_low_failure 是被 @boost装饰的boosters
from test_frame.test_mongo_alert.t_tasks import task_high_failure, task_low_failure
WECHAT_WEBHOOK = 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxxxx'
# ── 场景1:60 秒内报错次数 >= 5 次 就告警(高失败率队列)────────────────────
MongoAlertMonitor(
boosters=task_high_failure,
alert_app='wechat',
webhook_url=WECHAT_WEBHOOK,
window_seconds=60,
failure_count=5, # 60 秒内报错 >= 5 次触发
poll_interval=10, # 每 10 秒检查一次
alert_interval=60, # 60 秒内不重复发告警(方便测试,生产建议 300+)
).start()
# ── 场景2:60 秒内失败率 >= 50% 且总调用 >= 10 次 就告警(低失败率队列)──────
MongoAlertMonitor(
boosters=task_low_failure,
alert_app='wechat',
webhook_url=WECHAT_WEBHOOK,
window_seconds=60,
errors_rate=0.5, # 失败率 >= 50% 触发
min_calls=10, # 至少 10 次调用才评估
poll_interval=10,
alert_interval=60,
).start()
# ── 场景3:同时监控两个队列,两种策略叠加(任一满足即告警)──────────────────
# 注意:一个 MongoAlertMonitor 实例同时监控多个队列,每个队列告警状态独立
MongoAlertMonitor(
boosters=[task_high_failure, task_low_failure],
# 如果你要监控所有boosters,可以写 boosters=BoostersManager.get_all_boosters()
alert_app='wechat',
webhook_url=WECHAT_WEBHOOK,
window_seconds=60,
failure_count=3, # 任一队列 60 秒内报错 >= 3 次
errors_rate=0.3, # 或 失败率 >= 30%
min_calls=5,
poll_interval=10,
alert_interval=60,
).start()
6.30.4.2 MongoAlertMonitor 使用例子,发到自定义的渠道
如果你不是发到企业微信 钉钉 飞书,你如果想发短信 打电话 发邮件 完全可以。
主要是你要写个类,继承 MongoAlertMonitor ,重写 custom_send_notification方法,类实例化时候要指alert_app='custom'
# 示例4:自定义告警通道(发邮件等),继承重写 custom_send_notification
class EmailAlertMonitor(MongoAlertMonitor):
def custom_send_notification(self, message: str):
send_email(to='ops@example.com', subject='任务告警', body=message)
EmailAlertMonitor(
boosters=my_task,
alert_app='custom',
window_seconds=60,
failure_count=10,
).start()
6.30.5 在funweb 页面中配置告警
funweb页面中也可以配置告警,原理是复用已有的上报到redis中的数据,用户在页面上针对队列名字,可以配置 积压超标、qps骤降、消费者掉线、失败率飙升、平均耗时高 5种告警指标。
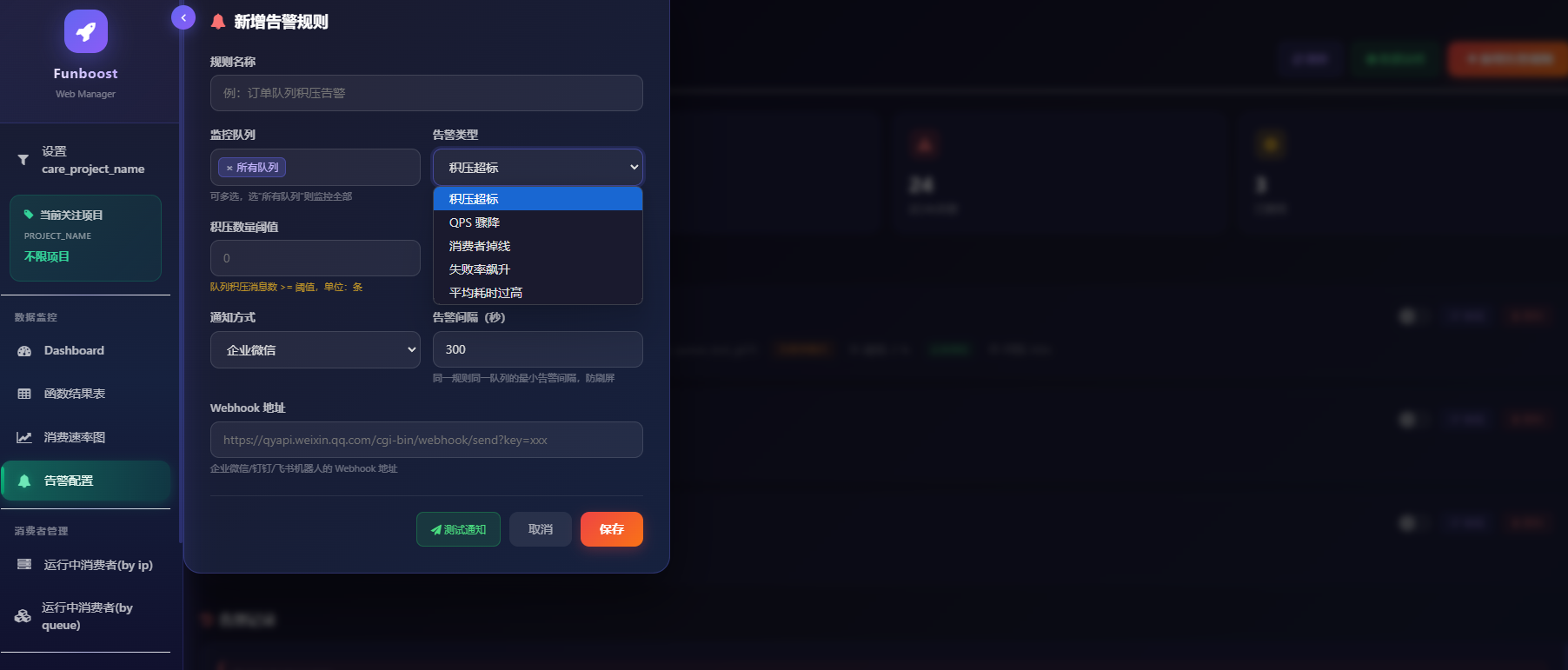
6.30.6 elk + grafana 实现错误告警
将 Funboost 的日志文件夹通过 Filebeat/Logstash 采集到 Elasticsearch,然后在 Grafana 中配置 Elasticsearch 数据源的ERROR日志比例或者个数,告警规则。这种方式适合已有 ELK 体系的环境。
懂elk和grafana的人都知道怎么做,无需我长篇展开。
6.30.10 错误触发警告的方式选择
以上5种方式可根据实际条件来使用,实现从实时通知到趋势告警的全方位失败监控。 例如你公司没有 promethus ,公司没有运维帮你搭建elk 和 grafana,你只是一名个体用户开发者,可以选择其他不依赖这些高端运维组件的错误告警方式。
6.31 怎么知道 Funboost 发布者生成的最终消息内容格式是什么样?
6.31.1 方式一:直接查看 Broker
先发布消息到 Broker,然后去对应的消息队列(如 Redis、Kafka)查看原始消息内容。
6.31.2 方式二:预览消息(不真正发送)
如果不想发布消息到 Broker,可以通过 publisher 提供的两个方法预览生成的消息内容:
方法 |
用途 |
|---|---|
|
预览 |
|
预览 |
# 假设 add_task 是一个 booster 对象
print(add_task.publisher.generate_msg_context_for_push(i, i * 2))
print(add_task.publisher.generate_msg_context_for_publish(
{"x": i * 10, "y": i * 20},
task_id=f'task_{10000 + i}'
))
一个最简单的消息,至少包括如下:
task_options的控制入参传递越多,extra字段的key就会越多。
{
"extra": {
"publish_time": 1774348711.2128,
"publish_time_format": "2026-03-24 18:38:31",
"task_id": "019d1f6c-b52c-75f7-9bd0-7f1b19becd61"
},
"x": 9,
"y": 18
}
💡 适用场景:调试消息格式、确认序列化结果、排查消息投递问题。