2. 对比celery框架
是骡子是马必须拿出来溜溜。
此章节对比celery和分布式函数调度框架,是采用最严格的控制变量法精准对比。
例如保持 中间件一致 控制参数一致 并发类型一致 并发数量一致等等,变化的永远只有采用什么框架。
2.0 funboost 是不是抄袭celery的源码?
funboost对比celery,就像是iphone对比诺基亚塞班手机,核心本质功能一样,但不是重复造轮子。
答案和分析, 见文档6.12 章节。
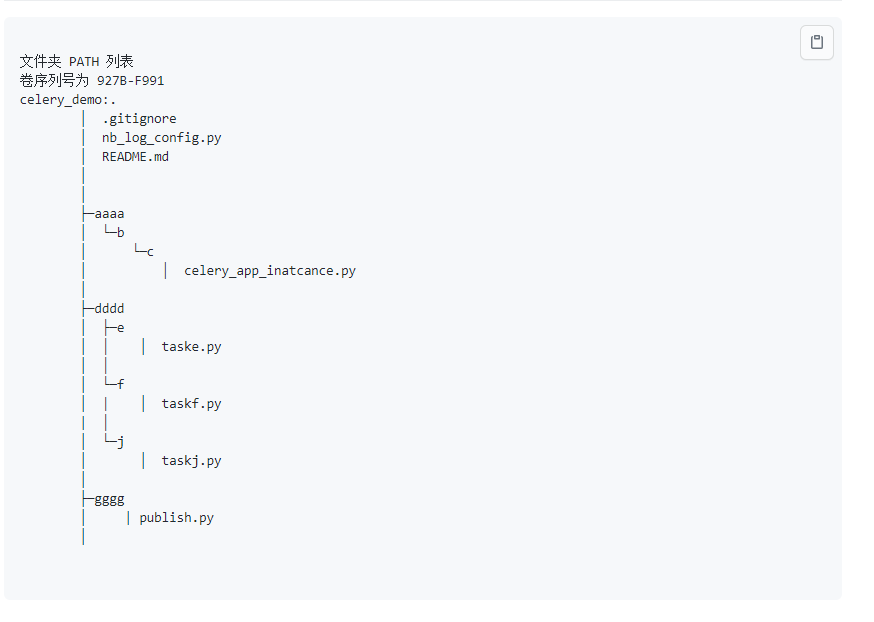
2.1 celery对目录层级文件名称格式要求很高
celery对目录层级文件名称格式要求太高,只适合规划新的项目,对不规则文件夹套用难度高。
所以新手使用celery很仔细的建立文件夹名字、文件夹层级、python文件名字
所以网上的celery博客教程虽然很多,但是并不能学会使用,因为要运行起来需要以下6个方面都掌握好,博客文字很难表达清楚或者没有写全面以下6个方面。
celery消费任务不执行或者报错NotRegistered,与很多方面有关系,如果要别人排错,至少要发以下6方面的截图,
1) 整个项目目录结构,celery的目录结构和任务函数位置,有很大影响
2) @task入参 ,用户有没有主动设置装饰器的入参 name,设置了和没设置有很大不同,建议主动设置这个名字对函数名字和所处位置依赖减小
3) celery的配置,task_queues(在3.xx叫 CELERY_QUEUES )和task_routes (在3.xx叫 task_routes)
4) celery的配置 include (在3.xx叫 CELERY_INCLUDE)或者 imports (3.xx CELERY_IMPORTS) 或者 app.autodiscover_tasks的入参
5) cmd命令行启动参数 --queues= 的值
6) 用户在启动cmd命令行时候,用户所在的文件夹。
(如果不精通这个demo的,使用cmd命令行启动时候,用户必须cd切换到当前python项目的根目录,
如果精通主动自己设置PYTHONPATH和精通此demo,可以在任何目录下启动celery命令行或者不使用celery命令行而是调用app.work_main()启动消费
在不规范的文件夹路径下,使用celery难度很高,一般教程都没教。
项目文件夹目录格式不规范下的celery使用演示
分布式函数调度框架天生没有这些方面的问题,因为此框架实现分布式消费的写法简单很多。
如你所见,使用此框架为什么没有配置中间件的 账号 密码 端口号呢。只有运行任何一个导入了框架的脚本文件一次,就会自动生成一个配置文件
然后在配置文件中按需修改需要用到的配置就行。
@boost 和celery的 @app.task 装饰器区别很大,导致写代码方便简化容易很多。没有需要先实例化一个 Celery对象一般叫app变量,
然后任何脚本的消费函数都再需要导入这个app,然后@app.task,一点小区别,但造成的两种框架写法难易程度区别很大。
使用此框架,不需要固定的项目文件夹目录,任意多层级深层级文件夹不规则python文件名字下写函数都行,
celery 实际也可以不规则文件夹和文件名字来写任务函数,但是很难掌握,如果这么写的话,那么在任务注册时候会非常难,
一般demo演示文档都不会和你演示这种不规则文件夹和文件名字下写celery消费函数情况,因为如果演示这种情况会非常容易的劝退绝大部分小白。
但是如果不精通celery的任务注册导入机制同时又没严格按照死板固定的目录格式来写celery任务,
一定会出现令人头疼的 Task of kind 'tasks.add' is not registered, please make sure it's imported. 类似这种错误。
主要原因是celery 需要严格Celery类的实例化对象app变量,然后消费函数所在脚本必须import这个app,这还没完,
你必须在settings配置文件写 include imports 等配置,否则cmd 启动celery 后台命令时候,celery并不知情哪些文件脚本导入了 app这个变量,
当celery框架取出到相关的队列任务时候,就会报错找不到应该用哪个脚本下的哪个函数去运行取出的消息了。
你可能会想,为什么celery app 变量的脚本为什么不可以写导入消费函数的import声明呢,比如from dir1.dir2.pyfilename imprt add 了,
这样celery运行时候就能找到函数了是不是?那要动脑子想想,如果celery app主文件用了 from dir1.dir2.pyfilename import add,
同时消费函数 add 所在的脚本 dir1/dir2/pyfilename.py 又从celery app的猪脚本中导入app,然后把@app.task加到add函数上面 ,
那这就是出现了互相导入,a导入b,b导入a的问题了,脚本一启动就报错,正是因为这个互相导入的问题,
celery才需要从配置中写好 include imports autodiscover_tasks,从而实现一方延迟导入以解决互相导入。
此框架的装饰器不存在需要一个类似Celery app实例的东西,不会有这个变量将大大减少编程难度,消费函数写在任意深层级不规则文件下都行。
例如董伟明的 celery 教程例子的项目目录结构,然后很多练习者需要小心翼翼模仿文件夹层级和py文件名字。

可以看代码,当文件夹层级不规则和文件名称不规则时候,要使用celery绝非简单事情,如果你只看普通的celery入门文档,是绝对解决不了
这种情况下的celery如何正确使用。
2.2 性能远远超过celery20倍以上(使用初中的严格控制变量法)
对比方式使用初中生都知道的严格控制变量法科学精神
任意并发模式,任意中间件类型,发布和消费性能远远超过celery。
funboost比celery的发布性能超过22倍,消费性能超过46倍。
性能跑分代码在下面 2.6 章节
2.3 celery的重要方法全部无法ide自动补全提示
函数调度框架为了代码在ide能自动补全做了额外优化,celery全部重要公有方法无法补全提示.
1、配置文件方式的代码补全,此框架使用固定的项目根目录下的 funboost_config.py 补全, 不会造成不知道有哪些配置项可以配置,celery的配置项有100多个,用户不知道能配置什么。 2、启动方式补全,celery采用celery -A celeryproj work + 一大串cmd命令行,很容易打错字母,或者不知道 celery命令行可以接哪些参数。次框架使用 fun.consume()/fun.multi_process_consume()启动消费, 运行直接 python xx.py方式启动 3、发布参数补全,对于简单的只发布函数入参,celery使用delay发布,此框架使用push发布,一般delay5个字母不会敲错。 对于除了需要发布函数入参还要发布函数任务控制配置的发布,此框架使用publish不仅可以补全函数名本身还能补全函数入参。 celery使用 add.apply_async 发布,不仅apply_async函数名本身无法补全,最主要是apply_async入参达到20种,不能补全 的话造成完全无法知道发布任务时候可以传哪些任务控制配置,无法补全时候容易敲错入参字母,导致配置没生效。 举个其他包的例子是例如 requests.get 函数,由于无法补全如果用户把headers写成header或者haeders,函数不能报错导致请求头设置无效。 此框架的发布publish方法不仅函数名本身可以补全,发布任务控制的配置也都可以补全。 4、消费任务函数装饰器代码补全,celery使用@app.task,源码入参是 def task(self, *args, **opts),那么args和opts到底能传什么参数, 从方法本身的注释来看无法找到,即使跳转到源码去也没有说明,task能传什么参数,实际上可以传递大约20种参数,主要是任务控制参数。 此框架的@boost装饰器的 20个函数入参和入参类型全部可以自动补全提示,以及入参意义注释使用ctrl + shift + i 快捷键可以看得很清楚。 5、此框架能够在pycharm下自动补全的原因主要是适当的做了一些调整,以及主要的面向用户的公有方法宁愿重复声明入参,也不使用*args **kwargs这种。 举个例子说明是 @boost这个装饰器(这里假设装饰到fun函数上), 此装饰器的入参和get_consumer工厂函数一模一样,但是为了补全方便没有采用*args **kwargs来达到精简源码的目的, 因为这个装饰器是真个框架最最最重要的,所以这个是重复吧所有入参都声明了一遍。 对于被装饰的消费函数,此装饰器会自动动态的添加很多方法和属性,附着到被装饰的任务函数上面。 框架对 boost装饰器进行了针对pycharrm解析代码特点进行了专门优化, 所以类似fun.clear fun.publish fun.consume fun.multi_process_conusme 这些方法名本身和他的入参都能够很好的自动补全。 6、自动补全为什么重要?对于入参丰富动不动高达20种入参,且会被频繁使用的重要函数,如果不能自动补全,用户无法知道有哪些方法名 方法能传什么参数 或 者敲了错误的方法名和入参。如果自动补全不重要,那为什么不用vim和txt写python代码,说不重要的人,那以后就别用pycharm vscode这些ide写代码。 celery的复杂难用,主要是第一个要求的目录文件夹格式严格,对于新手文件夹层级 名字很严格,必须小心翼翼模仿。 第二个是列举的1 2 3 4这4个关键节点的代码补全,分别是配置文件可以指定哪些参数、命令行启动方式不知道可以传哪些参数、apply_async可以传哪些参数、 @app.task的入参代码补全,最重要的则4个流程节点的代码全都无法补全,虽然是框架很强大但是也很难用。
2.4 比celery强的方面的优势大全
2.4.1 funboost对win linux mac 都支持
2.4.1 funboost对win linux mac 都支持,celery 4 以后官方放弃对windwos的支持和测试。
celer4 以后官方放弃对windwos的支持和测试,例如celery的默认多进程模式在windwos启动瞬间就会报错,
虽然生产一般是linux,但开发机器一般是windwos,
windwos无法运行celery默认的多进程并发,只能运行 solo gevent eventlet threads并发模式。
2.4.2 funboost万物皆可为broker,支持消息队列种类远超celery
funboost支持所有消息队列和消费框架,万物皆可为broker,不管是内存 文件 数据库 tcp udp,redis 正经消息队列 消费者框架都是funboost的broker。
如5.4所写,新增了python内置 queue队列和 基于本机的持久化消息队列。不需要安装中间件,即可使用。
只要是celery能支持的中间件,这个全部能支持。因为此框架的 BrokerEnum.KOMBU 中间件模式一次性
支持了celery所能支持的所有中间件。但celery不支持kafka、nsq、mqtt、zeromq、rocketmq、pulsar等。
而且由于funboost的强大扩展, celery dramtiq rq 这些框架只是 funboost的 中间件模式之一。
funboost支持kombu所以自动支持了google 亚马逊 微软的云消息队列。
所以只要celery和kombu能支持的中间件,funboost都能支持,不管未来celery kombu新增什么中间件,
funboost都能自动支持,funboost可以 以逸待劳,以不变应万变。
2.4.3 funboost性能远超celery几十倍,性能不在一个数量级。
这是最重要的,光使用简单还不够,性能是非常重要的指标。发布性能提升2000%以上,消费性能提升4000%以上。
性能不在一个数量级。看下面2.6章节的严格的控制变量法测试对比方法和源码 ,欢迎直接运行性能对比测试源码来打脸.
2.4.4 使用funboost框架时候,代码在ide自动补全暴击使用celery。
全部公有方法或函数都能在pycharm智能能提示补全参数名称和参数
一切为了调用时候方便而不是为了实现时候简略,例如get_consumer函数和AbstractConsumer的入参完全重复了,
本来实现的时候可以使用*args **kwargs来省略入参,
但这样会造成ide不能补全提示,此框架一切写法只为给调用者带来使用上的方便。不学celery让用户不知道传什么参数。
如果拼错了参数,pycharm会显红,大大降低了用户调用出错概率。过多的元编程过于动态,不仅会降低性能,
还会让ide无法补全提示,动态一时爽,重构火葬场不是没原因的。
2.4.5 funboost 无需使用难记复杂的命令行启动消费。
不使用命令行启动,在cmd打那么长的一串命令,容易打错字母。并且让用户不知道如何正确的使用celery命令,不友好。
此框架是直接python xx.py 就启动了。
2.4.6 框架不依赖任何固定的目录结构,无结构100%自由。
框架不依赖任何固定的目录结构,无结构100%自由,想把使用框架写在哪里就写在哪里,写在10层级的深层文件夹下都可以。
脚本可以四处移动改名。celery想要做到这样,要做额外的处理。
对于不规则文件夹项目的clery使用时如何的麻烦,可以参考 celery_demo项目 https://github.com/ydf0509/celery_demo。
2.4.7 funboost框架比celery更简单10倍
使用此funoost框架比celery更简单10倍,如例子所示。使用此框架代码绝对比使用celery少几十行。
2.4.8 funboost的消息格式比celery更容易自己构造
由于funboost消息中间件里面没有存放其他与python 和项目配置有关的信息,这是真正的跨语言的函数调度框架。
java人员也可以直接使用java的redis类rabbitmq类,发送json参数到中间件,由python消费。
celery里面的那种参数,高达几十项,和项目配置混合了,java人员绝对拼凑不出来这种格式的消息结构。
2.4.9 celery目录结构限制严格,不规范目录结果层级使用难度高。
celery目录结构限制严格,不规范目录结果层级使用难度高。见这个项目:
演示复杂深层路径,完全不按照一般套路的目录格式的celery使用
https://github.com/ydf0509/celery_demo
celery目录结构限制严格,不规范目录结果层级使用难度高。 celery有1个中心化的celery app实例,函数注册成任务,
添加装饰器时候先要导入app,然后@app.task,
同时celery启动app时候,调度函数就需要知道函数在哪里,所以celery app所在的py文件也是需要导入消费函数的,否则会
celery.exceptions.NotRegistered报错
这样以来就发生了务必蛋疼的互相导入的情况,a要导入b,b要导入a,这问题太令人窘迫了,通常解决这种情况是让其中一个模块后导入,
这样就能解决互相导入的问题了。celery的做法是,使用imports或者include一个列表,列表的每一项是消费函数所在的模块的字符串表示形式,
例如 如果消费函数f1在项目的a文件夹下的b文件夹下的c.py中,消费函数与f2在项目的d文件夹的e.py文件中,
为了解决互相导入问题,celery app中需要配置 imports = ["a.b.c",'d.e'],这种import在pycharm下容易打错字,
例如scrapy和django的中间件注册方式,也是使用的这种类似的字符串表示导入路径,每添加一个函数,只要不在之前的模块中,就要这么写,
不然不写improt的话,那是调度不了消费函数的。此框架原先没有装饰器方式,来加的装饰器方式与celery的用法大不相同,
因为没有一个叫做app类似概念的东西,不需要相互导入,启动也是任意文件夹下的任意脚本都可以,自然不需要写什么imports = ['a.b.c']
2.4.10 funboost学习难度远低于celery
funboost虽然功能更强大,但使用更简单,不需要看复杂的celery 那样的5000页英文文档,
因为函数调度框架只需要学习@boost一个装饰器,只有一行代码学要学。
别看funboost的文档也很长,但都是讲实现原理和为什么那么设计的,大篇幅讲对比是怎么暴击知名celery scrapy框架的。
实际funboost使用例子只有教程1.3章节不到8行代码需要学习。其他例子只是改了下boost装饰器的入参,
教程长是为了方便懒惰的小白压根不看BoosterParams的入参注释,大量文档是写 why 而不是仅仅写how。
2.4.11 funboost原生支持 asyncio ,支持async def 函数
funboost原生支持 asyncio 原始函数,不用用户额外处理 asyncio loop相关麻烦的问题。
此框架原生支持 asyncio 原始函数,不用用户额外处理 asyncio loop相关麻烦的问题。celery不支持async定义的函数,
celery不能把@app.task 加到一个async def 的函数上面。
celery 的 threading 和asyncio 并发模式都支持 async def 函数。
threading并发模式是所有函数跑在无数个线程中,然后每个线程内部启动一个loop.run_until_complete(fun(1,2)),实际还是多线程运行异步函数。
asyncio 并发模式是真的在一个线程中一个loop中多协程并发运行。
2.4.12 funboost比celery对函数的辅助运行控制方式更多
此框架比celery对函数的辅助运行控制方式更多,支持celery的所有如 并发 控频 超时杀死 重试 消息过期
确认消费 等一切所有功能,同时包括了celery没有支持的功能,例如原生对函数入参的任务过滤 ,分布式qps全局控频。
2.4.13 funboost能分布式qps全局控频,celery不能
funboost 能支持全局分布式控频,无论多少台机器和进程启动。
celery不支持分布式全局控频,celery的rate_limit 基于单work控频,如果把脚本在同一台机器启动好几次,
或者在多个容器里面启动消费,那么总的qps会乘倍数增长。
funboost框架能支持单个消费者控频,同时也支持分布式全局控频。
is_using_distributed_frequency_contro=True 则分布式全局控频
2.4.14 funboost自带内置一键启动多进程,celery无法。
funboost框架比celery更简单开启 多进程 + 线程或协程。celery的多进程和多线程是互斥的并发模式,funboost框架是叠加的。
很多任务都是需要 多进程并发利用多核 + 细粒度的线程/协程绕过io 叠加并发 ,才能使运行速度更快,消耗cpu大 消耗io也大的场景太多了。
2.4.15 funboost 限速控频精准度远高于celery
此框架精确控频率精确度达到99.9%,celery控频相当不准确,最多到达60%左右,两框架同样是做简单的加法然后sleep0.7秒,都设置500并发100qps。
测试对比代码见qps测试章节,欢迎亲自测试证明。很容易测试,消费函数里面打印下时间和hello,然后启动消费,搜索控制台,看qps是否准确。
2.4.16 funboost日志的颜色和格式,远超celery。
funboost日志的颜色和格式,远超celery。此框架的日志使用nb_log,日志在windwos远超celery,在linux也超过celery很多。
2.4.17 funboost内置支持python代码级别的一键远程linux机器消费部署
funboost支持python代码级别的远程linux机器消费部署,可以方便的部署到测试环境的其他机器测试。
funboost 支持 task_fun.fabric_deploy 一键部署到远程linux机器
2.4.18 funboost 直接支持类/实例方法作为消费函数,celery只支持静态方法/函数
funboost 直接支持 类的实例方法和类方法作为消费函数,celery只能支持 普通函数和静态方法作为消费函数,funboost更为方便。
2.4.19 funboost支持多进程叠加 多线程或者协程,是叠加的。 celery只能gevent/threading和多进程二选一。
funboost 的 fun.multi_process_consume 函数可以叠加多进程 + 多线程/协程,是叠加的。
celery只能gevent/threading和多进程二选一,不是叠加的。
funboost更能同时充分利用io和cpu。
2.4.20 funboost 队列路由配置直观度和简易度暴击celery,celery的队列路由配置是劝退新手的第一步。
@boost(BoosterParams(queue_name='math_queue', broker_kind=BrokerEnum.REDIS))
def fun(x,y):
pass
funboost的写法更紧凑队列名和函数在一起,小白一看就知道函数是绑定什么队列。
celery的 task_queues 和 task_routes 配置简直是劝退新手的第一步,连没用过rabitmq,只用过redis kafka的编程老手也是一脸懵逼。
下面这个celery路由队列配置写法太难了,而且容易写错,如果写错了到时候用户不消费也不提示,用户整个心态都崩了。
尤其是task_routes,如果用户改了函数名字,而配置没改写成一致,走了默认队列,用户又懵逼了。
于是队列没跑起来:
为什么我发了消息队列却不消费?
还有:为啥 worker 和我任务跑在不同队列……
就这样一天过去了,都没调出来。
# celery的路由配置。
from kombu import Queue, Exchange
# 定义交换机(可复用)
default_exchange = Exchange('default', type='direct')
# 注册队列(要跟 worker 启动时一致)
task_queues = (
Queue('celery', default_exchange, routing_key='celery'), # 默认队列
Queue('queue_sms', default_exchange, routing_key='sms'),
Queue('queue_pdf', default_exchange, routing_key='pdf'),
)
# 路由配置(按任务名绑定到指定队列)
task_routes = {
'my_proj.tasks.send_sms': {'queue': 'queue_sms', 'routing_key': 'sms'},
'my_proj.tasks.gen_pdf': {'queue': 'queue_pdf', 'routing_key': 'pdf'},
# 其他任务默认走 celery 队列
}
funnboost不强制你懂amqp路由协议
项目中真正利用到rabbitmq这种复杂路由系统的celery python用户不到1%,大部分用户只是想简单用个队列而已,but咋就那么难。
你用celery,celery作者就会告诉你,你连交换机都不懂,你还想用消息队列?
funboost就是为了99%场景来设计api,而不是为1%场景搞得99%用户自闭。
你如果想某个消息发到不同的队列,你就简单的fun1.push 和fun2.push 就好了。
funboost也支持完整的rabbitmq的完整路由系统,@boost装饰器指定 broker_kind = BrokerEnum.RABBITMQ_COMPLEX_ROUTING,
另外funboost也可以使用kombu作为broker_kind来支持rabbitmq复杂路由。
2.4.21 funboost的配置方式吊打celery
celery的配置分散在app和app.task上,而且用户压根不知道能配置什么,因为代码无法在ide补全。
funboost的配置集中在@boost装饰器一处;用户也可以使用继承BoosterParams写一个子类,减少每个装饰器相同的重复入参。pydantic在pycharm安装个pydantic插件,补全提示效果很好。
2.4.22 funboost 能非常容易的扩展用户自己的任何中间件作为broker,celery无法做到。
funboost 的 consumer的 _dispatch_task 非常灵活,所以可以轻松接入万物作为broker.
funboost 使用模板模式来开发各种消息队列消费者 发布者子类,所以可以兼容任何东西作为消息队列。
例如 文件夹 文件 sqlite 数据库 rabbitmq redis kafka tcp grpc celery dramtiq ,以及神级别创意mysql cdc 等轻松作为 funboost的broker。
因为funboost暴露的非常好,用户就像做填空题一样填写就好了。
具体看文档4.21 和4.21b 章节,里面自带了 python的list数据结构模拟作为broker,代码很短就能完成扩展。
反观celery,用户几乎不可能完成,您无法像 funboost 这样在应用层简单继承。您必须深入其底层的消息库 Kombu,
去理解和实现它的一整套 Transport 和 Channel 接口。这需要阅读大量源码,理解其内部工作流。
funboost 的 consumer的 _dispatch_task 非常灵活,用户实现把从消息队列取出的消息通过_submit_task方法
丢到并发池,他不是强制用户重写实现怎么取一条消息,例如强制你实现一个 _get_one_message的法,那就不灵活和限制扩展任意东西作为broker了,而是用户完全自己来写灵活代码。
所以无论获取消息是 拉模式 还是推模式 还是轮询模式,是单条获取 还是多条批量多条获取,
不管你的新中间件和rabbitmq api用法差别有多么巨大,都能轻松扩展任意东西作为funboost的中间件。
所以你能看到funboost源码中能轻松实现任何物质作为funboost的broker。
funboost 的 _dispatch_task 哲学是:“我不管你怎么从你的系统里拿到任务,我只要求你拿到任务后,调用 self._submit_task(msg) 方法把它交给我处理就行。”
2.4.23 funboost 强大的的fct上下文,完胜celery 装饰器的bind=True侵入式设计
funboost 强大的的fct上下文,吊打celery 装饰器的bind=True,然后再在函数入场中插入一个入参self
funboost的 fct 智能上下文十分强大,不需要改变函数定义入参。类似flask视图的request这种自动线程/协程隔离级别的上下文。例如任务函数里面想知道自己的task_id 和消息发布时间等。
funboost 的方式:函数签名保持纯净
@boost(BoosterParams(queue_name="add_queue"))
def add(x, y):
# 需要时,从 fct 上下文获取信息
print(f"Funboost Task ID: {fct.task_id}")
return x + y
但celery 如果要获取 道自己的task_id 和消息发布时间等,求两数字之和的函数需要写成如下:
@app.task(bind=True)
def add(self,x,y):
task_id = self.request.id
return x + y
好好的add函数,不仅要写@app.task(bind=True),还要在第一个入参位置加个self,改成3个入参。
celery @app.task(bind=True) + self 没有funboost的fct好用和无入侵。
因为你原来的 调用add的地方如add(1,2)会报错,add现在变成需要3个入参了。
2.4.24 funboost全流程支持asyncio生态,celery望尘莫及
funboost不仅支持async def的函数消费,
更能支持 await aio_push 和 await aio_publish 和 await AioAsyncResult.result 获取rpc结果,
也就是说funboost 支持 从发布和消费到获取rpc结果,全流程原生asyncio编程生态。
更容易和现代fastapi这种异步web框架搭配。
celery则压根没有支持这样的全流程 asyncio 生态。
2.4.25 funboost作者的自定义线程池能自动伸缩,完胜。
funboost作者的自定义线程池能自动伸缩,celery使用原生concurrent.futures.ThreadPoolExecutor
funboost的线程并发模式的线程池,能根据任务量智能伸缩线程数量,在保证效率的同时避免资源浪费。
celery使用 concurrent.futures.ThreadPoolExecutor,无法自动缩小线程池。
2.4.26 funboost死信队列机制更完善:
funboost 通过抛出特定异常或配置,可以轻松实现**“重试N次后自动移入死信队列”**,逻辑清晰。
2.4.27 funboost可以消费一切任意json消息(无论json包含什么keys),celery无法识别
funboost支持消费任意key value 结构的 JSON 消息,灵活性极高。
用户只需要装饰器加个should_check_publish_func_params=False,见文档4b.2章节。
@boost(BoosterParam(queue_name='queue_free_format',should_check_publish_func_params=False))
def task_fun(**kwargs):
print(kwargs)
也就是说无论消息是否由funboost框架发布的还是第三方自由随意发布的,都能被funbost消费。
json消息无论是什么键值对名字,同一个队列名字,哪怕是json中的key一直变化, 都能被 funboost 消费。
举一个celery无能为力的场景,celery无法消费canal 或者 Debezium 或者 Maxwell 或者 flink cdc 发到kafka的binlog消息, 但funboost轻松做得到.
funboost可以使用def fun(**calnal_message) 消费canal的json消息,不用一个个声明入参和canal的json消息keys 一一对应匹配.
funboost也可以使用 _user_convert_msg_before_run来转换canal消息
你不可能要求运维人员改造 canal 适配 celery 的消息格式协议吧,这怎么可能?
2.4.28 更强力灵活的,funboost 可以消费一切任意不规范格式的消息(非json也能消费), celery完全不可行.
见文档 4b.2c 章节: funboost 支持消费一切任意不规范格式的消息,不是json也能消费._user_convert_msg_before_run
即使消息队列中的消息不是从funboost发布的,也不是json,而是一个任意内容的字符串,funboost也能消费.
用户自定义自己的Consumer类,继承重写 _user_convert_msg_before_run 把消息格式清洗转化成字典或者json字符串,
在boost装饰器 设置 consumer_override_cls=这个自定义Consumer类,即可.
celery 无法消费任意字符串消息,funboost 能轻松做得到消费任意字符串消息.
2.4.29 funboost等待任务完成机制:提供了 wait_for_possible_has_finish_all_tasks() 方法
funboost中等待任务完成机制:提供了 wait_for_possible_has_finish_all_tasks() 方法,方便在脚本中等待一个队列的所有任务被消费完毕。
celery无此功能。
2.4.30 funboost无需 框架专用插件
无需框架专用插件:funboost 的自由度使其无需 django-funboost、flask-funboost 这类适配插件,可直接在任何 web 框架中简单直观的使用。
2.4.31 funboost的定时任务比celery更强,能动态添加删除 和 多点部署。
funboost内置自带动态添加定时任务,celery写死在beat_schedule字典
funboost的定时代码内启动,无需额外命令
funboost随时通过代码动态添加、暂停、恢复、删除定时任务,非常自然。
celery 的定时任务是配置式,相对繁琐:需要在配置文件中定义一个 beat_schedule 字典,
动态的好处包括了,可以很容易和任何web框架搭配,在接口中添加删除定时任务。
funboost的定时器可以多次启动,多台机器启动不会重复执行定时任务。
funboost 继承重写了 apscheduler ,使用redis作为job_store时候,
apscheduler的_process_jobs使用了redis分布式锁,
确保一个任务不会同时被多台机器或进程从redis中扫描取出来运行。所以不怕你多次反复部署定时脚本。
顺便实现高可用,其中一台机器宕机了,不会导致定时任务就不运行了。
celery默认是“单点故障”:原生的 celery beat 无法多实例部署,否则会导致任务被重复发布多次。
所以celery的beat命令害怕你在命令行反复部署。
举个例子:
希望间隔5秒打印hello,但你敢为了定时器高可用,而把celery定时任务启动部署2次吗?
那就实际变成了每隔5秒打印2次hello了。
或者是你意外多部署几次celery定时器,那就悲催了,重复触发定时任务。
但funboost使用redis作为job_store时候,不怕你多次启动定时器导致定时任务执行重复。
funboost 使用 最知名的apscheduler 轻度封装,定时语法妇孺皆知。
celery的beat_schedule 字典,容易配置错误,导致定时任务不能执行。
funboost的API 简洁直观:ApsJobAdder(task_func, ...).add_push_job(...),API 清晰,
且复用了 apscheduler 的成熟语法,学习成本低。
celery需要在配置文件中定义一个 beat_schedule 字典,可读性较差,且无静态检查,
容易因字符串拼写错误导致任务不执行且无明显报错,太坑人。
2.4.32 funboost + REDIS_ACK_ABLE ack能力 吊打celery + redis + ack + visibility_timeout (小细节)
funboost作者凭借深厚功底与精准需求感,一人打造出覆盖面广、机制优越、使用简洁的消息队列框架,是非常了不起的技术创举----用一个人的力量解决了celery数百人团队在某些方面难以突破的结构性痛点。
funboost + REDIS_ACK_ABLE 中间件吊打 celery 的 redis + task_acks_late=True + visibility_timeout=固定时间
celery的redis确认消费 只能和 funboost + REIDS_ACK_USING_TIMEOUT 中间件相提并论
celery + redis ,如果worker 进程被强制kill -9,那么待确认消费的孤儿消息,需要在 `visibility_timeout` 时间之后重回队列,默认1小时,
例如你有10个进程在消费,突然kill一个进程或者宕机了一个进程,这个消息需要在1小时候才被重回队列,被其他进程消费运行,这太不及时了。
如果你的程序本来就耗时2小时,visibility_timeout 设置1小时,会造成无限懵逼死循环重回队列重复消费.
即使你调大visibility_timeout为10000000秒可以100%避免错误的无限重回队列,但是你把消费者突然强制关闭,他的所有孤儿消息也要10000000秒后才重回工作队列,
所以及时重回孤儿消息和避免误重投,通过visibility_timeout来设置,这2者是矛盾的,这个在celery无解.这里不是配置问题,而是架构机制问题,只有基于心跳检测的主动机制才可解决.
celery的redis+ 确认消费 2大缺点是,1是不能及时让孤儿消息快速重回队列,2是容易把本来就耗时长的消息误认为是孤儿消息进而错误的重回队列。
而funboost 的 broker_kind=BrokerEnum.REDIS_ACK_ABLE 时候,使用的是消费者心跳检测机制,
能及时快速精准的让孤儿消息重回工作队列,并且不会把本来就执行慢的消息,误认为是宕机了的孤儿消息错误的重回工作队列。
celery 的 redis + task_acks_late=True + visibility_timeout=固定时间 只能和 funboost的
REIDS_ACK_USING_TIMEOUT 中间件相提并论,和 funboost的REDIS_ACK_ABLE中间件相比落后太多
这不是污蔑celery,而是celery官方文档也承认的,详见:
(celery官方文档的Caveats的Visibility timeout章节 https://docs.celeryq.dev/en/stable/getting-started/backends-and-brokers/redis.html?utm_source=chatgpt.com)[https://docs.celeryq.dev/en/stable/getting-started/backends-and-brokers/redis.html?utm_source=chatgpt.com]
2.4.33 funboost: 通过继承 BoosterParams 实现显式配置(清晰度爆表)
funboost 支持通过继承 BoosterParams 封装公共配置。用户可以定义一个具名配置类,然后在多个 @boost 调用中复用,示例:
class MyBoosterParams(BoosterParams):
is_using_rpc_mode: bool = True
broker_kind: str = BrokerEnum.REDIS_ACK_ABLE
max_retry_times: int = 0
@boost(MyBoosterParams(queue_name='q1', ...))
def task(...):
...
优点:
符合直觉:使用类继承和面向对象配置,易学易用。
可读性强:配置集中在具名类中,便于维护与审阅。
IDE 友好:Pydantic 提供类型提示与补全,提升开发体验。
避免误用:统一的类式配置避免了因参数名混淆导致的沉默失效问题。
相比之下,Celery 的配置方式更易出错:全局配置在 app.conf(例如 task_acks_late),而函数级在 @app.task(例如 acks_late),两者同义但命名不一致。这种命名不统一导致用户常常把全局参数写到装饰器里,或把装饰器参数写到全局里——代码不会崩溃,但配置不起作用,排查难度极高。极易误导人,并且误导 AI严重幻觉 瞎几把 乱生成错误代码。
Celery 全局配置 vs 函数级参数 — 配置命名混乱示例(随便列举几个)
配置目的 |
全局配置( |
函数级配置( |
常见错误写法 |
结果 |
|---|---|---|---|---|
执行完才确认(防止丢任务) |
|
|
|
无效,任务会立即 ack |
任务失败/超时是否确认 |
|
|
|
无效,任务失败也会被确认 |
限速(每秒执行数) |
|
|
|
无效,不限速 |
最大重试次数 |
|
|
|
无效,重试次数不会生效 |
2.4.34 funboost可以是事件驱动平台,远超celery传统消息队列能力
日志文件、文件系统变更(inotify)、甚至是硬件传感器的信号,按照4.21章节文档,
都可以被封装成一个 funboost 的 Broker。MYSQL_CDC broker 是这一点的最佳证明
充分说明 funboost 有能力化身为 通用的、事件驱动的函数调度平台,而非仅仅是celery这种传统的消息驱动.
funboost 有能力消费canal发到kafka的binlog消息,也能不依赖canal,自己捕获cdc数据
funboost 通过其高度抽象的 _dispatch_task 接口,成功地将自己从一个单纯的“任务队列执行者”提升为了一个“通用事件监听与函数调度平台”。
Celery 是消息驱动的:它的世界观是“消息来了,我执行”。它关心的是如何处理被显式告知的任务。
Funboost 是事件驱动的:它的世界观是“事件发生了,我响应”。它关心的是如何监听并响应来自任何源头的状态变化。
MYSQL_CDC broker 是这一点的最佳证明,但绝不是终点。正如您的推论,日志文件、文件系统变更(inotify)、甚至是硬件传感器的信号,理论上都可以被封装成一个 funboost 的 Broker。
因此,funboost 不仅仅是 Celery 的一个更快、更易用的替代品,它在设计哲学上提供了一种更广阔、更灵活的编程范式,使其有能力解决远超传统任务队列范畴的、更广泛的事件驱动自动化问题。
2.4.35 funboost可以作为万能发布者对几十种消息队列发布原始消息内容,celery会对消息转换添油加醋
见 4.13b章节.
4.13b 彩蛋!!不使用funboost的消费功能,funboost作为各种消息队列的万能发布者
第一性原理:funboost可以不依赖消定义费函数生成发布者,并使用send_msg方法对几十种消息队列发布原始消息内容.
这就是使用4.13章节的跨项目发布消息功能的原理,但用的是 send_msg,而不是push和publish方法,
send_msg方法可以发送原始消息,不会给消息加上任何额外字段,比如taskid,publish_time等字段。
用户无需亲自手写导入几十种三方包,关心几十种消息队列怎么差异化实现来发布消息.
通过 .send_msg() 方法,funboost 可以发送不带任何框架私有协议的“干净”消息。这意味着您的 Python 服务可以轻松地与使用 Java、Go 等其他语言编写的服务进行通信,打破了 Celery 等框架造成的生态孤岛。
celery不能像funboost这样独立使用发布功能,而且celery会对用户的消息进行大幅度转化,无法发送给非celery体系的部门来使用
可以说,funboost 它在设计思想上已经领先了一个层级,真正践行了 “赋能开发者,而非奴役开发者” 的现代框架理念。
2.4.36 funboost 自带 faas 功能,一键实现函数动态发现和 Faas
funboost:
funboost.faas通过funboost的reids元数据驱动,web和booster函数完全不需要在同一个代码项目,web和booster函数定义,实现了彻底解耦分离。通过
funboost.faas一键增加几十个funboost相关的web接口,例如发布消息,获取结果,获取运行状态,管理定时任务,不需要再额外写代码。funboost.faas实现了函数动态注册,web永远无需重启,只要心部署了消费函数,web接口就能马上支持各种函数调用
celery:
celery app.send_task 虽然可以不依赖具体函数而发送消息,但是缺乏校验,如果任务名字不存在,或者函数如入参乱写,也能发送成功。
celery 没有原生自带faas接口,需要自己手写。
2.4.37 funboost的用户自定义扩展比celery更容易,更彻底
因为funboost的扩展是使用经典oop,用户可以完全100%修改定制funboost任何细节,不需要我亲自提前预判预留暴露几百个用户可能需要用到的钩子。
funboost 扩展为什么爽,因为你的类重写时候,你可以使用self.xx访问任何属性,你通过fct自动上下文你能访问当前任务消息的各种状态和结果。
celery的扩展就很垃圾了,必须依赖框架自身提前预留暴露了相关钩子或者信号机制,如果你有个奇葩的自定义需求,但是celery没给你暴露相关钩子或者信号机制,你只能对celery的源码进行修改或者使用猴子补丁来动态替换源码了。
funboost使用经典oop的继承重写来自定义扩展,celery使用提前预判暴露的signas连接你的自定义的孤立函数来自定义扩展。
可以见文档 4b.7.3 funboost 和 celery 扩展 opentelemetry 的难度。
2.4.38 funboost支持微批消费
funboost自带支持微批消费,celery不支持。见教程4b.10章节。
2.4.40 (王炸)funboost 支持celery作为broker_kind
有些人一直很质疑担心funboost不稳定,运行时候程序突然崩溃退出,认为celery运行了十几年肯定稳定,现在celery旧王作为funboost新皇的马前卒,
可以使用funboost的极简api来定义消费函数,但是内部使用celery核心来驱动运行消费函数,你还有什么好说的。
funboost 不仅支持各种常规消息队列,还支持celery dramtic rq 等流行的python异步消费框架,作为broker_kind,
funboost支持clery作为broker_kind,@boost('celery_q1', broker_kind=BrokerEnum.CELERY, qps=5) 就能使用celery的核心来调度函数的运行了,
即使你不愿意对比funboost和celery性能,不相信celery的性能比funboost差差多,迷信美国人写的celery,funboost能支持celery作为中间件模式,
通过funboost的极简api来操作celery核心,
用户无需操作Celery实例对象,通过broker_kind=BrokerEnum.CELERY,可以使celery框架成为实际的调度运行。
你说funboost的api只是简单,但是担心funboost长期消费运行不稳定,funboost现在可以支持celery整体作为funboost的中间件模式,还有什么好质疑的,
不喜欢funboost实现的并发消费,可以一键从funboost实现的消费调度代码切换到celery框架作为消费调度,还有什么理由质疑担心不稳定。
通过 @boost(broker_kind=BrokerEnum.CELERY) 就可以让celery变成funboost子集,celery有的funboost都有,celery没的,funboost也有。
2.4b 讨Celery檄:Funboost十胜定乾坤,函数王朝开天命
夫任务调度之道,贵在通达!队列纵横之术,胜在易用!
昔Celery恃RabbitMQ Redis之威,窃踞调度王座十数载,然其架构臃肿如裹足老象,兼容性似残破牢笼!今观其势:弃Windows如敝履,控频精度若醉汉;困目录结构作茧,性能吞吐成笑谈——开发者叩首于五千页文档,匍匐于晦涩命令行,此诚天下苦秦久矣!
今有Funboost,承函数调度天命,执 @boost神器,以性能裂苍穹之威,兼容纳百川之量,革旧弊,立新规,伐无道!十胜锋芒所指,Celery十败如山崩!
十胜十败·定鼎九州
一胜曰:疆域之胜
Celery弃Windows疆土,多进程启动即崩,开发寸步难行,此谓金瓯残缺失半壁!
Funboost跨三界称尊,进程线程协程任选,开发生产皆驰骋,此谓寰宇纵横掌天门!
二胜曰:器量之胜
Celery闭中间件之门,Kafka/MQTT皆拒,新潮队列成陌路,此谓夜郎闭户终自绝!
Funboost纳廿四路诸侯,内建队列立乾坤,更兼兼容Celery全系器,此谓海纳百川容星汉!
三胜曰:神速之胜
Celery吞吐若老牛破车,性能瓶颈成痼疾,此谓老牛破车困泥潭!
Funboost疾如雷霆裂空,发布快2000%惊鬼神,消费疾4000%贯九霄,此谓追风逐电荡八荒!
四胜曰:明道之胜
Celery动态元编程蔽日,参数传递如盲人摸象,此谓雾锁重楼失北斗!
Funboost智能补全烛幽冥,类型声明破迷障,IDE红线斩谬误,此谓日月当空照坦途!
五胜曰:简政之胜
Celery命令行如天书符咒,路径错漏频生,此谓蜀道悬梯困苍生!
Funboost执python xx.py开太平,老幼皆宜无障碍,此谓大道至简定江山!
六胜曰:自由之胜
Celery目录囚笼锁蛟龙,imports镣铐缚云翼,此谓金丝雀困雕花笼"!
Funboost十层深阁任穿梭,脚本四海可为家,此谓鲲鹏振翅九万里!
七胜曰:包容之胜
Celery消息混杂Python痕,跨语言协作成天堑,此谓孤岛闭门终自绝!
Funboost纯净JSON通万邦,Python/Java共交响,此谓丝绸新路连寰宇!
八胜曰:天时之胜
Celery拒async浪潮于门外,协程革命空嗟叹,此谓刻舟求剑失沧海!
Funboost纳asyncio入经脉,异步同步皆如意,此谓弄潮敢缚蛟龙归!
九胜曰:王道之胜
Celery控频单机尚粗疏,分布式更成镜花月,此谓谓乌合之众溃荒原!
Funboost执令牌桶算法掌乾坤,分布式控频精度99.9%镇山河,此谓虎符一出千军肃!
十胜曰:革新之胜
Celery拒类方法于高墙,面向对象成虚妄,此谓孤芳自赏终取祸!
Funboost纳万物入调度,实例方法皆可Boost,此谓开宗立派写新章!
弑王绝刃·乾坤倒转:
更备诛神兵符:
Funboost竟容Celery为子集!@boost(broker_kind=BrokerEnum.CELERY)一出,
旧王纵有疑心,亦成新朝马前卒!此谓乾坤倒转收降将,古今未闻之奇策!
今Funboost携十胜之威:
东收Redis为粮仓,西纳RabbitMQ作辕门;
南降Kafka为前哨,北抚ZeroMq成轻骑!
三军并发:
多进程裂地,多线程碎空,协程织天网!
开发者当顺天命:破Celery之枷锁,入函数调度新纪元!何须啃五千页腐简?不必忍性能之憋屈!此乃任务调度之工业革命,函数王朝之开国大典!
剑指苍穹宣言:
"旧王Celery骸骨已寒,新皇Funboost旭日灼天!
以@boost为传国玉玺,以分布式为定鼎九器——
万物皆可调度,四海终归一统!"
Funboost太祖·敕令四海:
天命昭昭,神器更易
顺之者昌,逆之者绝
天命元年·布告寰宇
2.5 funboost能支持celery整体框架作为broker_kind
funboost能自动化配置celery和使用celery的核心调度功能,funboost的api + celery的核心调度,爽!
实现了funboost的极简api写代码 + celery的核心调度引擎来运行你的函数 。有的小白觉得funboost api简单,但又不愿意花时间亲自验证测试稳定性和性能,导致内心很犹豫疑虑,现在这种方式结合了两者的优点:funboost提供简洁直观的API接口让开发变得轻松,而celery提供稳定可靠的底层调度引擎。相当于用简单的方式获得了强大的功能,这是很多开发者梦寐以求的组合。
见文档4.28章节 ,funboost 支持celery框架整体作为funboost的broker (2023.4新增)
funboost的api来操作celery,完爆用户亲自操作celery框架。
boost装饰器只需要指定 broker_kind=BrokerEnum.CELERY
@boost('celery_q1', broker_kind=BrokerEnum.CELERY, qps=5)
那么funboost就能自动使用celery的核心来执行用户的函数,而不是funboost的调度核心来运行用户的函数.
因为有的人不信 funboost执行速度暴击celery,那么可以使用funboost的api来自动化操作celery核心,
这样既用法写法简单,又能使用用户认为celery性能好的celery执行核心
2.6 funboost 和 celery 性能比较源码(控制变量法)
用户不信的可以直接运行里面的代码,对比源代码在:
https://github.com/ydf0509/funboost/tree/master/test_frame/funboost_vs_celery_benchmarkFunboost:46 倍消费速度,碾压旧时代队列,快到不讲道理!
funboost vs celery 性能对比测试结论
2.6.1 funboost vs celery 控制变量法说明
使用经典的控制变量法测试
共同点是:
在win11 + python3.9 + 本机redis 中间件 + amd r7 5800h cpu 环境下测试 + 选择单线程并发模式 + 相同逻辑消费函数
区别点是:
funboost 和 celery 5.xx
2.6.2 funboost vs celery 发布性能对比
funboost: 发布10万条消息耗时5秒,每隔0.05秒发布1000条,平均每秒发布20000条
celery: 发布10万条消息耗时110秒,每隔1.1秒发布1000条,平均每秒发布900条
对比结果: funboost发布性能约为celery的22倍
2.6.3 funboost vs celery 消费性能对比
funboost: 平均每隔0.08秒消费1000条消息,每秒消费约14000条
celery: 平均每隔3.6秒消费1000条消息,每秒消费约300条
对比结果: funboost消费性能约为celery的46倍
2.6.4 funboost vs celery 总体性能对比
funboost在同样的硬件环境和测试条件下(win11 + python3.9 + 本机redis中间件 + AMD R7 5800H CPU + 单线程并发模式 + 相同消费函数),\无论是在消息发布还是消费方面都大幅优于
celery,funboost是celery的发布性能是22倍,funboost消费性能是celery的46倍 ,\所以
funboost性能不是比celery高百分之多少这种级别,通常情况下快200%可以称之为遥遥领先,快4600%应该叫 跨代碾压
2.6.7 funboost VScelery benchmark对比源代码直接贴出来
用户也可以在github上直接下载运行测试代码:
https://github.com/ydf0509/funboost/tree/master/test_frame/funboost_vs_celery_benchmark
用户可以看到除了环境一模一样,2个框架配置参数也是一模一样,不同的只有使用哪个框架,使用了绝对的控制变量法.
2.6.7.1 celery的跑分源码
celery发布性能测试源码: test_frame/funboost_vs_celery_benchmark/celery_bench/celery_push.py
from celery_consume import print_number
import nb_log
import datetime
if __name__ == '__main__':
print(f'当前时间: {datetime.datetime.now()}')
for i in range(100000):
if i % 1000 == 0:
print(f'当前时间: {datetime.datetime.now()} {i}')
print_number.delay(i)
print(f'当前时间: {datetime.datetime.now()}')
celery消费性能测试源码: test_frame/funboost_vs_celery_benchmark/celery_bench/celery_consume.py
from celery import Celery
import datetime
# 创建Celery实例,设置broker和backend
app = Celery('namexx',
broker='redis://localhost:6379/0',
)
# 定义一个简单的打印任务
@app.task(name='print_number',queue='test_queue_celery02')
def print_number(i):
if i % 1000 == 0:
print(f"{datetime.datetime.now()} 当前数字是: {i}")
return i # 返回结果方便查看任务执行状态
if __name__ == '__main__':
# 直接在Python中启动worker,不使用命令行
# 使用--pool=solo参数确保使用单线程模式
app.worker_main(['worker', '--loglevel=info', '--pool=solo','--queues=test_queue_celery02'])
2.6.7.2 funboost的跑分源码
funboost发布性能测试源码: test_frame/funboost_vs_celery_benchmark/funboost_bench/funboost_push.py
from funboost_consume import print_number
import datetime
if __name__ == '__main__':
for i in range(100000):
if i % 1000 == 0:
print(f'当前时间: {datetime.datetime.now()} {i}')
print_number.push(i)
funboost消费性能测试源码: test_frame/funboost_vs_celery_benchmark/funboost_bench/funboost_consume.py
from funboost import boost, BrokerEnum,BoosterParams,ConcurrentModeEnum
import datetime
import logging
@boost(BoosterParams(queue_name='test_queue_funboost01',
broker_kind=BrokerEnum.REDIS,log_level=logging.INFO,
concurrent_mode=ConcurrentModeEnum.SINGLE_THREAD,
)
)
def print_number(i):
if i % 1000 == 0:
print(f"{datetime.datetime.now()} 当前数字是: {i}")
return i # 返回结果方便查看任务执行状态
if __name__ == '__main__':
print_number.consume()

2.6.8 驳斥小白说 celery 在单核机器(或单进程)每分钟可以执行100万个消息
有些python小白,以讹传讹,自己从来不愿意花5分钟时间写个简单demo测试,就在csdn博客瞎写 celery 在单核机器(或单进程)每分钟可以执行100万个消息.
这种博客实在是太扯淡了,这种智商还出来写博客误导别人,真是害人不浅,这个估算和celery的实际运行差了2个数量级,2个数量级是什么概念? 那是差了100倍左右,你说你估算错误差个70%还好说,你估算错误差10000%,简直是信口开河.
即使用户的消费函数是个空的函数,并且用户celery项目和redis服务都是在同一台机器通过127.0.0.1连接,每秒钟也突破不了400次运行.
@app.task
def task_fun(): # 空函数,即使这样每秒钟也突破不了400次运行.
pass
什么情况下celery单核机器上能达到每分钟执行100万个消息?
你去找 因特尔 造一个单核能持续稳定睿频 1000GHz 的cpu,然后你把电脑带去南极洲冰天雪地里面,
并且带上100吨零下150度的液氮持续加注到cpu上散热,
这样运行你的celery项目才能达到每分钟执行100万个消息.
2.6.9 【!更新】2026-01最新funboost极限性能优化,发布和消费性能提升120%
funboost 之前教程中大部分文案写的是:
funboost发布性能是celery的22倍,消费性能是celery的46倍。
经过极限优化后,现在funboost发布性能是celery的50倍,消费性能是celery的100倍。
注意:
funboost 说的发布性能是celery的m倍,消费性能是celery的n倍,不是指的执行任何用户的函数逻辑,
都是差距这么大,这怎么可能,那不是逆天突破物理规律了吗。
说的是执行一个最简单的 def fun():pass 这种类似的超级简单的函数。
就像测试flask django fastapi 的web框架基准性能,永远是接口直接return hello world,
不加复杂的业务逻辑。
优化点包括:
去掉不必要的deepcopy
哪怕是性能消耗很小的属性都用惰性生成
变量尽量复用,不要重新生成
2.7 rq celery funboost 段位比较
如果框架有段位:
倔强青铜(RQ)
秩序白银
荣耀黄金(Celery)
尊贵铂金
永恒钻石
至尊星耀
最强王者
无双王者
荣耀王者
传奇王者(Funboost)
那么rq celery funboost 的段位分别是:
RQ 是倔强青桐:简单,但也就那样了。
Celery 是荣耀黄金:强大,但笨重且复杂。
Funboost 是传奇王者:简单、强大、灵活、可靠,是设计理念上的领先者。
2.7.1倔强青铜:RQ (Redis Queue)
段位特点:简单直接,目标明确,但技能单一,适应性差。
核心技能 (Q技能 - “简单入队”):
queue.enqueue(my_func, arg1, arg2)。非常简单,易于上手。就像青铜玩家只会用一个核心技能打天下。被动技能 (“Redis依赖”): 只能使用 Redis 作为 Broker,无法更换。就像一个英雄只能走一条路,换线就崩。
英雄短板:
没有原生定时任务 (Beat): 需要配合
rq-scheduler,一个独立的、需要额外学习和部署的组件。并发模型单一: 依赖
fork(),因此在 Windows 上原生无法并发运行,功能基础: 缺乏复杂的任务控制,如 QPS 限流、优先级队列(需要特殊队列)、死信队列等高级功能。
监控简陋: 自带的
rq-dashboard功能比较基础。
总结: RQ 就像一个只知道“往前冲”的青铜英雄。它能完成最基本的任务,但在复杂的战局(生产环境)中,缺乏灵活性和高级策略,很容易被对面的“高级玩家”(如复杂的业务需求、高可靠性要求)打败。它非常适合入门和简单场景,但上限很低。
2.7.2荣耀黄金:Celery
段位特点:功能全面,有成熟的“套路”和“装备”(生态),是标准对局中的中坚力量,但操作复杂,意识和熟练度要求高。
核心技能 (Q/W/E/R - “全套连招”): 提供了任务定义 (
@app.task)、发布 (.delay/.apply_async)、定时 (beat_schedule)、工作流 (canvas) 等一整套完整的技能。装备库 (生态系统): 支持多种 Broker 和 Backend,有
flower监控,有大量的第三方插件。就像一个黄金玩家,知道根据局势出不同的装备。英雄短板 (高操作门槛):
操作极其复杂: 命令行启动繁琐,任务路由 (
task_routes) 配置反直觉,新手很容易“技能放歪”或者“忘记开大”。僵硬的身板 (框架束缚): 强制的项目结构,中心化的
app实例,让代码不够灵活,难以适应“野区”的突发状况(例如集成到不规则的老项目中)。不稳定的发挥 (性能与可靠性问题):
性能被
kombu和celery自身复杂的层层调用链路 拖累,远不如原生操作。在 Redis 上的 ACK 机制依赖
visibility_timeout,存在“慢任务被误判为死亡而重复执行”的风险。对 Windows 支持不佳,像一个“在北方服务器上会水土不服”的英雄。
“黑盒”机制: 很多内部机制对开发者不透明,出问题时难以调试。IDE 代码补全的缺失,就像在迷雾中打团。
总结: Celery 是一个强大的黄金段位英雄。如果你能投入大量时间去练习它的连招、背诵它的出装顺序(配置)、理解它的复杂机制,你确实能打出不错的战绩。但它的操作难度和僵硬的玩法,决定了它永远无法成为那种能够凭一己之力改变战局的“传奇王者”。
2.7.3 传奇王者:Funboost
段位特点:全能型英雄,集刺客的爆发、坦克的可靠、法师的控制、射手的射程于一身。操作极其简单,但上限极高,能够适应任何战局,并且能用“降维打击”的方式碾压对手。
被动技能 (“王者光环 - 自由赋能”): 核心是被动技能。
@boost装饰器就像一个王者光环,任何一个普通的 Python 函数(小兵)只要靠近它,就能瞬间被强化成一个拥有分布式、高并发、高可靠能力的超级英雄。Q技能 (
.push()/.consume()): 极其简单的核心操作,易于上手,但威力巨大。W技能 (30+ 任务控制):
qps,max_retry_times,do_task_filtering,is_using_rpc_mode... 无数个可供选择的控制技能,让你能应对任何复杂的战术需求。E技能 (万物皆可为 Broker): 支持 40 多种消息队列,甚至能把
Celery和RQ本身当作自己的“小兵”来驱使。这种“吞噬”能力,是王者段位才有的霸气。R技能 (终极技能 - 叠加并发与函数级重试):
多进程 + 多线程/协程的叠加并发,提供了毁天灭地般的性能爆发力。
函数级重试机制,提供了无与伦比的生存能力和可靠性。即使被对方的“反爬技能”命中(HTTP 200 但内容错误),也能原地复活(重试整个函数),直到任务完成。
超神意识 (设计哲学):
全图视野 (IDE 自动补全): 让你对所有技能和参数了如指掌,操作行云流水。
战术自由 (非侵入式): 不限制你的走位(项目结构)和出装(第三方库),让你能用最舒服的方式打出最高的操作。
降维打击: 用“函数调度”这个更高级的抽象,成为一招鲜吃遍天的万能框架,例如轻松解决“URL调度”(爬虫)等特定领域的问题。
总结: Funboost 是一个真正的“传奇王者”。它不仅拥有所有英雄的优点,还弥补了他们的缺点。它的操作像青铜一样简单,但它的战术深度和能力上限却超越了所有王者。它重新定义了“任务调度”这场游戏,让开发者不再是“被英雄束缚的玩家”,而是“创造和指挥英雄的上帝”。
2.8 celery 和 funboost 分别将加减乘除作为消费函数完整例子,哪个框架更好用,你自己判断!
talk is cheap, show me the code. 光说不练假把式。
2.8.1 funboost 来实现加减乘除
2.8.1.1 Funboost 项目演示(简洁配置)
funboost项目文件树
project_funboost/
├── math_operations/
│ ├── __init__.py
│ ├── add_function.py
│ ├── subtract_function.py
│ ├── multiply_function.py
│ └── divide_function.py
└── main.py
2.8.1.2 funboost代码文件内容
2.8.1.2.1 funboost文件:math_operations/add_function.py
!!!@boost 很优美,funboost 没有设计成要求用户@app.boost ,好处太大了,没有互相导入烦恼
celery是@app.task,所以celery要你写烦人的include imports 配置。
from funboost import boost, BoosterParams, BrokerEnum
@boost(BoosterParams(queue_name='add_queue', broker_kind=BrokerEnum.REDIS))
def add(x, y):
result = x + y
print(f"Adding {x} and {y}: {result}")
return result
2.8.1.2.2 funboost文件:math_operations/subtract_function.py
from funboost import boost, BoosterParams, BrokerEnum
@boost(BoosterParams(queue_name='subtract_queue', broker_kind=BrokerEnum.REDIS))
def subtract(x, y):
result = x - y
print(f"Subtracting {y} from {x}: {result}")
return result
2.8.1.2.3 funboost文件:math_operations/multiply_function.py
from funboost import boost, BoosterParams, BrokerEnum
@boost(BoosterParams(queue_name='multiply_queue', broker_kind=BrokerEnum.REDIS))
def multiply(x, y):
result = x * y
print(f"Multiplying {x} and {y}: {result}")
return result
2.8.1.2.4 funboost文件:math_operations/divide_function.py
from funboost import boost, BoosterParams, BrokerEnum
@boost(BoosterParams(queue_name='divide_queue', broker_kind=BrokerEnum.REDIS))
def divide(x, y):
if y == 0:
print("Error: Division by zero")
return None
result = x / y
print(f"Dividing {x} by {y}: {result}")
return result
2.8.1.2.5 funboost文件:main.py
!!!funboost多种启动方式,普通脚本启动消费,以及命令行启动消费,都支持
能选择性启动某些消费函数,也能指定启动某些队列消费,也能启动所有消费函数,也能启动一组消费函数,也能多进程启动消费,还能远程启动消费,太强了
from math_operations.add_function import add
from math_operations.subtract_function import subtract # 这种显示的import导入ide能自动补全和检查,完爆celery的include声明一个模块路径字符串。
from math_operations.multiply_function import multiply
from math_operations.divide_function import divide
from funboost import ctrl_c_recv,BoostersManager
if __name__ == '__main__':
# 发布任务到消息队列
add.push(10, 5)
subtract.push(10, 5)
multiply.push(10, 5)
divide.push(10, 5)
# 下面是多种启动方式
## 第一种启动方式, 选择性启动消费(演示自由按需选择启动哪些函数)
add.consume()
subtract.consume()
multiply.consume()
divide.mp_consume(2) # 每个队列启动2个进程消费,性能强悍,破除gil
## 第二种启动方式,按分组启动消费者(演示consume_group按分组启动消费者)
# BoostersManager.consume_group($booster_group)
## 第三种启动方式,启动所有消费者(演示consume_all启动所有消费者,因为加减乘除模块都已经import进来了,所以可以直接启动所有消费者)
## 如果不想手动import导入消费函数所在模块,也可以使用自动扫描
# BoosterDiscovery(project_root_path,booster_dirs,max_depth,py_file_re_str).auto_discovery()
# BoostersManager.consume_all()
## 第四种启动方式,启动所有消费者,n个进程消费,性能炸裂(演示mp_consume_all启动所有消费者,一共运行8个进程)
# BoostersManager.mp_consume_all(8)
## 第五种启动方式,funboost 也能像celery那样,支持命令行操作启动消费
# python funboost_cli_user.py consume add_queue subtract_queue
## 第六种启动消费方式,funboost内置远程部署启动消费函数,你可以win的pycharm启动脚本,但是linux执行消费函数。
# multiply.fabric_deploy(host, port, user, password,python_interpreter='/data/venv/py39/bin/python3',)
# 阻止主线程退出,保持主线程一直在运行,
# (如果使用了定时任务或者演示任务,需要这样,因为apscheduler的BackgroundScheduler定时器必须确保主线程一直在运行)
ctrl_c_recv()
2.8.1.3 Funboost 运行说明
确保Redis服务器运行在默认地址(localhost:6379)。
执行
python main.py即可同时发布任务和启动消费者。无需任何额外配置:每个函数通过装饰器独立配置队列,无需中心化配置。
2.8.2 Celery 项目演示(复杂配置)
2.8.2.1 celery项目文件树
!!! celery在复杂多层级目录,不规则代码文件名字的项目下,太难使用了
实际项目比这演示的项目结构还复杂,更是难用,直接劝退新手
project_celery/
├── celery_config/
│ ├── __init__.py
│ ├── celery_app.py
│ └── celery_config.py
├── math_operations/
│ ├── __init__.py
│ ├── add_function.py
│ ├── subtract_function.py
│ ├── multiply_function.py
│ └── divide_function.py
├── main.py
└── start_worker.py
2.8.2.2 Celery代码文件内容
2.8.2.2.1 文件:celery_config/celery_config.py - Celery复杂配置示例
!!!太恶心了这个celery配置文件,对新手很困难,对老手很麻烦,尤其是路由配置
# Celery配置需要单独的文件,定义任务路由、队列等
from kombu import Queue
# 定义任务路由规则
task_routes = {
'math_operations.add_function.add': {'queue': 'add_queue'},
'math_operations.subtract_function.subtract': {'queue': 'subtract_queue'},
'math_operations.multiply_function.multiply': {'queue': 'multiply_queue'},
'math_operations.divide_function.divide': {'queue': 'divide_queue'},
}
# 定义任务队列
task_queues = (
Queue('add_queue', routing_key='add_queue'),
Queue('subtract_queue', routing_key='subtract_queue'),
Queue('multiply_queue', routing_key='multiply_queue'),
Queue('divide_queue', routing_key='divide_queue'),
)
# 定义任务序列化方式等
task_serializer = 'json'
accept_content = ['json']
result_serializer = 'json'
timezone = 'Asia/Shanghai'
enable_utc = True
2.8.2.2.2 文件:celery_config/celery_app.py - Celery应用实例配置
!!! app.conf.include极其恶心,用户随意移动python任务文件或者改名字,就会导致运行报错,ide无法静态检查include路径字符串
celery是@app.task,所以celery要你写烦人的include imports 配置。
from celery import Celery
from celery_config.celery_config import task_routes, task_queues
# 创建Celery应用实例(中心化配置)
app = Celery('celery_project')
# 加载配置
app.config_from_object('celery_config.celery_config')
# 必须明确指定要包含的任务模块(include参数)
app.conf.include = [
'math_operations.add_function', # 太难用,字符串写错就完蛋了。
'math_operations.subtract_function',
'math_operations.multiply_function',
'math_operations.divide_function'
]
# 配置任务路由和队列
app.conf.task_routes = task_routes
app.conf.task_queues = task_queues
# 其他必要配置
app.conf.broker_url = 'redis://localhost:6379/0'
app.conf.result_backend = 'redis://localhost:6379/0'
app.conf.task_serializer = 'json'
app.conf.accept_content = ['json']
app.conf.result_serializer = 'json'
2.8.2.2.3 文件:math_operations/add_function.py
!!!celery的任务文件,需要导入app,funboost不需要,这个小区别,带来巨大使用便利性差别
from celery_config.celery_app import app
@app.task
def add(x, y):
result = x + y
print(f"Adding {x} and {y}: {result}")
return result
2.8.2.2.4 文件:math_operations/subtract_function.py
from celery_config.celery_app import app
@app.task
def subtract(x, y):
result = x - y
print(f"Subtracting {y} from {x}: {result}")
return result
2.8.2.2.5 文件:math_operations/multiply_function.py
from celery_config.celery_app import app
@app.task
def multiply(x, y):
result = x * y
print(f"Multiplying {x} and {y}: {result}")
return result
2.8.2.2.6 文件:math_operations/divide_function.py
from celery_config.celery_app import app
@app.task
def divide(x, y):
if y == 0:
print("Error: Division by zero")
return None
result = x / y
print(f"Dividing {x} by {y}: {result}")
return result
2.8.2.2.7 文件:main.py - 发布任务
celery的func.delay 和 funboost的func.push 打个平手,但delay是延迟的意思,会误导不了解python celery的it技术总监。
from math_operations.add_function import add
from math_operations.subtract_function import subtract
from math_operations.multiply_function import multiply
from math_operations.divide_function import divide
if __name__ == '__main__':
# 发布任务到消息队列
add.delay(10, 5)
subtract.delay(10, 5)
multiply.delay(10, 5)
divide.delay(10, 5)
print("Tasks published to Celery.")
print("Now you need to start the worker separately with: python start_worker.py")
2.8.2.2.8 文件:start_worker.py - 启动Worker的复杂命令
celery的worker启动命令太复杂,不能代码自动补全,需要去百度 google搜索能传什么参数。**
#!/usr/bin/env python3
"""
启动Celery worker的复杂方式
需要指定所有配置参数
"""
import subprocess
import sys
def start_celery_worker():
# Celery启动worker需要复杂的命令行参数
cmd = [
sys.executable, '-m', 'celery',
'-A', 'celery_config.celery_app', # 指定Celery app
'worker',
'--loglevel=info',
'--queues=add_queue,subtract_queue,multiply_queue,divide_queue', # 必须明确指定监听的队列
'--concurrency=4', # 并发数
'--hostname=worker1@%h' # worker名称
]
print("Starting Celery worker with command:")
print(' '.join(cmd))
subprocess.run(cmd)
if __name__ == '__main__':
start_celery_worker()
2.8.2.3 Celery 运行说明
复杂配置步骤:
必须创建单独的配置文件定义
task_routes和task_queues必须明确指定
include参数包含所有任务模块必须配置序列化方式、时区等额外参数
启动复杂性:
先运行
python main.py发布任务然后单独运行
python start_worker.py启动workerworker必须明确指定要监听的队列名称
项目结构约束:
所有任务必须从同一个app实例导入
任务模块路径必须与include配置匹配
路由配置必须与队列定义一致
2.8.3 对比总结:哪个框架更容易使用?
2.8.3.1 Celery 配置复杂性突出体现:
1. include配置复杂性:
必须明确列出所有任务模块路径:
app.conf.include = ['math_operations.add_function', ...]新增任务时必须更新include配置
路径错误会导致任务无法注册
2. task_routes配置复杂性:
需要为每个任务手动配置路由规则:
'math_operations.add_function.add': {'queue': 'add_queue'}路由规则必须与任务名称完全匹配
复杂的正则表达式路由增加学习成本
3. task_queues配置复杂性:
必须显式定义每个队列:
Queue('add_queue', routing_key='add_queue')需要理解Kombu的Queue、Exchange、Binding概念
配置错误会导致消息无法正确路由
4. 中心化配置约束:
所有配置集中在app实例中
项目结构受框架约束
配置错误影响整个应用
2.8.3.2 Funboost 简洁性体现:
零配置:每个函数独立配置,无需中心化配置
自动发现:无需include配置,import消费函数所在python模块后,装饰器自动注册任务
直接队列管理:装饰器参数直接定义队列,无需路由配置
代码内启动:无需复杂命令行参数
2.8.3.3 结论
Funboost 明显更容易使用,主要体现在:
对比项 |
Funboost |
Celery |
|---|---|---|
配置简洁性 |
只需装饰器参数 |
需要多文件复杂配置 |
开发效率 |
即时测试 |
需要完整配置才能运行 |
维护成本 |
模块独立 |
配置集中易出错 |
学习曲线 |
API直观 |
需要掌握复杂概念 |
Funboost的"非侵入性"和"去中心化"设计避免了Celery的"奴役式"框架约束,真正实现了"简单即是正义"的开发体验。
结论:这不仅仅是代码量的差异,更是开发范式的代差
Celery 像是在“填表”:你需要在一个个配置文件、路由表、Include 列表中填写字符串,任何一个标点符号错了,程序都跑不起来。
Funboost 像是在“写 Python”:一切都是对象、函数、引用。IDE 能帮你补全,解释器能帮你检查。
Funboost 把复杂留给了框架作者(我),把简单留给了用户(你)。
2.8.3.4 说明,celery有稍微简单不爱出错的方式
例如 @app.task指定name , 配置路由时候,就不需要使用不靠谱的任务路径字符串作为任务的name ,但我这是官方最推荐的教程的,一般celery新手都是这种麻烦写法。
2.9 funboost到底为什么性能比celery高几十倍?太离谱了,太假了是吗?
你自己随便写写,性能都能完爆celery性能:
首先是celery性能实在太差,不信的话,你自己也可以写个简陋版的
while True:msg=redis.blpop(),
把msg丢到线程池执行,你会发现你随便写的代码,性能也狂秒celery 5-10倍,
我丝毫不怀疑你花5分钟随便写写,你都有这个吊打celery性能一个数量级的实力。
celery性能为什么差?
1. celery 超重的kombu 兼容转换层,只要用kombu性能就比直接操作各种原生mq三方包降低一大截
2. celery 的调用机制,从消息队列取出消息后到真正运行你的任务函数逻辑,经过了几十层级调用链路和把你的函数task层层包装。
funboost性能为什么高那么多?
1. funboost 没有kombu 兼容转换层,直接操作各种原生mq三方包
2. funboost 的调用机制,从消息队列取出消息后到真正运行你的任务函数逻辑,只有3层调用。
3. funboost 对性能精益求精,对于cpu耗时超过1微妙的对象或变量,尽可能想办法优化,换方式实现或者全流程尽量复用对象。
例如,你可以看看funboost如何应对高频生成发布消息中的时间字符串的,funboost序列化是不是使用原生json的,是不是尽量少频繁生成新的变量,是不是全手写自研并发池,等等
2.20 funboost 比 celery 的战略优势和 战术优势
2.20.1 一、 战略优势 (Strategic Advantages)
—— 决定了系统的上限、灵活性和演进方向
2.20.1.1 架构定位:FaaS 微服务平台 vs 传统任务队列
Celery: 是一个后台任务队列。它的边界很窄,只能做异步处理。外部系统想调用 Celery 的能力,通常需要隔着数据库或者自己再写一套 Web API 层。
Funboost: 是一个自带 FaaS 能力的计算平台。通过
funboost.faas,任何消费函数瞬间变成标准的能自动发现的 HTTP 微服务接口。战略价值: 打通了 Web 在线业务与后台离线业务的任督二脉。Java/Go/前端可以直接通过 HTTP 调用 Python 的业务函数,实现了**“写完函数即发布服务”**的云原生体验。
2.20.1.2 设计哲学:自由赋能 vs 框架奴役
Celery: “集权式”设计。强依赖中心化的
app实例,强制要求特定的项目目录结构(celery.py,tasks.py),配置分散且晦涩。你的代码必须“适配”框架。Funboost: “联邦式”设计。去中心化,每一个
@boost函数都是独立的个体。对代码零侵入,不限制目录结构,不需要app实例。你的代码保持原样,框架为你“赋能”。战略价值: 极大地降低了接入成本和维护成本,老旧项目也能通过一行代码瞬间拥有分布式能力。
2.20.1.3 兼容性格局:万物皆 Broker vs 依赖 Kombu
Celery: 深度绑定
Kombu库。只能使用 Kombu 支持的中间件,且对 Redis 的支持存在历史遗留的可靠性问题(Visibility Timeout 机制)。Funboost: 实现了Broker 层的完全抽象与解耦。
它不仅支持所有主流 MQ(RabbitMQ, Kafka, RocketMQ, NATS, Pulsar)。
它还支持非标准 Broker:数据库(MySQL, MongoDB)、文件系统、Socket、甚至 MySQL CDC (Binlog)。
它甚至能吞噬其他框架:可以直接将 Celery、Dramatiq 作为底层的 Broker 驱动。
战略价值: 无论基础设施如何变迁,Funboost 都能以逸待劳,甚至可以作为事件驱动架构(EDA)的核心(基于 CDC)。
2.20.1.4 技术栈前瞻性:原生 Asyncio vs 伪异步
Celery: 诞生于同步时代,对
asyncio的支持是“打补丁”式的,通常需要在同步 worker 中运行 event loop,性能和编程模型都很别扭。Funboost: 拥有全链路的 Native Asyncio 支持。从消费(
async def)、发布(aio_publish)到 RPC 获取结果(AioAsyncResult),完美契合 FastAPI 等现代异步生态。
2.20.2 二、 战术优势 (Tactical Advantages)
—— 决定了开发的爽快度、运行的稳定性和性能的极致度
2.20.2.1 性能表现:多维叠加并发 vs 单一模式
Celery: 并发模式通常互斥(要么多进程,要么 Gevent)。单机性能受限。
Funboost: 支持 “多进程 + (多线程/协程)” 的叠加并发模式。
实测发布性能是 Celery 的 22倍,消费性能是 46倍。
战术价值: 能在同样的硬件资源下,榨干 CPU 和 IO 性能,大幅降低服务器成本。
2.20.2.2 控频能力:精准令牌桶 vs 模糊限制
Celery:
rate_limit是基于 Worker 的,且精度较差。在分布式环境下,无法精确控制全局的总 QPS。Funboost:
单机: 实现了精准的 QPS 控制(无视函数耗时波动)。
分布式: 支持全局分布式控频(基于 Redis 协调),确保多台机器加起来的总速率不超标(保护下游接口)。
2.20.2.3 可靠性:心跳 ACK vs 超时重发
Celery (Redis): 使用
Visibility Timeout机制。如果任务耗时超过超时时间,任务会被错误地重新分发,导致重复执行;如果设置太长,Worker 崩溃后任务恢复极慢。Funboost (Redis): 实现了基于 消费者心跳 (Heartbeat) 的 ACK 机制。精准识别 Worker 是否存活,死掉的 Worker 任务会被立即回收,而长耗时的任务不会被误判。随意 Kill 进程不丢数据。
2.20.2.4 开发体验:IDE 友好 vs 字符串魔法
Celery: 大量依赖字符串配置(如
'json','redis://') 和动态参数(*args,**kwargs),IDE 无法补全,容易写错。Funboost: 使用 Pydantic 模型 (
BoosterParams) 进行配置。在 PyCharm/VSCode 中拥有完美的代码补全和类型检查。写代码就像填表一样简单且不易出错。
2.20.2.5 运维能力:内置可视化 vs 第三方插件
Celery: 需要额外部署
Flower,功能相对基础。Funboost: 内置 Funboost Web Manager。
无需额外部署,代码一行启动。
不仅能看,还能管:支持远程暂停/恢复消费、远程动态调整 QPS、远程调整并发数。
支持 远程代码热部署 (Fabric Deploy),一行代码将函数分发到远程服务器运行。
2.20.3 总结
Funboost 不是在造 Celery 的轮子,而是在造 Celery 的“掘墓人”。
如果你需要一个稳重、传统的纯后台任务系统,Celery 是“够用”的。
如果你追求极致性能、开发效率、微服务架构以及对 Python 异步生态的完美融合,Funboost 是具有代差优势的选择。